Datadogのカスタムメトリクスによる予期せぬコスト増加を回避する
概要
- この記事は Datadog Advent Calendar 2021 10日目の記事です
- 数ヶ月前にカスタムメトリクスによる超過請求未遂をやった戒めです
この記事のターゲット
- Datadogを導入している方
- Datadog Logsを活用し始めた方
- Datadogの請求?そんなん見てないですわガハハという強者
あらすじ
とあるWebサービスではnginxとrailsのログをDatadog Logsに送信しており、大きく分けて2つの役割でDatadog Logsを活用しています。
1. ヘルスチェック
1つはサービスのヘルスチェックのためのユースケースで、Datadog Logsから重要なエンドポイント(会員登録、ログイン、決済など)へのアクセスログをカスタムメトリクスに登録して @http.status_code 別でウォッチできるようにしています。
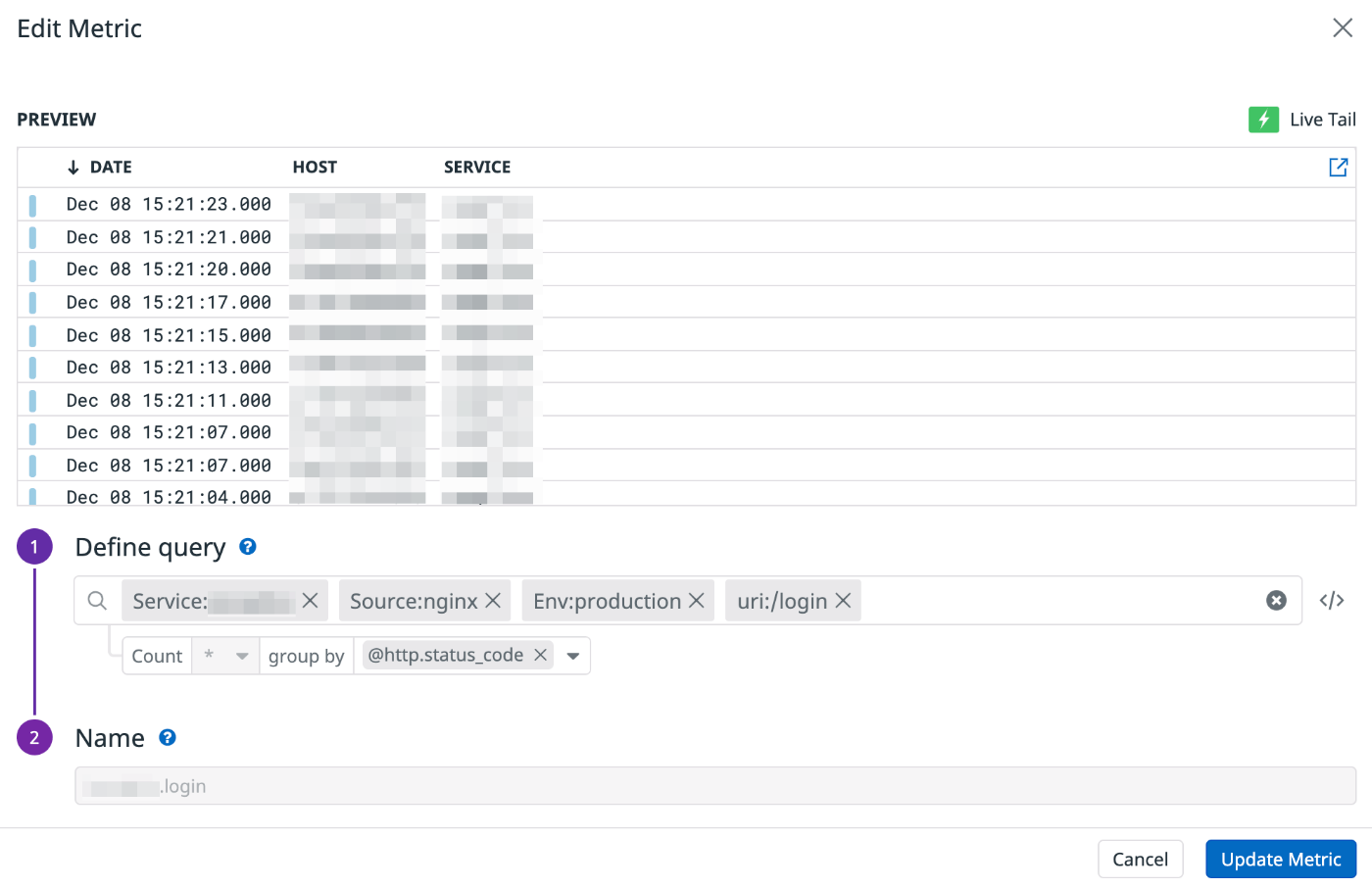
ログイン機能のカスタムメトリクス
