OpenCALMをLoRAでファインチューニング

先日、OpenCALMをファインチューニングしてみましたが再チャレンジです
目次
- モデル準備
- LoRA設定
- データセット準備
- トレーニング
- モデル保存
- 結果
- まとめ
モデル準備
前回と同様にOpenCALMを使用します
GoogleColab上でGPU「A100」を選択し、以下を実行します
!pip install transformers
!pip install accelerate
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "cyberagent/open-calm-7b"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(model_name)
一番大きい7Bサイズを選択
前回は32ビットのfloatでしたが、16ビットのfloatにサイズを下げてメモリを節約します
LoRA設定
LoRAとはこちらの論文で発表された手法
ざっくり以下の内容です
- 追加学習を効率よく行う手法で、元のパラメータを更新せず差分として保持
\bm{W}_{0}→\bm{W}_{0}+\Delta\bm{W} - さらに差分の部分を低ランク行列の積で表現することで学習パラメータ数を大幅に減らす
\Delta\bm{W}=\bm{AB}
以下のコードでモデルをラップすることで使用できます
!pip install peft
from peft import LoraConfig, TaskType, get_peft_model
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=4,
lora_alpha=16,
lora_dropout=0.1
)
model = get_peft_model(model, peft_config)
低ランク部分の次元数であるrは、論文内で結果の良かった4にしておきます
パラメータ数を見てみます
model.print_trainable_parameters()
trainable params: 2,097,152 || all params: 6,874,079,232 || trainable%: 0.030508115039428164
0.03%まで減っていますね
より詳細な構成は以下で見れます
print(model.parameters)
<bound method Module.parameters of PeftModelForCausalLM(
(base_model): LoraModel(
(model): GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(52224, 4096)
(emb_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-31): 32 x GPTNeoXLayer(
(input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
(post_attention_dropout): Dropout(p=0.0, inplace=False)
(post_mlp_dropout): Dropout(p=0.0, inplace=False)
(attention): GPTNeoXAttention(
(rotary_emb): GPTNeoXRotaryEmbedding()
(query_key_value): Linear(
in_features=4096, out_features=12288, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=4, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=4, out_features=12288, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(dense): Linear(in_features=4096, out_features=4096, bias=True)
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=16384, bias=True)
(dense_4h_to_h): Linear(in_features=16384, out_features=4096, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=4096, out_features=52224, bias=False)
)
)
)>
LoRAモデルでラップされてるのがわかりますね
なお、デフォルトではLoRAはTransformerのAttention層のみに付加されます
データセット準備
前回と同様にこちらの日本語データセットを使います これを使って、質問に正確にかつ簡潔に答えてくれるよう目指してトレーニングします
!pip install datasets
from datasets import load_dataset
train_size = 300000
eval_size = 100
token_max = 64
seed = 1
dataset_origin = load_dataset("izumi-lab/llm-japanese-dataset", revision="main", split="train[:" + str(train_size+eval_size) + "]")
dataset = dataset_origin.select(range(0, train_size + eval_size))
def data_arrange(data):
if data['input'] == '':
data_q = data['instruction']
else:
data_q = data['instruction'] + '\n' + data['input']
input_q = 'Q:' + data_q + '\nA:'
tokenized_q = tokenizer(input_q, return_tensors='pt', padding='max_length', truncation=True, max_length=token_max)
input_qa = 'Q:' + data_q + '\nA:' + data['output'] + tokenizer.special_tokens_map['eos_token']
tokenized_qa = tokenizer(input_qa, return_tensors='pt', padding='max_length', truncation=True, max_length=token_max)
labels = tokenized_qa['input_ids'][0].clone()
for i in range(0, token_max):
if not tokenized_q['input_ids'][0][i] == 1:
labels[i] = -100
return {
'input': input_q,
'input_ids': tokenized_q['input_ids'][0],
