llama3.1 405B モデルをA100 * 4で推論してみた


現状の検証事項
推論ベースの検証結果です。
| モデル名 | 検証状況 |
|---|---|
| Meta-Llama-3.1-405B-Instruct | ⭕️ bitsandbytesで4bit |
| Meta-Llama-3.1-405B-Instruct-FP8 | ❌ FP8で回すためには、A100ではなくH100が必要 |
| hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4 | ⭕️ |
利用時に関して
今回はHFモデルを使用します。利用にはHFで申請が必要です。
特徴
コンテキスト長が128K tokensに対応しています。

引用: https://scontent-nrt1-2.xx.fbcdn.net/v/t39.2365-6/452387774_1036916434819166_4173978747091533306_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=t6egZJ8QdI4Q7kNvgHY23Q4&_nc_ht=scontent-nrt1-2.xx&oh=00_AYC62w8L7D3YeXR3KpK9_EAO_6EHAT3VetM1pQtodk2XCA&oe=66A60A8D
ベンチマーク
論文のベンチマークの結果も高く出ています。

モデルアーキテクチャー
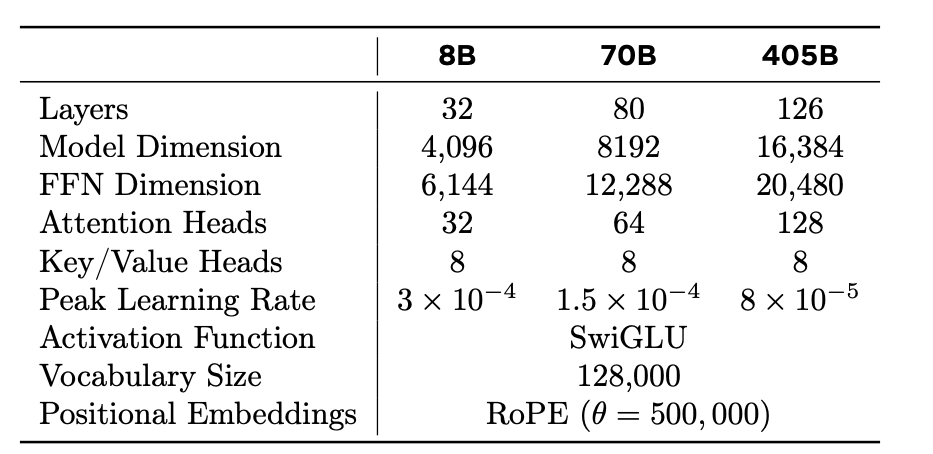
モデルのダウンロード
LOCAL_PATH = "保存する場所"
HF_TOKEN = "トークンをここに入れる。"
download_path = snapshot_download(repo_id="meta-llama/Meta-Llama-3.1-405B-Instruct",
local_dir=LOCAL_PATH,
token=HF_TOKEN,
local_dir_use_symlinks=False)
環境
今回は(1node) A100 4枚の環境で試してみます。さすがに A100 4枚では乗り切らないので4bit量子化しました。
筆者のライブラリ/ハード環境
databricks環境(実際はnotebookですが、通常にpythonを動かすように記載しています。)
cuda121
torch 2.3.0+cu121
lash-attn 2.5.8
transformers 4.43.1
読み込み
pip install --upgrade pip
pip install bitsandbytes
pip install --upgrade transformers
import torch
from transformers import AutoTokenizer,AutoModelForCausalLM,BitsAndBytesConfig
LOCAL_PATH = "/Path/to/llama3/405B/405B/" # 保存した場所を指定
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
tokenizer = AutoTokenizer.from_pretrained(LOCAL_PATH)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(LOCAL_PATH,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map='auto')
シングルノードなので、device_map='auto'でモデルをパラレルします。
↓下記に気をつける。
Inference: For inference, bnb_4bit_quant_type does not have a huge impact on the performance. However for consistency with the model's weights, make sure you use the same bnb_4bit_compute_dtype and torch_dtype arguments.
モデルの構造
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 16384)
(layers): ModuleList(
(0-125): 126 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(q_proj): Linear4bit(in_features=16384, out_features=16384, bias=False)
(k_proj): Linear4bit(in_features=16384, out_features=2048, bias=False)
(v_proj): Linear4bit(in_features=16384, out_features=2048, bias=False)
(o_proj): Linear4bit(in_features=16384, out_features=16384, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear4bit(in_features=16384, out_features=53248, bias=False)
(up_proj): Linear4bit(in_features=16384, out_features=53248, bias=False)
(down_proj): Linear4bit(in_features=53248, out_features=16384, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=16384, out_features=128256, bias=False)
)
推論
prompt = "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\nuse Japanese.<|eot_id|><|start_header_id|>user<|end_header_id|>\n3 + 3はいくらになりますか?<|eot_id|><|start_header_id|>assistant<|end_header_id|>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
