はじめに
こんにちは。タイムラボでカレンダーサービスLynxを開発している諸岡(@hakoten)です。
本記事では、代表的なグラフデータベースであるNeo4jについて、基本概念から実際のPythonコードでの操作方法を紹介します。
グラフデータベースとNeo4j
Neo4jは、リレーショナルデータベースとは異なり「グラフ構造」を扱うデータベースです。
リレーショナルデータベースでは、表(テーブル) と表同士の関係でデータを管理します。一方、グラフデータベースでは、オブジェクトを表す ノード と、それらを結ぶ エッジ でデータを表現します。

Neo4jは、このようなグラフデータを扱うためのアプリケーション(サービス)です。クラウドでのマネージド提供とオンプレミスのいずれでも利用できます。
AIの文脈では、2024年ごろからRAGのデータ構造にグラフを用いるGraphRAGが注目されていて、GraphRagのグラフ構築の手段としてNeo4jが採用されるケースも増えているようです。
Neo4jはこのようなGraphRAG関連の機能拡張も進めており、グラフ構造だけでなくベクトル検索などの機能もサポートしています。
Neo4jの基本コンポーネント
Neo4jは、次の4つの要素を使用してデータを保存および整理します。
| コンポーネント | 説明 |
|---|---|
| ノード | グラフの基本的なエンティティ |
| リレーションシップ | ノード間のつながり |
| ラベル | ノードのカテゴリまたはタイプ |
| プロパティ | ノードとリレーションシップの属性データ |
ノード

ノードは、データ内のオブジェクト、エンティティを指します。例えば、特定の人や場所、モノがノードにあたります。
ラベル

ラベルはノードを カテゴリ や グルーピング するためのものです。前述でいうと、「人物」「場所」「会社」「部署」などがそれにあたります。

ノードは複数のラベルを持つことができます。
リレーションシップ

リレーションシップは、ノード同士の関連を指します。例えば、「ある人物が会社に所属している」「会社がある機材を所有している」など、動詞の関連を表現しています。
リレーションシップは方向を持っており、A→Bを表現することができます。また方向は、片方のみの場合も両方(双方向)の場合もあります。

- Michael は、Neo4j で働いている: 単方向
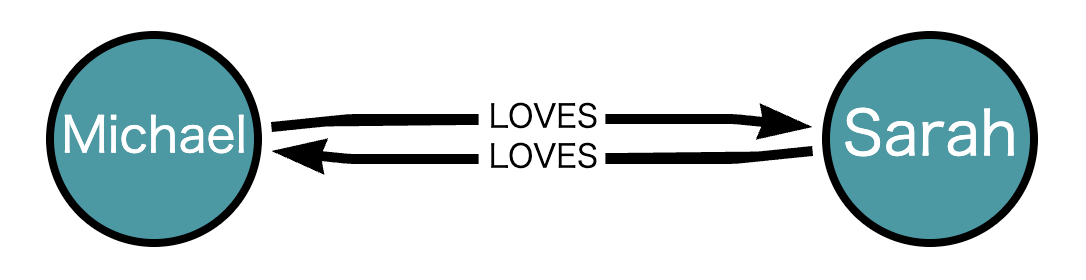
- Michael と Sarah はお互い好き合っている: 双方向
プロパティ