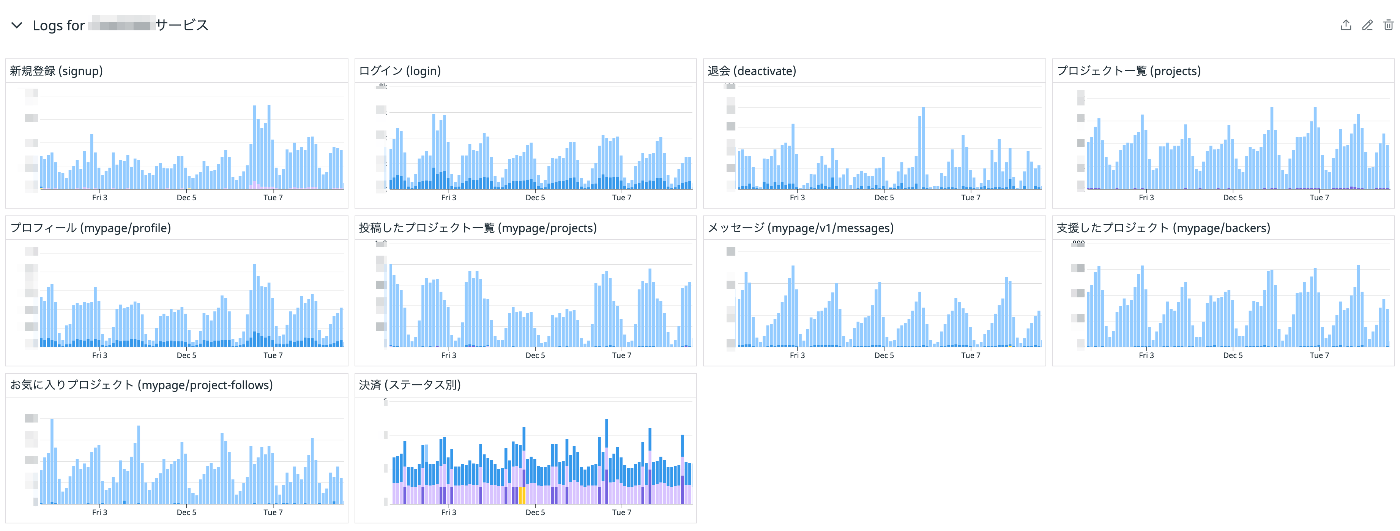
重要機能のメトリクス一覧
ダッシュボードからこのメトリクス一覧を眺めることでサービス全体のざっくりとしたヘルスチェックが可能となっています。
(本来であればメトリクスをSLI/SLOとして落とし込むのが正しいアプローチですが見逃して下さい)
2. トラブルシューティング
もう1つはトラブルシューティングのためのユースケースで、大量のスクレイピングや脆弱性を狙った不正アクセスなどがあった時の調査用としてもDatadog Logsを活用しています。
例えば、ALB 5XXのメトリクスが跳ねた時のアラートを確認し、Datadog Logsで詳細をすぐに確認するといった運用を行っています。コストとユースケースを考慮し、IndexのRetention Periodは最短の3daysに設定してあります。
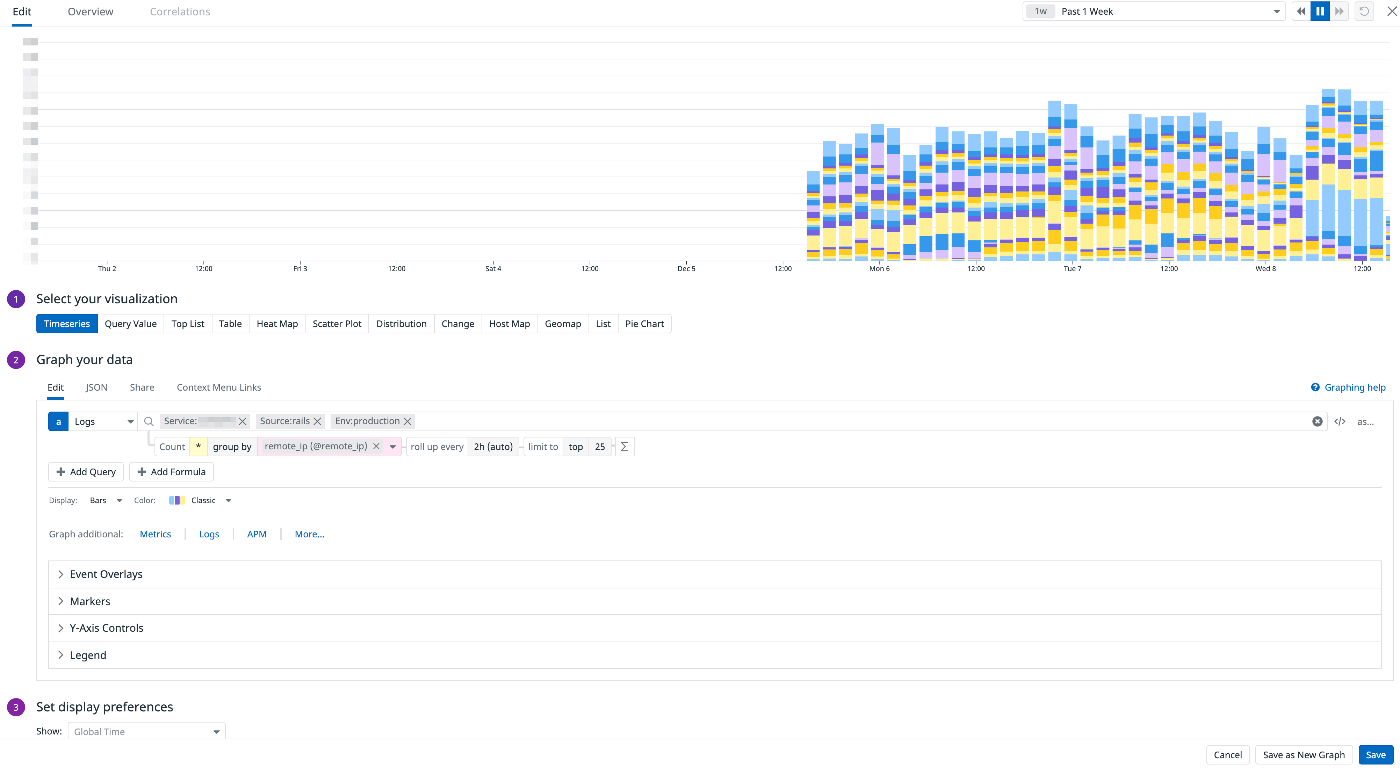
Logの可視化
