rack-dev_insightの紹介:Rackアプリケーションの機能とデータの依存関係を可視化する開発ツール
概要
本記事では、私が作成したrack-dev_insightというgemとchrome extensionで構成された開発ツールの紹介をしたいと思います。
Rack (Rails) アプリケーションにgemをインストールすると、SQLクエリとHTTPリクエストのトレースが自動で行われ、その解析結果がchrome devtoolsのパネルに表示されます。
rack-dev_insightの目的は、複雑なアプリケーションにおける機能とデータの依存関係の把握を手助けすることであり、具体的にはCRUDマトリクスの自動生成やHTTPリクエスト情報の表示ができる点が特徴となっています。
デモ
rack-dev_insightの大まかな操作感は以下の動画をご覧ください。詳細な説明は以降のセクションに記載しています。
開発に至るまでの経緯
問題意識
私の経験上、多くのデータ(RDBMSのテーブルなど)が関わる複雑な機能を持つようなアプリケーションでは、機能改修を行う際に影響範囲を把握することが難しいと感じることが多くありました。
大きく分類すると、以下のような問題を感じていました。
- ある機能の改修を行う際に、要件定義や設計段階で、その機能にどのようなデータがどう関わるのかを把握するのが難しい
- あるテーブルの定義を変更した際に、どの機能に影響があるのかを把握するのが難しい
これによって、要件定義工数の増加や考慮漏れによる手戻りの発生に繋がることは、多くのアプリケーションで共通する問題ではないかと考え、これを上手く解決する方法を作り出せれば、多くの開発者の助けになるかもしれないと思いました。
どう考えたか
上記のような問題を解決するためには、理想的には、あらゆる機能とデータの依存関係が把握できる状態にすることで、要件定義や設計段階で影響範囲を網羅できるようにすることが望ましいと考えました。
このようなシステムの情報をモデリングするツールには、UML図(データフロー図、シーケンス図、状態遷移図、アクティビティ図など)やER図などがあると思います。
これらのツールは上手く活用すればとても役立つと思いますが、一方で実際に運用する上では以下のような問題点を感じていました。
- 手動管理によって追加工数が取られたり、ミスが生じたり、情報が陳腐化して使われなくなっていくこと。
- 要件定義や設計時においてあまり実用的でない抽象的な概念図になってしまうこと。逆に詳細を記述しすぎて、それならばコードを読んだ方が早いということになること。