プロパティは、ノードやリレーションシップを補足するためのメタデータのような位置付けとなるデータです。リレーショナルデータベースのテーブルのカラムのようなイメージですが、スキーマレスのデータ構造になっており、同じラベルを持つデータにおいても同じプロパティを持つ必要はありません。
Cypher
前述の4つのコンポーネントを扱いデータを構築する操作言語として、Neo4jでは「Cypher」と呼ばれるクエリ言語を用います。Cypherは、グラフ用クエリ言語のISO規格であるGQLに準拠しており、リレーショナルデータベースにおけるSQLに相当します。
Neo4jではCypherを使って前述のノード、リレーションシップ、ラベル、プロパティを操作し、データの「参照」「挿入」「削除」などを行います。
Cypherのサンプル
(:nodes)-[:ARE_CONNECTED_TO]->(:otherNodes)
このサンプルは、2つのノード(:nodes)と(:otherNodes)が、[:ARE_CONNECTED_TO]という関係(エッジ)で結ばれていることを表しています。矢印は関係の向きを示します。
次に簡単なCRUD操作について紹介します。
データの参照
MATCH
MATCH (p:Person)
RETURN p
データを参照するときは、MATCH句を使います。これはSQLにおけるSELECT句のようなもので、MATCHの後ろには参照する対象が続きます。
上記例では、「Person」というラベルを持つノードを参照しています。
p:Personのpは変数で自由に定義することができます。例文では、参照したPersonノードを返却しています。
プロパティでの絞り込み
MATCH (p:Person {name: '山田 太郎'})
RETURN p
データを絞り込む時に、プロパティを使うことができます。上記は、Personラベルを持ち、nameプロパティが'山田 太郎'のノードを参照します。
WHERE
WHERE句は、SQLと同じくデータのフィルタリングを行います。
MATCH (p:Person)
WHERE p.name = '山田 太郎'
RETURN p
先程のプロパティでの絞り込みと同じようなフィルタリングをWHERE句でも行うことができます。上記のようなシンプルなクエリの場合は、おそらくクエリ最適化によりパフォーマンスに影響はそれほどないかもしれませんが、状況によってはWHERE句とプロパティでの絞り込みでパフォーマンスが変わる可能性があります。
データの作成
CREATE
CREATE (p:Person {name: '山田 太郎'})
RETURN p;
CREATE句を使うと、ノードおよびリレーションシップを作成することができます。
MATCH (a:Person {name: '山田 太郎'}), (b:Company {name: 'Timelab'})
CREATE (a)-[:WORKS_AT]->(b)
RETURN a, b
特定の条件でマッチしたノードに対して、リレーションシップを作成することができます。
MERGE
MERGE (p:Person {name: '山田 太郎'})
RETURN p;
データを作成するには、CREATE句を使う方法の他にMERGE句を使うことができます。MERGE句は、SQLにおける「INSERT... IF NOT EXISTS」「UPSERT」に近い概念の構文で、「パターンのノードが存在しなければ作成する」というものです。
MERGE (p:Person {name: '山田 太郎'})
ON CREATE SET p.createdAt = timestamp()
ON MATCH SET p.lastSeen = timestamp()
RETURN p;
存在しない時の作成時と、存在しているときの参照時で、挙動を分けることもできます。
データの削除
DELETE
MATCH (p:Person {name: '山田 太郎'})
DELETE p;
該当するノードを削除する場合は、DELETE句を使用します。
MATCH (p:Person {name: '山田 太郎'})
DETACH DELETE p;
ただし、ノードに関連するリレーションシップが作成されている場合、そのままだとリレーションシップは削除されません。リレーションシップごと削除するには、DETACHをつけます。
REMOVE
MATCH (p:Person {name: '山田 太郎'})
REMOVE p.age
RETURN p
ノードやリレーションシップのラベルまたはプロパティを削除する場合は、REMOVE句を使用します。この例では、「ラベルPersonのうちname = '山田 太郎'のノード」に対して、ageプロパティを削除しています。
Python上でのNeo4jの操作
ここからは、実際にプログラム上からNeo4jを操作して、データの作成や参照を行ってみます。
Dockerを使ってローカルで起動する
Neo4jには公式のDockerイメージが提供されているため、ローカルで動作を確認することが可能です。今回は公式で配布されているCommunity Editionイメージを使ってローカルに環境を構築します。
docker compose
services:
neo4j:
image: neo4j:5.24-community
container_name: neo4j-sample
ports:
- "7474:7474" # HTTP (Neo4j Browser)
- "7687:7687" # Bolt Protocol
environment:
- NEO4J_AUTH=${NEO4J_USER:-neo4j}/${NEO4J_PASSWORD:-password}
- NEO4J_ACCEPT_LICENSE_AGREEMENT=yes
- NEO4J_dbms_memory_pagecache_size=${NEO4J_PAGECACHE_SIZE:-512M}
- NEO4J_dbms_memory_heap_initial__size=${NEO4J_HEAP_INITIAL:-512M}
- NEO4J_dbms_memory_heap_max__size=${NEO4J_HEAP_MAX:-1G}
# Enable APOC plugin (optional)
- NEO4J_PLUGINS=["apoc"]
volumes:
- neo4j_data:/data
- neo4j_logs:/logs
- neo4j_import:/var/lib/neo4j/import
- neo4j_plugins:/plugins
networks:
- neo4j-network
restart: unless-stopped
healthcheck:
test: ["CMD-SHELL", "wget --no-verbose --tries=1 --spider http://localhost:7474 || exit 1"]
interval: 30s
timeout: 10s
retries: 5
start_period: 40s
volumes:
neo4j_data:
driver: local
neo4j_logs:
driver: local
neo4j_import:
driver: local
neo4j_plugins:
driver: local
networks:
neo4j-network:
driver: bridge
このイメージを立ち上げて、http://localhost:7474 にアクセスするとNeo4jのブラウザが表示されます。

