This article was written as the Day 11 entry of the TimeTree Advent Calendar 2024.
Previous Year
In the previous year we introduced a new beta feature which allowed our users to generate appointments directly from images.
In a short summary, our app-side client would extract text information from an image using OCR and send this to our backend api, which in turn would query AI and return one or more events.

Our event extraction endpoint exactly one year earlier
Shortcomings
While working, the initial version had several shortcomings
- Reliancy on OCR.
- Slow response times
- Only one event is extractable
- Low accuracy of results
While all of these needed to be addressed, especially the reliancy on OCR was something that we wanted to tackle. It prevented us from rolling out the feature on Android due to there not being a device agnostic library readily available. It also added an additional step and increased the layer of complexity. If the OCR extracted text already contains errors, the chances or receving a correct response from the AI are slim. In addition it lead to the extracted text being in a somewhat unusual format (with lots of spaces and the text partly re-arranged) which further decreased result accuracy since generative AI generally works best with common text.
Progress
This year has brought many advancements in all things A.I., especially an increase in accuracy, faster response times and - most importantly - affordable image recognition endpoints.
- Send images directly instead of OCR
- Allow extraction of multiple events
- Increase response times
We evaluated several different AI providers, notably ChatGPT from OpenAI, Mixtral from Groq and Claude by Anthropic. In the end, Claude yielded the best results while still being affordable for image recognition. Note: This is but a snapshot in the ever changing field of AI and might already be outdated by the time this article is being written.
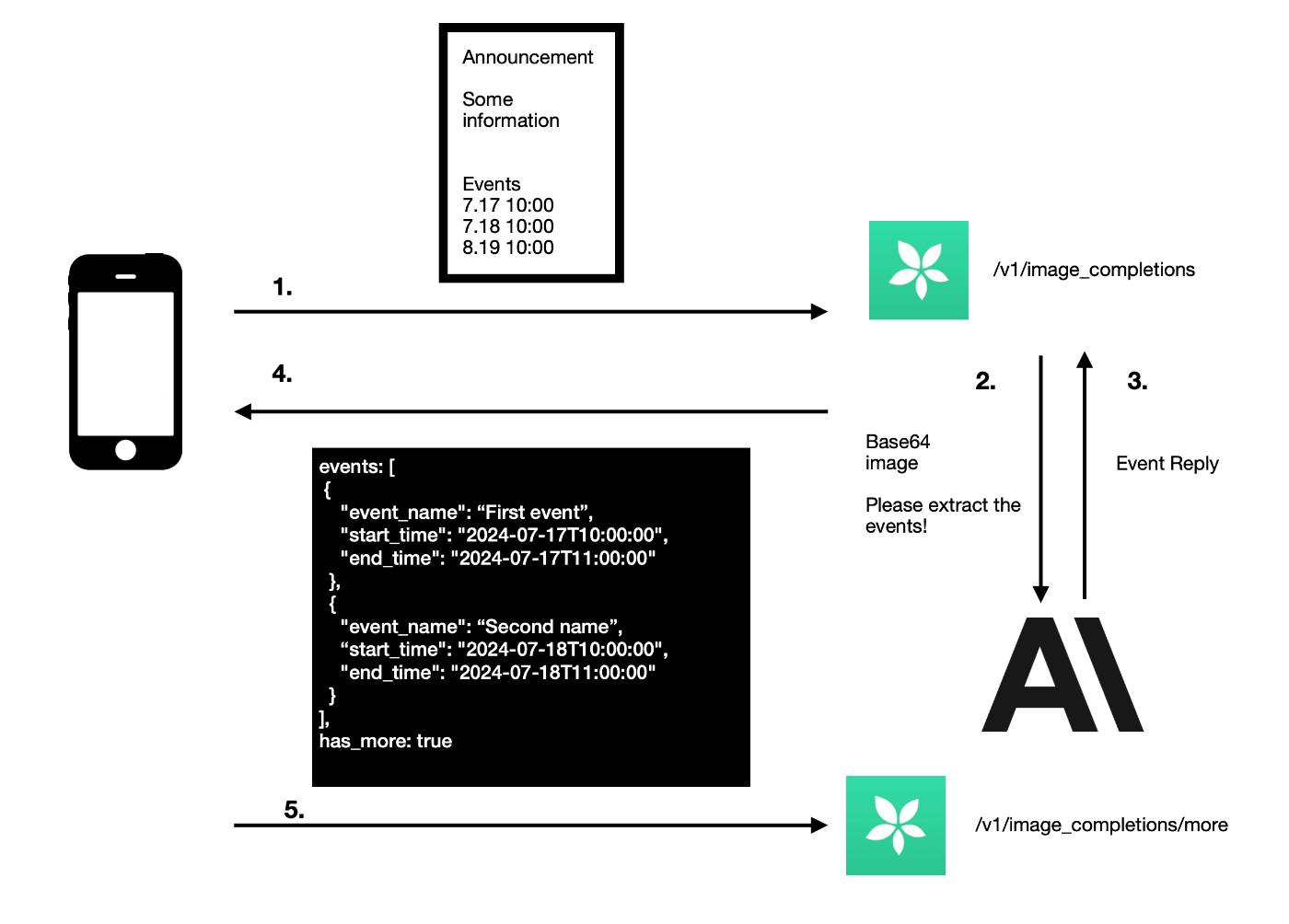
The re-envisioned, new endpoint for image extraction
Prompt
This is based on the documentation provided by anthropic.