「とりあえず何かあった時にこれを見ればわかるはず」といった名目から、調査用のためにアクセス元のremote_ip、referer、request_uri、user_agentのそれぞれのTop25をピックアップしてダッシュボードに表示してあります。

トラブルシューティング用のMetrics
本題
前述の通り、Datadog Logsはトラブルシューティングのユースケースでも使用しており、Indexされているログは直近3日間となっています。
しかし、「実は先週不審なアクセスがあって・・・」や「特定の曜日に大量のアクセスがくるので調査したい」といった事も発生しており、直近3日間という限りあるログから傾向を分析し対策を行うのが厳しく、後からでもちゃんと分析できるようにしたい欲が湧いてきました。
(当然ですが全てのログはS3に入っており、それをこねこねして分析することも可能です)
Datadog Logsのコスト試算
安易にRetention Periodを3daysから増やすとそこそこのコスト増加になってしまいます。
ここでDatadog Logsのオンデマンド時の料金体系を見てみましょう。
| 保持期間 | 月額料金 |
|---|---|
| 3日間 | $1.59 / 100万ログイベント |
| 7日間 | $1.91 / 100万ログイベント |
| 15日間 | $2.55 / 100万ログイベント |
| 30日間 | $3.75 / 100万ログイベント |
例えば、今扱っているサービスが1000万ログイベント/dayだったとします。
この規模のログを3日間Datadog LogsにIndexする場合はこのような計算になります。
$1.59/100万ログイベ * 1000万ログイベ/100万ログイベ * 30日 = $477/月
デフォルトの15日間の場合はこんな感じの計算になります。
$2.55/100万ログイベ * 1000万ログイベ/100万ログイベ * 30日 = $765/月
Datadog Logsだけで月$765は高いし困ったなぁと悩んでいた時に「せや、カスタムメトリクスに登録して分析すればええんや!」と閃いたのでした・・・💀
カスタムメトリクス
先日の記事でも触れましたが、Datadog Logsからカスタムメトリクスを生成することができます。
ログをカスタムメトリクスとして登録することでデータを15ヶ月間保持することが可能です。