pre_generate_ids = model.generate(do_sample=False,
input_ids=inputs["input_ids"].to("cuda"),
max_length= 256,
eos_token_id=tokenizer.convert_tokens_to_ids("<|eot_id|>"))
pre_returned = tokenizer.batch_decode(pre_generate_ids, skip_special_tokens = False)[0]
print(pre_returned)
結果
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
use Japanese.<|eot_id|><|start_header_id|>user<|end_header_id|>はじましてこんにちは<|eot_id|><|start_header_id|>assistant<|end_header_id|>
こんにちは!はじめまして!お元気ですか?何かお話したいことありますか?<|eot_id|>
うまく読み込めました!!
meta-llama/Meta-Llama-3.1-405B-Instruct-FP8
公式が出しているFP8で量子化されたモデルを検証してみます。
結論: A100ではダメでした..
FP8 quantized models is only supported on GPUs with compute capability >= 9.0 (e.g H100)
pip install fbgemm-gpu
下記のエラーが出たので、accelerateをアップグレードします
FP8 quantized model requires accelerate > 0.32.1 (pip install --upgrade accelerate)
pip install --upgrade accelerate
hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4
GPTQでint4量子化されていたものがあったので今回はこれを利用してみます。
pip install optimum
pip install auto-gptq
import torch
from transformers import AutoTokenizer,AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(LOCAL_PATH,
torch_dtype=torch.bfloat16,
device_map='auto')
modelの構造
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(128256, 16384)
(layers): ModuleList(
(0-125): 126 x LlamaDecoderLayer(
(self_attn): LlamaSdpaAttention(
(rotary_emb): LlamaRotaryEmbedding()
(k_proj): QuantLinear()
(o_proj): QuantLinear()
(q_proj): QuantLinear()
(v_proj): QuantLinear()
)
(mlp): LlamaMLP(
(act_fn): SiLU()
(down_proj): QuantLinear()
(gate_proj): QuantLinear()
(up_proj): QuantLinear()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=16384, out_features=128256, bias=False)
)
GPU使用率
| 0 NVIDIA A100 80GB PCIe Off | 00000001:00:00.0 Off | 0 |
| N/A 51C P0 74W / 300W | 56141MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe Off | 00000002:00:00.0 Off | 0 |
| N/A 55C P0 86W / 300W | 61731MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA A100 80GB PCIe Off | 00000003:00:00.0 Off | 0 |
| N/A 56C P0 314W / 300W | 61731MiB / 81920MiB | 100% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA A100 80GB PCIe Off | 00000004:00:00.0 Off | 0 |
| N/A 52C P0 85W / 300W | 63349MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
実行結果
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
use Japanese.<|eot_id|><|start_header_id|>user<|end_header_id|>はじましてこんにちは<|eot_id|><|start_header_id|>assistant<|end_header_id|>
こんにちは!はじめまして!お元気ですか?<|eot_id|>
エラーが発生した場合の対処
(1)
ValueError: rope_scaling must be a dictionary with two fields, type and factor, got {'factor': 8.0, 'low_freq_factor': 1.0, 'high_freq_factor': 4.0, 'original_max_position_embeddings': 8192, 'rope_type': 'llama3'}
→ transformersのupgradeを実施
pip install --upgrade transformers
transformers 4.43.1 で解決
Discussion