特定の複雑な機能に関しては、手作業だとしても詳細な状態遷移図やデータフロー図等を作成することは有用だと考えており、実際に行ったことも多くありますが、全ての機能に対してこれを行うのは現実的ではないと感じていました。
すなわち、
- 自動生成による工数削減と信頼性(網羅的・人為的なミスがない・最新版であること)の担保
- 設計時に役立つ適切な抽象度の情報
を満たすことが重要だと考えました。
解決策
自動生成を行うためには、システムから情報を集める必要があり、その方法には大きく分けて「静的解析」と「動的解析」があると考えられます。
「静的解析 」の観点では、例えばデータベース定義からER図を自動生成することができます。これは既存のツールも多く存在しますし、カスタマイズできるように自前でツールを作成しプロジェクトに導入したこともあります。
「動的解析」の観点では、例えばAPMツールにおいてデータベースや別サービスとの通信をトレースできることができ、ここに着想を得て、SQLやHTTPリクエスト情報を元にすることで、有益な情報をモデリングできるツールを作成できないかと考えました。
そして、SQLパーサーを用いたテーブルとCRUD操作の抽出の発想に至り、これは設計時において十分有益な情報となると考え、rack-dev_insightとして本格的に開発することにしました。
rack-dev_insightで実現できること
CRUDマトリクスの自動生成による機能とデータの依存関係の把握
rack-dev_insightは、ブラウザからのHTTPリクエスト単位でCRUDマトリクスを自動生成することができます。
CRUDマトリクスとは、縦軸にビジネスプロセス(ある操作や機能)、横軸にリソース(RDBMSのテーブルなど)、セルにリソースに対するCRUD操作(CREATE, READ, DELETE, UPDATE)を記述した表のことです[1]。
rack-dev_insightでは、(今後拡張していく予定ですが)現状は以下のような形でCRUDマトリクスを表示します。
- ビジネスプロセス:ブラウザからのHTTPリクエスト
- リソース:RDBMSのテーブル
- セル:CRUD操作
これよって、機能ごとにどのテーブルにどのようなCRUD操作が行われているのかを網羅的に表示できるため、機能とデータの依存関係を把握することができます。
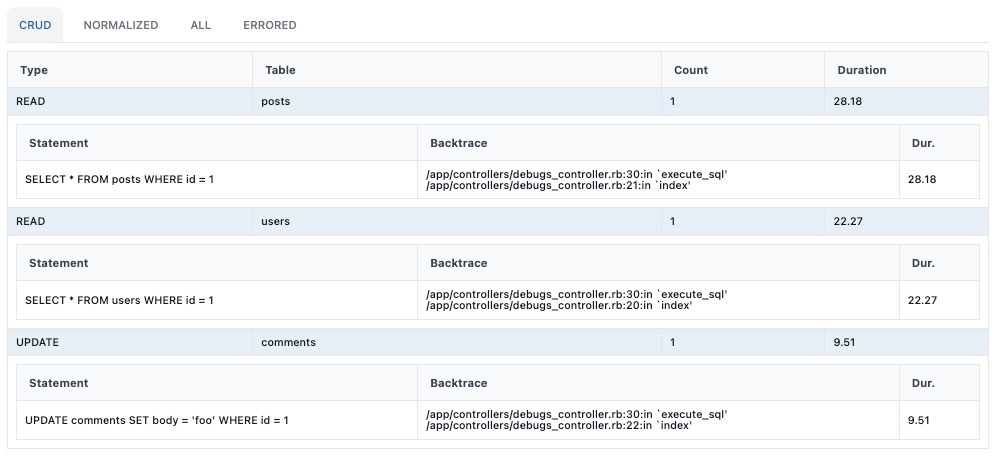
シンプルな例として、ユーザーが投稿のコメントを更新するというビジネスプロセスを考えると、usersおよびpostsテーブルからのデータの読み取りと、commentsテーブルの更新が行われ、この場合のCRUDマトリクスは次のようになります。
| Business Process \ Resource | users | posts | comments |