私はこれを活用しようと考えました。
手始めにrailsのログからremote_ipを、nginxのログからreferer、request_uri、useragentをGroup Byでカスタムメトリクスに登録しようとしました。意図としてはこれらのラベル単位で集計して不正と思われるアクセス元を遮断したいというものです。
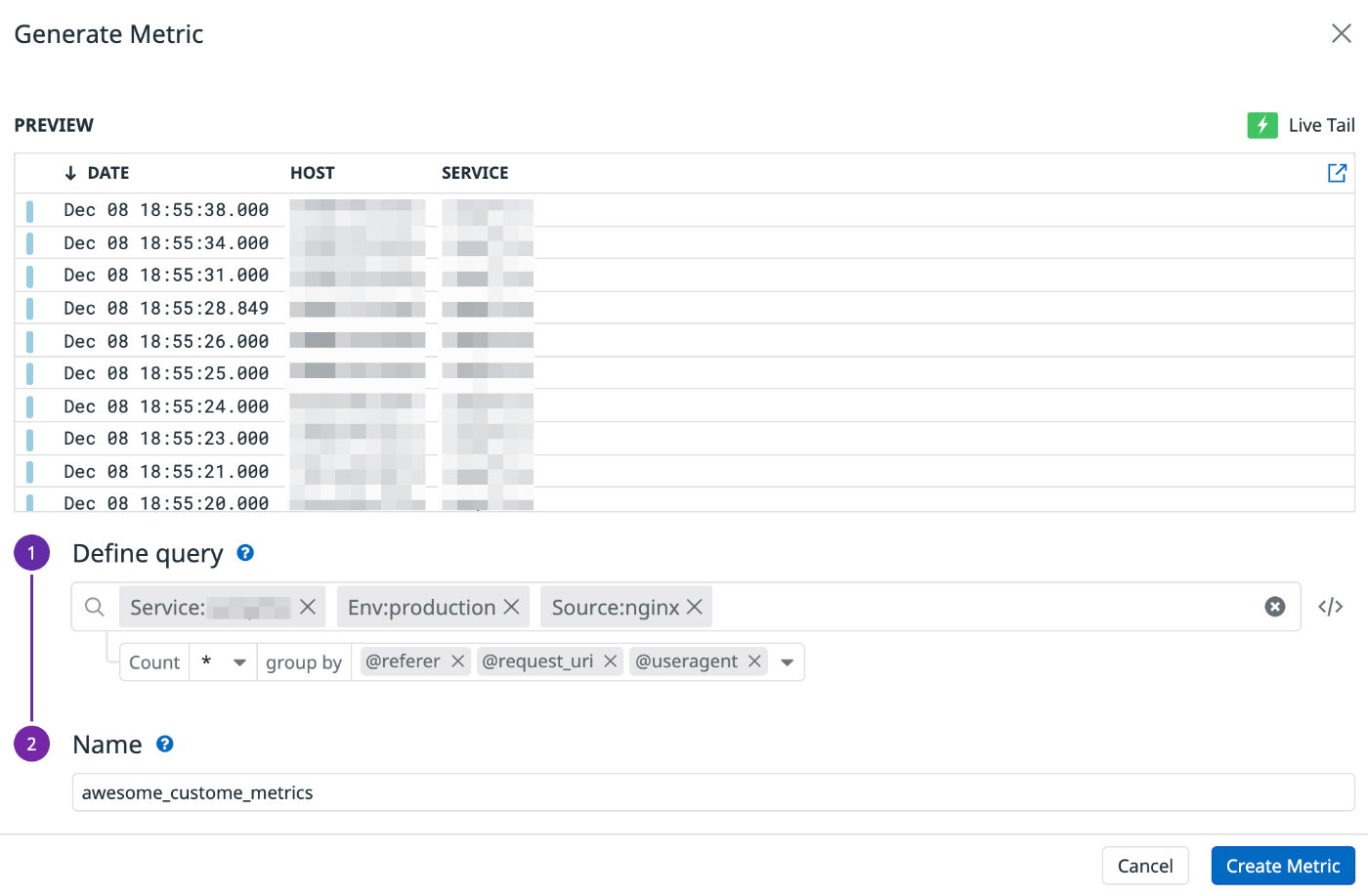
awesome custome metrics💀
冷静に考えてみるとrefererもrequest_uriもuseragentも非常に値のバリエーションが多いラベルです。DBで言うところのカーディナリティの高いデータってやつです。後日、私はとんでもないものを目撃してしまいました。
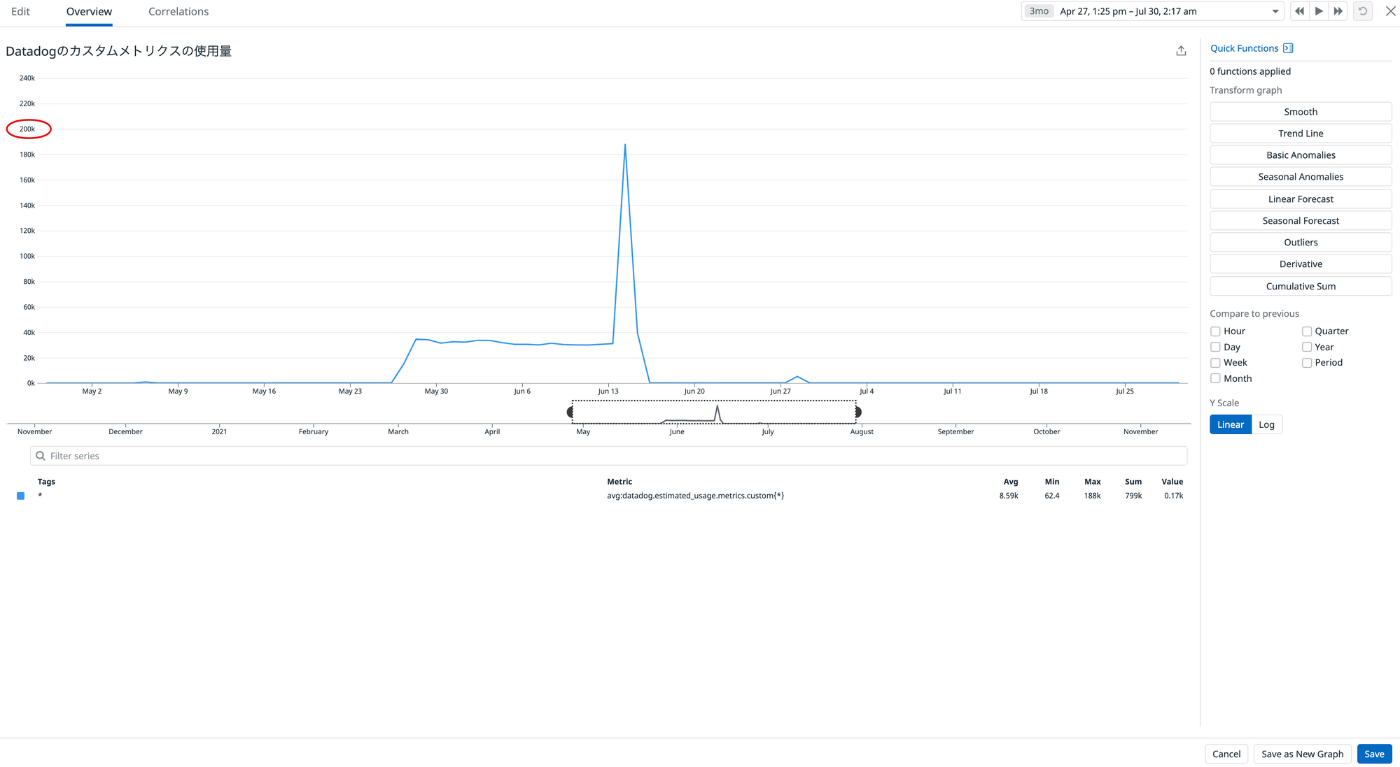
カスタムメトリクスの使用量
わァッ・・・
カスタムメトリクスの使用量がこんなになっちゃった・・・
なっちゃったからにはもう・・・ネ・・・
急いでDatadogのサポートに連絡しました。
