🐡
LLMをざっとまとめ ver.1

自分の理解と整理のために、2017年のTransformer登場以降のLLMをまとめてみます
目次
- Transformer
- GPT
- BERT
- GPT-2
- RoBERTa
Transformer
まずはベースとなるTransformerから
論文(2017年6月)
概要
- Attentionを使うことで大規模な並列計算が可能なアーキテクチャ
- 以降の多くのモデルのベースとなる
アーキテクチャ
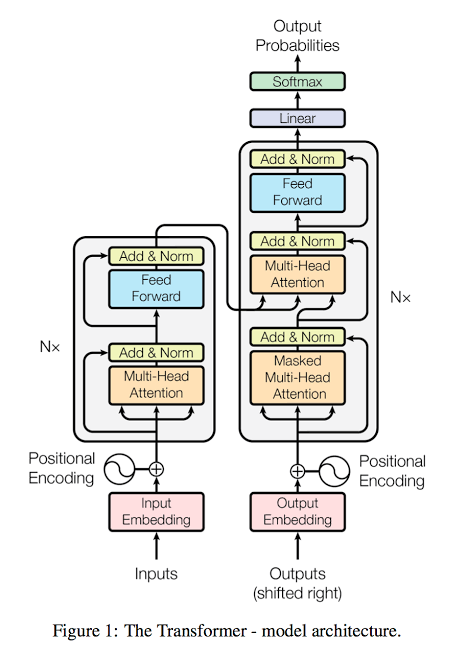
論文より転載
- エンコーダデコーダ型を採用
- 「マルチヘッドアテンション層」「順伝播型ネットワーク」から成るエンコーダ層
- 「マスクされたマルチヘッドアテンション層」「エンコーダから一部入力を受けとるマルチヘッドアテンション層」「順伝播型ネットワーク」から成るデコーダ層
- アテンションによる入力トークン間の関連性表現
- Query,Key,Valueによって計算、さらに複数ヘッドにすることで各トークンの多様な意味を表現
- その他の要素
- 順伝播型ネットワークではReLUで活性化
- 埋め込みとソフトマックス
- 位置エンコーディングには三角関数を使用
学習と結果
- 450万セットの英独翻訳データ
- BLEUスコア28.4 - 3600万セットの英仏翻訳データ
- BLEUスコア41.8 - いずれもSoTA
GPT
次はOpenAIのGPT
論文(2018年6月)
概要
- 大量のラベルなしデータを使って事前学習することで、少量のラベル付きデータによるfine-tuningするだけで様々なタスクを処理できるモデルを作った
アーキテクチャ
- Transformerのデコーダ部分を使用
- 位置エンコーディングをパラメータで持たす、活性化関数にGELUを使う等の変更あり
- パラメータ数
- 1.1億 (全12層、隠れ層768次元、ヘッド数12)
学習
- 事前学習
- 前方の内容から次の単語を予測させて学習
- 7000以上の本から成るBooksCorpusデータセット
- fine-tuning
- 各タスクに合わせた学習
- 次単語の予測と文章の分類の2タスクを同時に行う
結果
- Natural Language Inference (推論)
- MNLI、SNLI、SciTail、QNLIでSoTA
- RTEはデータ数が少なくSoTAならず
- Question Answering (質疑応答)
- StoryCloze、RACEでSoTA
- Semantic Similarity (類似判定)
- STS-B、QQPでSoTA
- MRPCではSoTAならず
- Classification (分類)
- CoLAでSoTA
- SST-2ではSoTAならず
BERT
続けてBERT
論文(2018年10月)
概要
- 文章を双方向に予測させ学習させることで、様々なタスクにfine-tuning可能なモデルを作った
アーキテクチャ
- Transformerのエンコーダ部分を使用
- パラメータ数
- BERTbase 1.1億 (全12層、隠れ層768次元、ヘッド数12)
- BERTlarge 3.4億 (全24層、隠れ層1024次元、ヘッド数16)
学習
- 事前学習
- 8億語のBooksCorpusと25億語のWikiepediaのテキスト
- 2種類のタスクを同時に実行
- マスクしたトークンを当てるタスク(MLM)
- 80%マスク、10%別トークン、10%変更なし
- 2文が連続しているかを当てるタスク(NSP)
- マスクしたトークンを当てるタスク(MLM)
- fine-tuning
- 各タスクに合わせた学習
- 出力層のみ付け替える
結果
- GLUE (推論、分類、類似判定等をまとめたタスク)
- MNLI、QQP、QNLI、SST-2、CoLA、STS-B、MRPC、RTEの8項目
- 8項目すべてでSoTA
- SQuAD v1.1、SQuAD v2.0 (質疑応答)
- どちらもSoTA
- SQAG (推論)
- SoTA
GPT-2
次はGPT-2
論文(2019年2月)
概要
- パラメータ数と教師なしデータによる事前学習の量を増やすことで、特定タスクのための学習を必要としないモデルを作った
アーキテクチャ
- GPTと同様にTransformerのデコーダ部分を使用
- LayerNormalizationの位置を変える等、細かい変更あり
- パラメータ数
- 1.1億 (全12層、隠れ層768次元)
- 3.4億 (全24層、隠れ層1024次元)
- 7.6億 (全36層、隠れ層1280次元)
- 15億 (全48層、隠れ層1600次元)
学習
- 事前学習
- GPTと同様に次単語の予測
- webクローリングして取得したデータ(800万文書/40GB)
- Byte Pair Encodingで入力
- 追加学習はなし
結果
- 各種データセットを追加学習なしで予測
- LAMBADA、Children's Book Test…を始めとする単語予測等のデータセットでSoTA
- 1BWデータセットではSoTAならず
- Winograd Schema Challenge (推論)
- SoTA
- Reading Comprehension(読解)、Translation(翻訳)、Summarization(要約)、Question Answering(質疑応答)
- SoTAならず
RoBERTa
次はRoBERTa
論文(2019年7月)
概要
- BERTのハイパーパラメータや学習データを調整することで、精度を大幅に改善した
アーキテクチャ
- 基本はBERTと同じ
- 一部パラメータを調整
学習
- 事前学習
- 合計160GBのテキストデータセット
- BookCorpus、Wikipedia、CC-NEWS、OpenWebText、Stories
- MLMのマスク場所を毎回動的に変更
- NSPをなくし、512トークンの長文を入力データとした
- バッチサイズを256→8000と大きくした
- Byte Pair Encodingで入力
- 合計160GBのテキストデータセット
- fine-tuning
- 各タスクに合わせた学習
結果
- GLUE (推論、分類、類似判定等をまとめたタスク)
- 5項目でSoTA
- SQuAD v1.1、SQuAD v2.0 (質疑応答)
- SoTAと同等以上
- RACE (質疑応答)
- SoTA
まとめ
- どれもTransformerをベースとして、ハイパーパラメータ調整や学習方法の工夫で性能を上げてきた
- そういった工夫の中でモデルサイズも段々とUP
- 性能評価の方法もGLUEやRACE等、確立されている
…といったことが整理できました
まだまだ最新のモデルには追いついてないので、ver.2も書きます
Discussion