|---|---|---|---|
| Update a comment | READ | READ | UPDATE |
このケースでは、rack-dev_insightのDevtoolsパネルでは、以下のような形でCRUDマトリクスが表示されます。各行をクリックすることで、そのCRUD操作を実行したSQL一覧を表示することができます。
HTTPリクエストのトレースによる外部システムとの依存関係の把握
アプリケーションから実行されたHTTPリクエスト/レスポンスデータを記録することで、Web APIを経由した外部サービスとの依存関係を把握することができます。
Devtoolsパネルでは、以下のように表示されます。
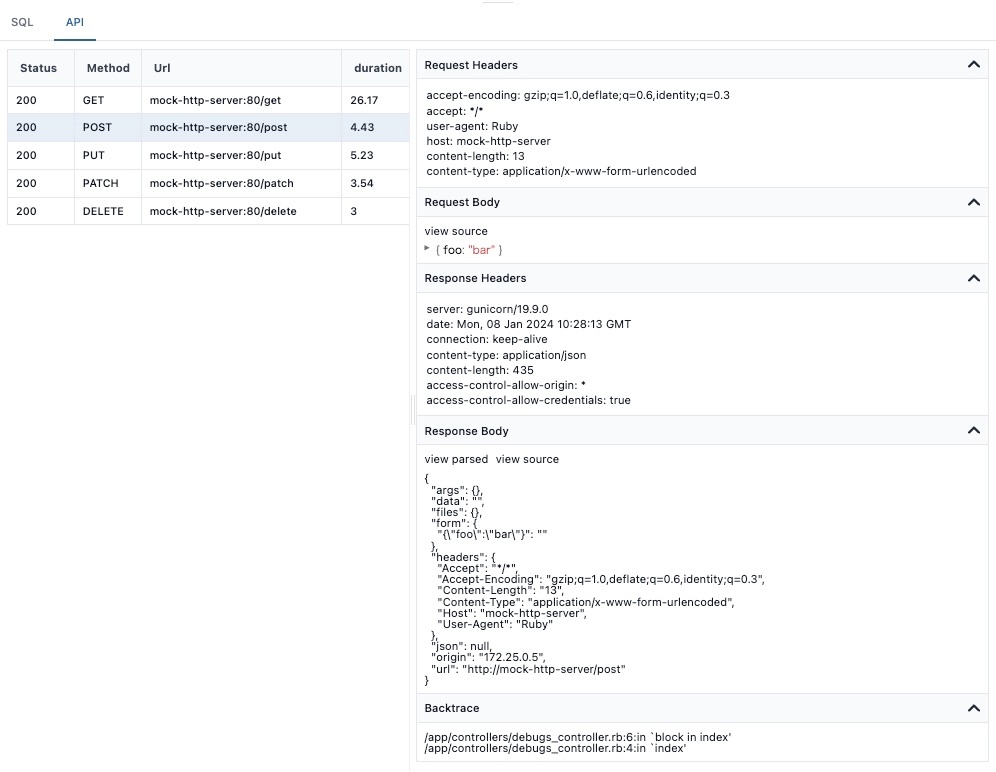
現状はnet-http gemを用いたリクエストのみを対象としていますが、今後は他のHTTPクライアントや、GraphQL, gRPCなどのサポートも検討しています。
エディタ連携によるソースコード調査の容易化
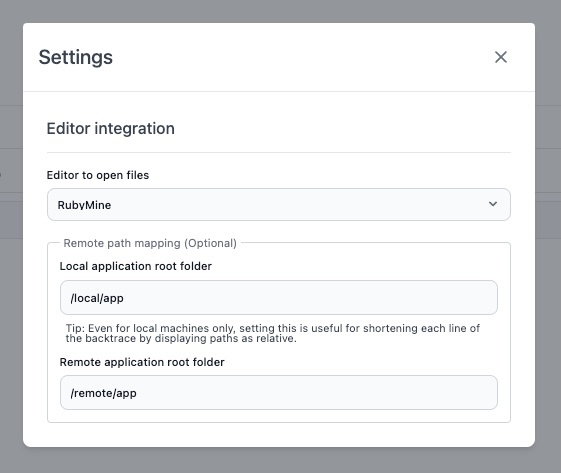
rack-dev_insightでは、SQLクエリやHTTPリクエストの発行箇所のバックトレースを収集しているため、ソースコードを読んでさらに詳細な調査を行う際の手助けをすることができます。
また、各種エディタとの連携設定をすることで、バックトレースのパスがLink化され、クリックしてエディタを開くことができるため、より容易にソースコードの調査が行えます。
エディタとアプリケーションプロセスが別マシンで動作している場合を想定して、それぞれのパスの対応関係を設定することもできます。
Normalized SQLによるN+1クエリ検出(+α機能)
「機能とデータの依存関係の把握」という趣旨とは異なる+α機能ですが、とても役立ちそうだと思ったためSQLクエリの正規化(Normalization)によるN+1クエリ検出機能も実装しました。
SQLの正規化とは、基本的にはSQLの主にリテラル部分などを抽象表現に変換することを意味します。pt-fingerprintと概ね同様の方法で正規化しています。
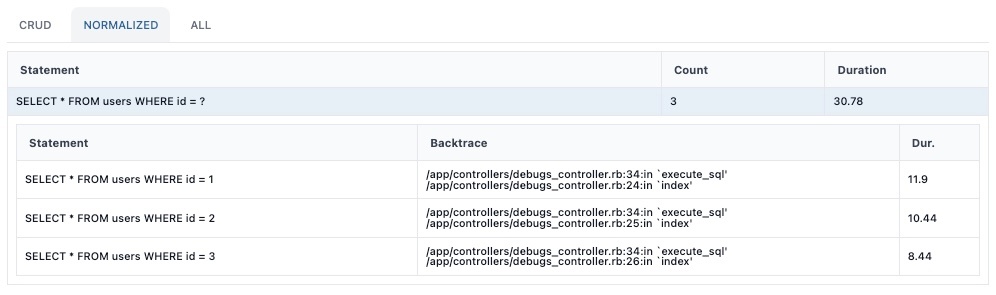
例えば、以下のSQLクエリを考えると、
SELECT * FROM users WHERE id = 1
SELECT * FROM users WHERE id = 2
SELECT * FROM users WHERE id = 3
これらは全て以下の同一フォーマットに正規化されます。
SELECT * FROM users WHERE id = ?