私「すみません、間違ってカスタムメトリクスに大量のデータを登録してしまいました。」
サポート「まずは該当するカスタムメトリクスの設定を削除してください。」
私「承知しました。すぐに削除しました。」
サポート「設定が削除されたことを確認しました。既に登録されているカスタムメトリクスについてはサポートでは対応致しかねるため、担当営業の方から別途ご連絡します。」
私「承知しました(震え声)」
ということでDatadogの担当営業さんに色々と調整して頂きなんとか事なきを得ました。
その説はご迷惑をおかけしました🙇♀️ & 本当に助かりました🙇♀️
カスタムメトリクスの料金について
カスタムメトリクスの価格ですが、Proプランだと 100/ホスト となっています。
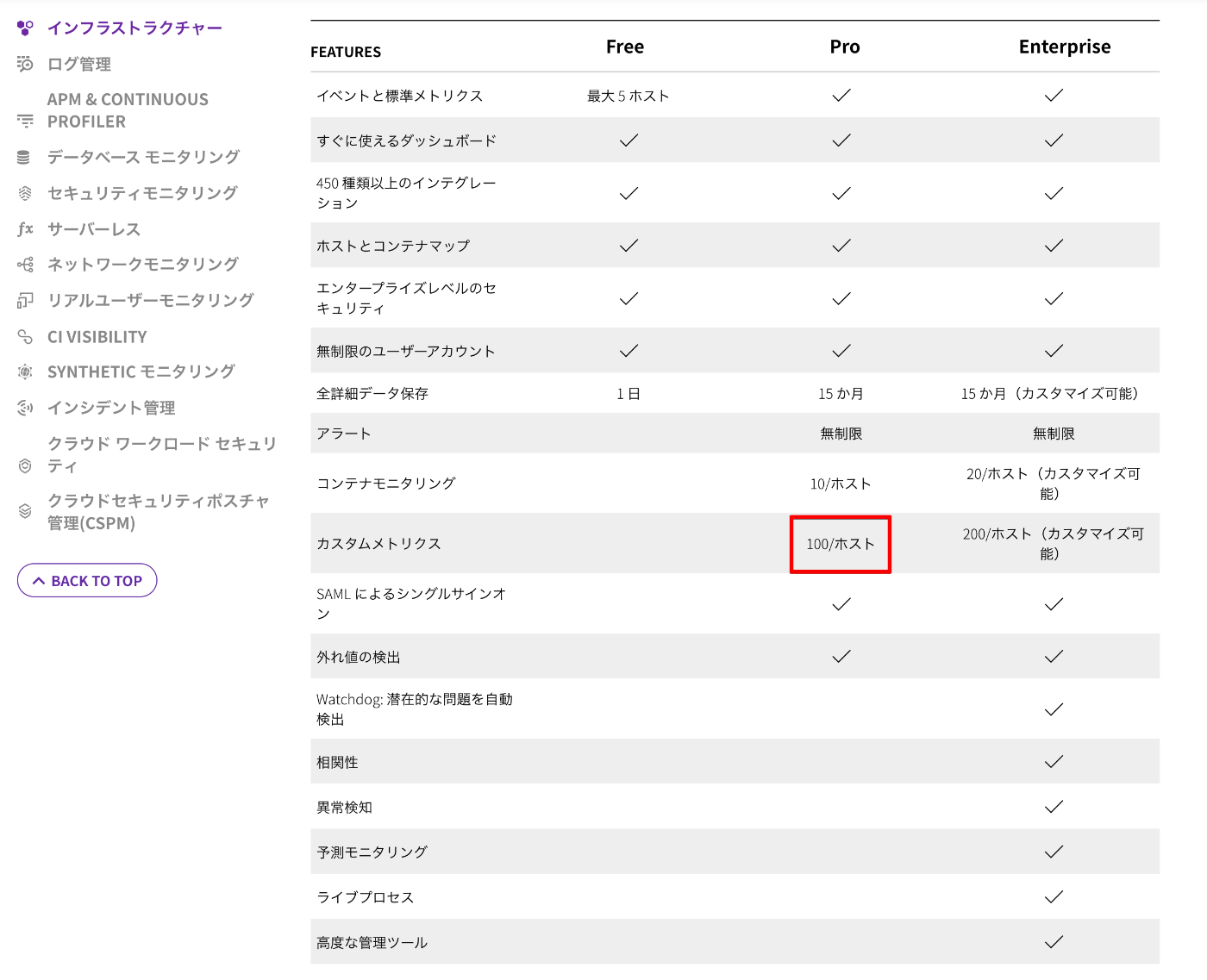
料金プラン(Infrastructure)
とあるWebサービスでは14ホスト/月を月間のコミットとして契約していたので、1.4k/月まではプラン内、それ以上は $5.00 per 100 custom metrics となります。