Here is a (heavily abbreviated) version of the prompt messages sent to anthropic.
{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "AAABAAEAEBAAAAEAIABoBAAAFgAAACgAAAAQ...",
"data": "img/png"
}
},
{
"type": "text",
"text": "**Instructions**:
- Identify events in the provided image and return them in valid json format
**Expected Output**:
```json
{
\"events\": [
{
\"event_name\": \"String (required, <33 chars)\",
\"start_time\": \"ISO 8601 Date (required)\",
\"end_time\": \"ISO 8601 Date (required)\",
}
// Up to 10 event entries...
],
\"has_more_events\": \"boolean\"
}"
}
]
},
{
"role": "assistant",
"content": "{"
}
],
"temperature": 0.0,
"system": "You are a tool that extracts event information from images and returns it as nothing but valid JSON."
}
Noteworth is the last message, where we prefill the assisstant response with a single open bracket {. This makes it much more likely for the AI to just write JSON into the output without asking for more details or adding unwanted prose.
We omitted a lot of clarifications about the expected output for sake of brevity.
Multi-step extraction
In cases where the response contained a lot events (for example if the user scanned a list of concerts), the response time is quite long and even runs into timeouts. This can be mitigated by instructing the AI to only extract a set amount of events (e.g. three) and then ask for additional events during several conversational turns.
Since the APIs for all major AI providers are stateless, this makes it necessary to temporarily cache the conversations on the client (or in our case backend) side.
Essentially we have to resend the previous messages including the response received by the AI and ask for additional events.
{
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 2048,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": " ... "
},
{
"type": "text",
"text": " ... The previous instructions ... ",
}
]
},
{
"role": "assistant",
"content": "{ ... The AI reply ... }"
},
{
"role": "user",
"content": "Please send additional events"
}
{
"role": "assistant",
"content": "{"
},
],
"temperature": 0.0,
"system": "You are a tool that extracts event information from images and returns it as nothing but valid JSON."
}
Current State
Overall the endpoint has become faster and more reliable.

Latency percentiles for AI endpoint responses
Most requests can be handled in 5 seconds or less! A big improvement to last year
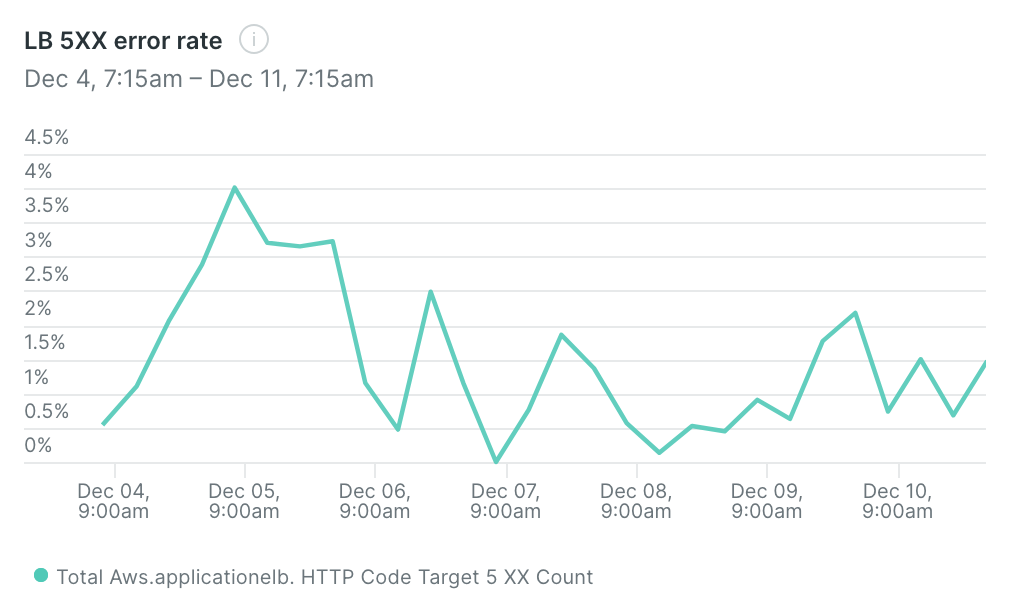
The percent of responses yielding an error over the last week
Errors are now usually caused by timeouts due to a slower-than-average response on the AI side combined with long outputs
The biggest payoff however was that we were finally able to roll out the event scan feature for Android devices!

TimeTreeのエンジニアによる記事です。メンバーのインタビューはこちらで発信中! note.com/timetree_inc/m/m4735531db852
Discussion