Devtoolsパネルでは、同一フォーマットに正規化されたSQLクエリがグルーピングされ、以下のように表示されます。
また、DMLも同様に正規化することができます。
INSERT INTO users (name) VALUES (?)
UPDATE users SET name = ? WHERE id = ?
DELETE FROM users WHERE id = ?
N+1の検出ツールとして有名なものにはbullet gemがありますが、このSQL正規化の方法ではSQLの構造だけに着目するため、bullet gemでも検知されないような(広義の)N+1クエリ[2]も把握することができます。
また、DMLにおける同一構造のクエリの発行数や合計実行時間を把握できる点も大きなメリットだと考えており、bulk insertやbulk updateなどの最適化の検討にも役立つと考えています。
Future Work
rack-dev_insightはまだ発展途上であり、今後の展望としては以下のような機能実装を考えています。
- RDBMSにおける他のSQL方言のサポート(Microsoft SQL Serverなど)
- NoSQLデータベースのサポート
- net-http以外のHTTPクライアントや、GraphQL, gRPCのサポート
- Normalization方法の追加オプション
- 部分的なトレースのサポート
- 現在はリクエスト単位でしかトレースできませんが、ブロックで囲った特定の範囲のみをトレースする機能を実装する予定です。これにより、より細かい範囲で機能とデータの依存関係を把握することができます。
# 実装予定のコードイメージ Rack::DevInsight.trace do # トレースの対象範囲 end
- 現在はリクエスト単位でしかトレースできませんが、ブロックで囲った特定の範囲のみをトレースする機能を実装する予定です。これにより、より細かい範囲で機能とデータの依存関係を把握することができます。
- リモートマシンでのトレースデータの収集
- 現状は単一のアプリケーション(ブラウザからアクセスされるアプリケーションサーバーのプロセス)でのトレースデータの収集のみが可能ですが、マイクロサービス構成など、複数のプロセスでのトレースデータの収集も可能にすることを視野に入れています。
- 現状は、ActiveJob等のバックグラウンドジョブのトレースは、perform_nowなどで同一プロセス(スレッド)内で実行することでトレースが可能です。
- プロダクション環境での運用
- rack-dev_insightは、現状はプロダクション環境での運用は想定していません(トレースデータへのアクセス制限やエラーハンドリング、パフォーマンスなどの考慮事項をクリアできていないため)。
- ただ、SQLからCRUDテーブルを抽出する機能は、sql-insight(またはsql-insight-rb)に切り出しているため、opentelemetryやdatadog等で本番のSQLトレースデータが収集できる場合は、sql-insightを用いてCRUDマトリクスを自動生成することは十分可能だと考えています。
技術選定や実装方針について
基本構成
- Rails Panelからの着想: gemとchrome devtoolsという組み合わせは、Rails Panelに着想を得ており、Rack middlewareの設計やEditor連携というアイデアも参考にさせてもらいました。
インストール設定
- rack-mini-profilerによるインストール方法の参考: (Railsだけでなく)Rackアプリケーション全体を対象としたデバッガーツールとして、rack-mini-profilerのインストール方法はとても勉強になりました。工夫点としては、大部分のユーザーはRailsを使用しているという想定の元、Railsアプリケーションにおいてはrailtieなどを用いてゼロコンフィグ動作を実現しつつ、他のRackアプリケーションでも容易に利用できるよう配慮しました。
SQLとHTTPのトレースの実装
- SQLのトレース方法は、Railsにおいては
ActiveSupport::Notificationsを用いており、その他のRackアプリケーションにおいては、データベースのクライアントライブラリにパッチを当てることでトレースしています。- パッチの実装においては、opentelemetryやdatadogにおけるContrib周りの実装も参考にさせてもらいました。
- また、今後部分的なトレースを実装するにあたり、opentelemetryなどの設計・実装方法が気になるためこれから勉強しようと考えています。
