【AIアダルトチェック】AWS Rekognitionでアダルト画像かどうかを自動判別して業務を効率化する方法
【AIアダルトチェック】AWS Rekognitionでアダルト画像かどうかを自動判別して業務を効率化する方法
webとモバイルアプリ両方で漫画サービスを提供している会社でエンジニアとして働いて次のような課題がありました。
webでは配信できるアダルトコンテンツ(作品)がApp Storeのガイドラインに引っかかる関係でモバイルアプリでは配信出来ないためコンテンツそれぞれに対してアダルトかどうか判定してアダルト商品にはフラグを立てておく必要があります。(アダルトフラグの立っているものは配信しないロジック)
この前、某出版社から1万コンテンツの入稿があり、1万コンテンツをアダルトコンテンツかどうか判別する作業がありました。
1コンテンツを確認するのに30秒掛かると仮定すると1万件やると30×1万=30万秒=83時間20分掛かる計算となります。
その作業を確認する人件費を 1500円/1hだと見積もっても12万5千円掛かります。
- 人手が足りず確認作業を行えるだけのリソースが無い
- 今後も同じような入稿作業がある
- 人件費が勿体ない
などの課題を解消するためにこの作業を自動化することを試みました。
独自で画像解析のAPIを作成する程のリソースは無かったのでクラウドを利用しようと思い、GCP,Azure,AWSそれぞれの画像解析ツールを調べ、料金的な面や会社でAWSを使っているという観点でAWS Rekognitionを使うことに決定しました。
(AWSの試験問題で名前だけうっすら知ってたコイツを遂に触る日が来ました)
まずはGUI(AWSのマネージドコンソール)からどのようにスコアリングされるか調べます。

AWS Rekognitionはいろいろな機能があるのですが、その中でも今回は青四角で囲った「画像の節度」を使います。
「画像の節度」では画像を投げると、adultやviolence等の度合いをスコアリングして数値で返してくれます。
問題ない画像は0を返し、adult度maxのものは100を返します。
実装
コンテンツは本番環境のEC2の中で管理しているので本番環境にスクリプトをデプロイしてEC2の中でアダルト判定を行い、その都度コンテンツのDBのをUPDATEするという手法をとりました。
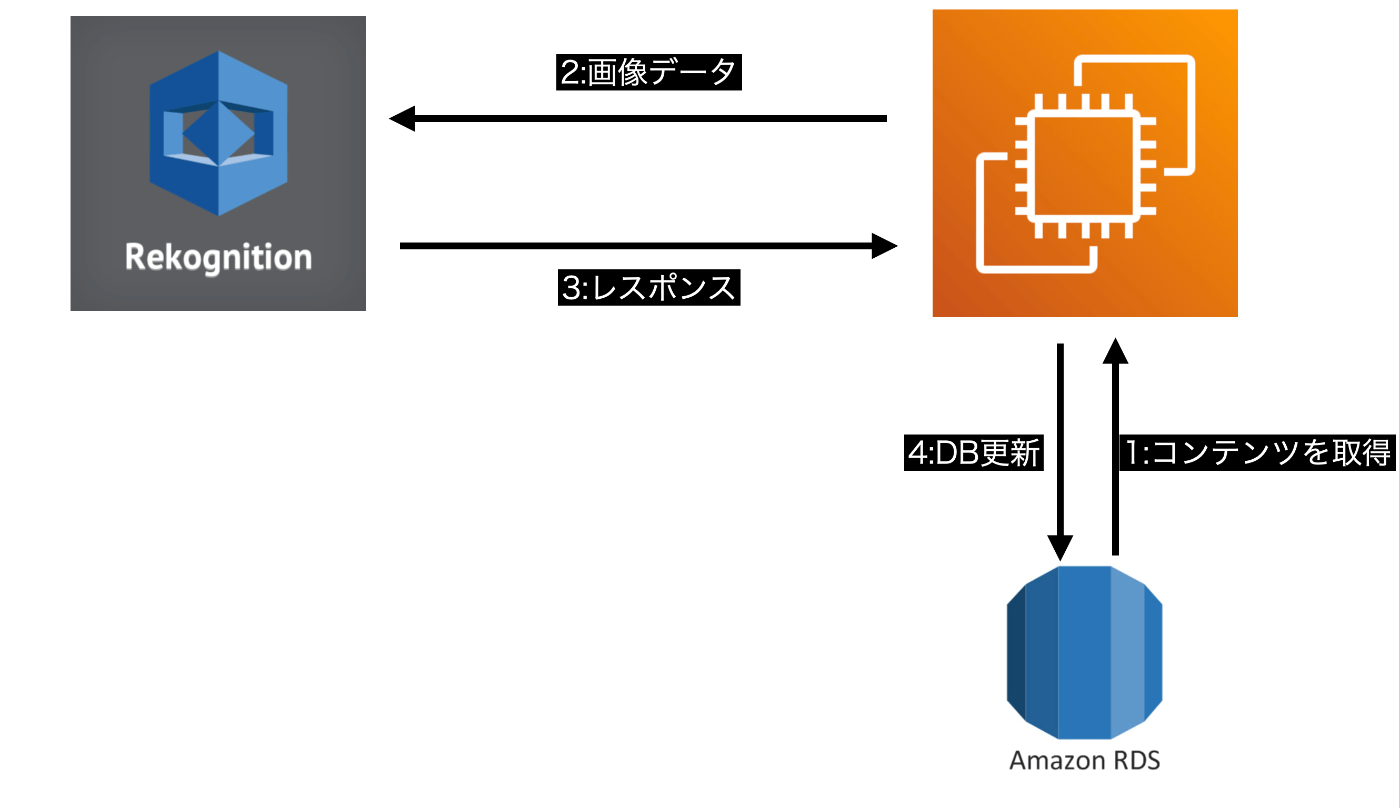
- RDS(DB)からアダルト判定していないコンテンツを取得
- アダルト判定してないコンテンツの画像データをAWS Rekognitionにリクエスト
- レスポンスの値を確認して最大値を取得、最大値が80を超えていたらアダルトコンテンツとみなす
- チェック済にするためDB更新(アダルトコンテンツはアダルトフラグを立てる)
バックエンドはPython,Djangoを使っているのでEC2にIAM権限を持たせてboto3をインストールすることで簡単に実装できました。
簡単なサンプルコード
import boto3
client = boto3.client('rekognition', region_name='ap-northeast-1')
# image_binaryが画像データ
response = client.detect_moderation_labels(Image={'Bytes': image_binary})
# 以下responseデータを確認
実際のコード
もっと細かく色々説明したいところですがもうめんどくさいので実際のコードを載せちゃいます。
# -+- coding: UTF-8 -*-
import io
import os
from typing import List
import boto3
from PIL import Image, ImageFile
from django.conf import settings
from django.core.management.base import BaseCommand
from django.utils import timezone
from contents_admin.models import Title, TitleRelease
from submodules.batch.decorators import save_batch_status
source_dir = settings.IMAGE_BT_SOURCE_DIR
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Command(BaseCommand):
"""
amazon rekognitionを使って画像のアダルトチェックを自動化
"""
def add_arguments(self, parser):
parser.add_argument(
'-l', '--verbose', action='store_true',
dest='verbose', default=None,
help='ログを詳細に出力します'
)
parser.add_argument(
'-t', '--title_code', action='store',
dest='title_code', default=None,
help='タイトルコードを指定します'
)
parser.add_argument(
'-p', '--publisher', action='store',
dest='publisher', default=None,
help='出版社を指定します')
@save_batch_status(__file__)
def handle(self, verbose, title_code, publisher, *args, **kwargs):