'attention_mask': tokenized_q['attention_mask'][0],
'labels': labels
}
dataset_tokenized = dataset.map(
data_arrange,
remove_columns=['instruction', 'output']
)
dataset_split = dataset_tokenized.train_test_split(train_size=train_size, seed=seed)
dataset_train = dataset_split['train']
dataset_eval = dataset_split['test']
トレーニングデータ数は30万とし、以下の内容で整形します
- 最終的なカラムは「input」「input_ids」「attention_mask」「labels」の4つ
- 「Q:<質問文>\nA:」の形のテキストを「input」に設定
- 一部のdata['input']にもテキストデータが含まれていたので上記<質問文>に文字列結合する
- tokenizerは「padding='max_length', truncation=True, max_length=token_max(=64)」と設定することで全トークンを同じ長さにし、トークン化したテキストを「input_ids」に、paddingした部分の情報を「attention_mask」に設定
- 「Q:<質問文>\nA:<回答><終了トークン>」の形のテキストをトークン化し、そのうち「Q:<質問文>\nA:」にあたる部分を「-100」とすることで評価時に無視するよう整形したものを正解ラベルとして「labels」に設定
具体的には以下のような中身です
print(dataset_train[0])
{'input': 'Q:次の日本語を英語に翻訳してください。\nどういうことか 詳しく聞こうか?\nA:', 'input_ids': [50, 27, 5181, 3533, 255, 2241, 38531, 2509, 247, 186, 11502, 36747, 204, 8683, 1349, 1618, 267, 32, 186, 34, 27, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'labels': [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 74, 10235, 76, 1480, 9797, 8605, 7362, 2245, 2619, 2, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
トレーニング
トレーニングを行います
from transformers import TrainingArguments, Trainer
learning_rate = 1e-5
epochs = 1
batch_size = 60
log_steps = 100
seed = 1
model.train()
training_args = TrainingArguments(
output_dir="trained_model",
learning_rate=learning_rate,
num_train_epochs=epochs,
evaluation_strategy='steps',
per_device_train_batch_size=batch_size,
logging_steps=log_steps,
eval_steps=log_steps,
seed=seed,
fp16=True,
save_steps=5000
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset_train,
eval_dataset=dataset_eval
)
train_result = trainer.train()
GPU「A100」ではバッチサイズは60が限界でした
全30万データで1エポックなので、5000ステップまわします
training_argsでsave_steps=5000と指定します
デフォルト500ですが、毎回チェックポイントとしてモデルを保存し容量が足りなくなるので、大きな値にし保存が発生しないようにします
大体1時間くらいかかりました
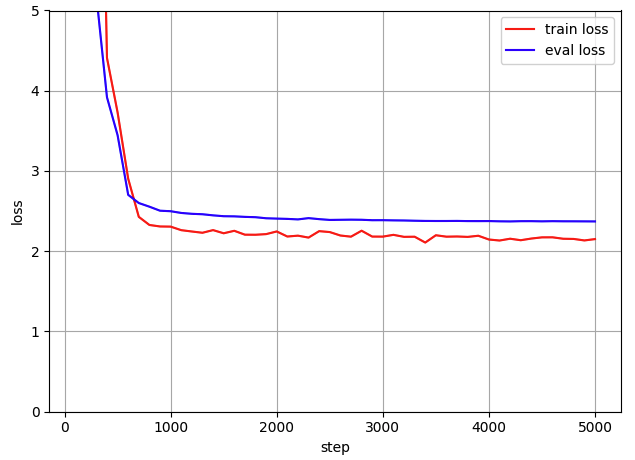
600ステップくらいまでで損失が大きく下がり、以降は微減していますね…
モデル保存
チューニングしたモデルをGoogle Drive上に保存します
from google.colab import drive
drive.mount('/content/drive')
import datetime
from dateutil import tz
filename = '/content/drive/MyDrive/********/' + model_name + '_ft_' + datetime.datetime.now(tz.gettz('Asia/Tokyo')).strftime('%Y%m%d%H%M%S')
model.save_pretrained(filename)
保存したモデルは以下で読み込めます
from peft import PeftModel, PeftConfig
foldername = '/content/drive/MyDrive/********/cyberagent'
filename = '/content/drive/MyDrive/********/cyberagent/open-calm-7b_ft_********'
config = PeftConfig.from_pretrained(filename)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path)
model = PeftModel.from_pretrained(model, filename)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
結果
チューニングしたモデルに以前までと同様の質問をしてみます
Q:ドラゴンボールの作者は誰?
A:鳥山明
(正解:鳥山明)
Q:楽天の社長は誰?
A:藤田氏
(正解:三木谷浩史)
Q:パンダはどこの国の国獣?
A:中国の動物。
(正解:中国)
Q:相対性理論を提唱したのは誰?
A:アインシュタイン
(正解:アルベルト・アインシュタイン)
Q:ドラえもん映画が最初に放映されたのはいつ?
A:映画版「どこでもドア」は1983年に劇場公開されています。
(正解:1980年3月)
Q:日本で最も店舗数の多いコンビニは?
A:ローソンやセブンイレブン。この2社は国内総店舗でトップ10に入っています
(正解:セブンイレブン)
Q:日本の都道府県で最も面積が広いのは?
A:沖縄・北海道
(正解:北海道)
Q:日本の通貨単位は何?
A:円・ドル)
(正解:円)
正解率は正直高くないですが、以前までの冗長な回答はなくなり、簡潔に答えてくれるようになりました!
まとめ
LoRAを使うことで生でファインチューニングするよりも大きなモデルとデータでできるようになりました
正確性はまだまだですが、一旦形になって保存までできたので、次はこのモデルを使って簡単なチャットUIを作る等していきたいと思います
Discussion