つまり、もしもカスタムメトリクスの設定ミスに気づかず放置していた場合は最悪
$5 * 200,000/100 = $10,000 の請求になる可能性がありました。休止に一生です。
今回の原因
私がカスタムメトリクスとその料金について全く把握できていなかった事が原因です。
というのも、Datadog導入時のコスト試算も私がしていたのですが、その時は「Datadogの料金はInfrastructure・APM・Logsが大半なのでそこさえ気をつけておけば良い」という認識をしており、カスタムメトリクスについてはほとんど確認していませんでした。
今回の問題が発生する以前に設定したカスタムメトリクスはカウント数が少なくてプラン内の範囲で収まっており、毎月の請求を確認した際に違和感を覚えたりすることもありませんでした。今回の問題が発生するまで超過分の金額の高さに気づけていなかったのです。
今後の対策
Datadogには推定使用量メトリクスというものがあります。
カスタムメトリクスの推定使用量はavg:datadog.estimated_usage.metrics.custom{*} で取得することができるため、すぐにダッシュボードにメトリクスを追加して毎週もしくは必要に応じて確認するようにしました。
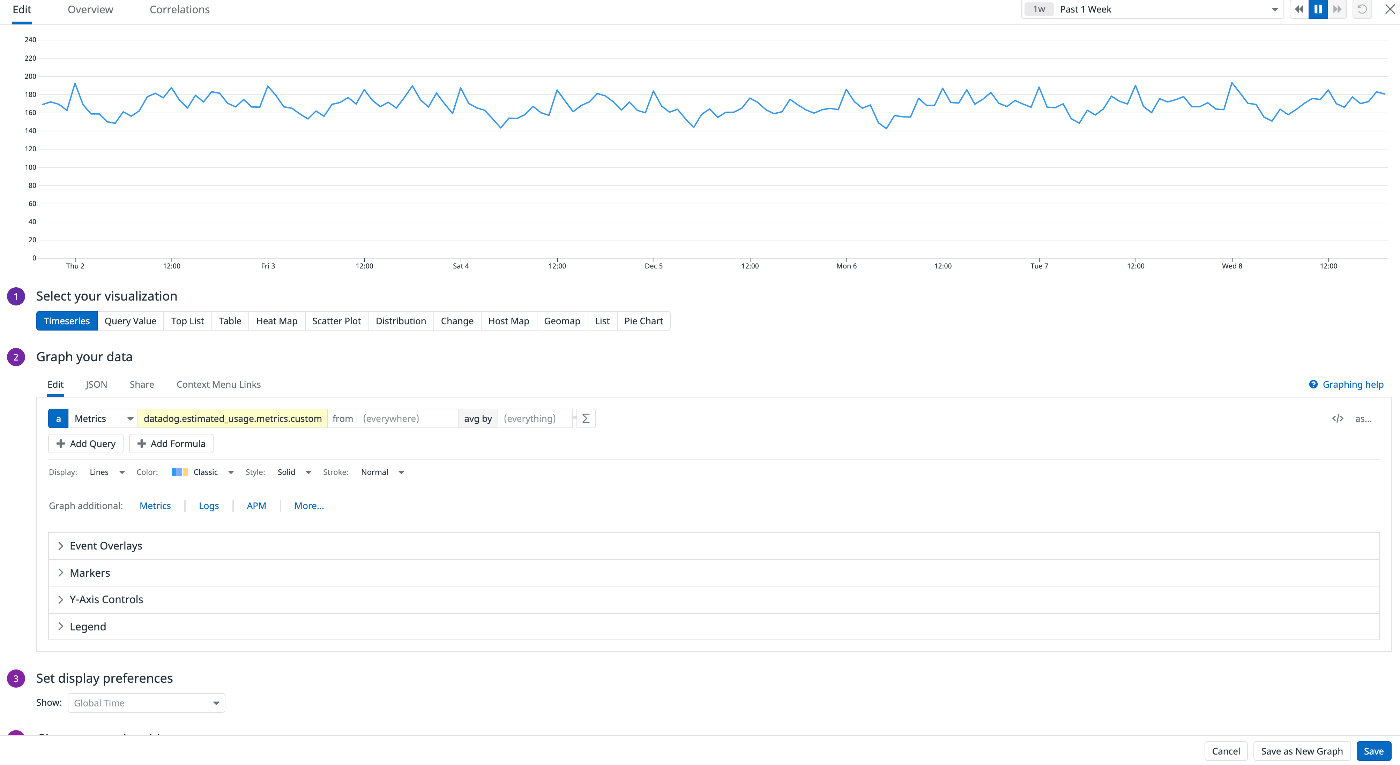
健全なカスタムメトリクス
さらに使用量の急上昇または低下の即時アラートを取得する設定をしておけば安心かと思われます。
(Monitor設定はまだやってないのでそのうち・・・)
また、チームメンバーにはこの設定をこうしたら請求が跳ね上がるから気をつけましょうという旨のドキュメントを書いて共有してあります。
まとめ
- Datadogの料金体系は必ず目を通しておきましょう
- Datadogの毎月の請求情報にも必ず目を通しておきましょう
- やらかしたかも?と思ったらすぐカスタマーサポートに連絡を
SaaSを使う時は実現したい事がプランの範囲内で収まるのか、収まらない場合は追加でどれくらいかかるのかをちゃんと確認しましょう。お兄さんとの約束だぞ!
余談
TwitterでDatadogのTanabeさんに教えていただいたのですが、実はカーディナリティは調整できるらしいです!!全然知らなかった!!
Discussion