- HTTPのトレースも、net-http gemにパッチを当てることでトレースしています。今後他のHTTPクライアントや、GraphQL, gRPCに対するサポートを追加することを検討しています。
SQLパーサーライブラリの選定
- 複数のSQL方言を扱えるGenericなSQLパーサーの選定
- 多様なデータベースをサポートするために複数のSQL方言を扱えるGenericなSQLパーサーを調査したところ、JavaのJSqlParserやpythonのsqlparse、rustのsqlparser-rsが見つかりました。最も成熟しているのはJSqlParserでしたが、やはりJVM環境が必要な点やCRubyに上手く繋ぎ込めない点で候補から外し、発展途上ですがrustという魅力もありsqlparser-rsを採用しました。実際、方言特有の構文でサポートできていない部分があるため、私もコントリビュートしたりして徐々にサポート範囲を広げるよう頑張っているところです。
- 選定条件としては、パースしたASTをWalkするAPIが提供されていることもありましたが、sqlparser-rsはこれも満たしていました。
- ASTからCRUDテーブルを抽出するにあたり、ANSI/ISO SQL standardから文法規則を解読する時間が多かったですが、これはSQL構文の理解を深める良い機会だったと思います。標準のSQL構文と実際の有名なRDBMSのSQL構文が異なっている所が多い点もなかなか大変なポイントでした。
- また、Ruby gemでRust拡張を実装する方法についても結構苦労した点があるため、近日中に解説記事を書く予定です。
開発プロセスの効率化
- OpenAPIとモックサーバーの活用: サーバーとchrome devtools間でのWeb APIのスキーマはOpenAPIで定義し、Prismモックサーバーを使いつつ開発を進めました。
- サーバー側実装が未完成の段階でも、モックサーバーを使いつつフロント側の開発が進められる点は非常に便利でした。
- クライアント側のtypescriptの型定義をOpenAPIから生成できる点も便利でした。型定義の生成にはswagger-typescript-apiを用いましたが、openapi-generatorとは異なり一つのファイルにシンプルな型定義が生成されることや、オプションの豊富さがメリットだと思いました。
フロントエンド(chrome extension)の技術選定と課題
- フロントエンド(Chrome extension)はSvelteとtailwindcssを使用しました。
- Svelteの選定理由は、小規模なアプリケーションの場合は特にパフォーマンスが期待できたため(と一度使ってみたかったため)です。
- 公式Devtoolsがまだリリースされてない時期にDevtoolsなしで実装しましたが、規模が小さいこともありますが、ボイラープレートが少なくて済むことや、設計のシンプルさから開発体験はとても良かったと感じています。
- グローバルな状態管理ができるstoreが組み込みで用意されていますが、普段reduxを使っている経験上データフローが追いにくくなる点が懸念だったので、今回はstoreを使わずに実装しました。
- CSSフレームワークはtailwindcssを使用しました。理由は、スタイリングの選択肢に制限をかけられる点がOSSのようなプロジェクトでスタイルの統一性を保つ上で便利そうだと考えたため[3](と一度使ってみたかったため)です。
- UIコンポーネントライブラリとして、flowbite-svelteを使用しました。これはtailwindcssがベースとなっており、スタイリングや機能性が求めていたものに近かったことや、スタイルをカスタム指定するpropを外から自由に渡せる点が選定理由であり、実際に使用感は良かったです。
- Svelteとtailwindcssを用いてchrome extensionを作る上での良い方法や細かい実装の話は、近日中に別記事にまとめる予定です。
まとめ
本記事では、rack-dev_insightについて紹介しました。rack-dev_insightは、CRUDマトリクスの自動生成やHTTPリクエスト/レスポンスデータの記録と可視化によって、複雑なシステムにおける機能とデータの依存関係の把握を手助けすることができる開発ツールです。
もし良さそうだと思った方がいらっしゃれば、ぜひ使ってみてください!質問やフィードバック、コントリビューションなど何でも歓迎です!
-
例えば、Rails: Bulletで検出されないN+1クエリを解消するで紹介されているようなケース ↩︎
Discussion