if not title_code and not publisher:
print('タイトルコードまたは出版社を指定してください')
return
titles = Title.objects.filter(adult_flag=0, genre_id__in=[1111, 1112, 1113, 1120])
if title_code:
titles = titles.filter(title_code=title_code)
if publisher:
titles = titles.filter(publisher=publisher, ai_checked_date__isnull=True)
self.__rekognize(titles=titles, verbose=verbose)
def __rekognize(self, titles: List[Title], verbose: bool):
client = boto3.client('rekognition', region_name='ap-northeast-1')
for t in titles:
ai_checked_max_score_page = 0
is_break: bool = False
is_error: bool = False
print(f"[START] w90_adult_check_api, {t.title_code}")
try:
volume_dir = os.path.join(source_dir, t.directory_prefix, t.title_code, '001')
images_paths = \
sorted([i for i in os.listdir(volume_dir) if not (i.startswith(".") or i.startswith("@"))])
except FileNotFoundError:
print(f"[ERROR] image not found, {t.title_code}")
continue
score: int = 0
for idx, i in enumerate(images_paths[:20]):
image_file_path = os.path.join(volume_dir, i)
image = Image.open(image_file_path)
stream = io.BytesIO()
image.save(stream, format="JPEG")
image_binary = stream.getvalue()
try:
response = client.detect_moderation_labels(Image={'Bytes': image_binary})
except Exception:
print(f"[ERROR]{image_file_path}")
is_error = True
break
# このタイトルをスキップする
label_list = response.get('ModerationLabels')
if label_list:
if verbose:
print(f"{image_file_path} => {label_list}")
for label in label_list:
label_name = label.get('Name')
# Explicit Nudityラベルの値だけ取得
if label_name == 'Explicit Nudity':
label_score = label.get('Confidence')
# 最大値が欲しいので比較して現在の値より大きかったら代入
if score < label_score:
score = label_score
ai_checked_max_score_page = idx + 1
if score >= 90:
# スコアが90以上の場合はそれ以上チェックしない
is_break = True
break
if is_break:
break
# rekognitionでadultスコアリング
# 20個の画像で最もスコアが高いものをDB保存する
if not is_error:
t.ai_checked_score = score
t.ai_checked_date = timezone.now()
t.ai_checked_max_score_page = ai_checked_max_score_page
if score < 80:
TitleRelease.objects.filter(app_id__in=['ios', 'android'], title=t).update(enable=True)
t.torico_checked_date = timezone.now()
t.torico_checked = True
else:
TitleRelease.objects.filter(app_id__in=['ios', 'android'], title=t).update(enable=False)
t.save()
今回は割愛しますが、このコマンドをビジネスサイドの人が管理画面から実行出来るようにしたため、今後新たに入稿があった場合はこのコマンドを実行すればAIが自動でチェックしてくれます。
最後に
AWS Rekognitionはアダルト画像ではないのにアダルト判定されてしまったり、アダルト画像なのにアダルト判定されなかったりと決して万能ではなかったですが工夫して使えば業務に活かせることが分かりました。
アダルトかどうかを見極める作業は人によってはムラムラしてしまうのでこのような作業が自動化出来ることは大変素晴らしいことだと思います。
今後もクラウドで面白いサービスがあればどんどん活用していきたいと思います。
Discussion