※ 初期パスワードは、id: neo4j、password: passwordにしています。
PythonのライブラリからNeo4Jのデータベースにアクセスする
まずは、手元のPython環境でneo4jの公式ライブラリをインストールします。
from neo4j import GraphDatabase
uri = os.getenv("NEO4J_URI", "bolt://localhost:7687")
user = os.getenv("NEO4J_USER", "neo4j")
password = os.getenv("NEO4J_PASSWORD", "password")
driver = GraphDatabase.driver(uri, auth=(user, password))
with driver.session() as session:
print("Neo4j に接続しました")
データベースは、GraphDatabaseモジュールからセッションをオープンするだけで使えます。bolt://は、Neo4j独自の通信プロトコルで、ポートは7687でアクセスできます。
Cypherの実行
session.run(
"""
CREATE (momotaro:Character {name: '桃太郎', role: '主人公', type: '人間'})
CREATE (ojiisan:Character {name: 'おじいさん', role: '育ての親', type: '人間'})
CREATE (obaasan:Character {name: 'おばあさん', role: '育ての親', type: '人間'})
CREATE (inu:Character {name: '犬', role: '仲間', type: '動物'})
CREATE (saru:Character {name: '猿', role: '仲間', type: '動物'})
CREATE (kiji:Character {name: '雉', role: '仲間', type: '動物'})
CREATE (oni:Character {name: '鬼', role: '敵', type: '妖怪'})
"""
)
セッションを開いたら、runメソッドから、Cypherを実行することができます。このサンプルでは Character ラベルをつけた人物を作成しています。

作成されたデータは、Neo4jブラウザから確認することができます。
result = session.run(
"""
MATCH (c:Character)
RETURN c.name as name, c.role as role, c.type as type
ORDER BY c.role
"""
)
for record in result:
print(record)
MATCHクエリを実行するときも、runメソッドを使います。
<Record name='桃太郎' role='主人公' type='人間'>
<Record name='犬' role='仲間' type='動物'>
<Record name='猿' role='仲間' type='動物'>
<Record name='雉' role='仲間' type='動物'>
<Record name='鬼' role='敵' type='妖怪'>
<Record name='おじいさん' role='育ての親' type='人間'>
<Record name='おばあさん' role='育ての親' type='人間'>
runの戻りとして、このようにRecordオブジェクトが取得できます。
コードサンプル
今回のデータ作成とクエリで作成したコードサンプルは次になります。
データ作成のサンプルコード
import os
from dotenv import load_dotenv
from neo4j import GraphDatabase
def create_sample_data() -> None:
"""
Neo4j にサンプルデータを作成する.
"""
load_dotenv()
uri = os.getenv("NEO4J_URI", "bolt://localhost:7687")
user = os.getenv("NEO4J_USER", "neo4j")
password = os.getenv("NEO4J_PASSWORD", "password")
# Neo4j に接続
driver = GraphDatabase.driver(uri, auth=(user, password))
try:
with driver.session() as session:
print("Neo4j に接続しました")
# 既存のデータをクリア
session.run("MATCH (n) DETACH DELETE n")
print("既存のデータを削除しました")
# 登場人物を作成
session.run(
"""
CREATE (momotaro:Character {name: '桃太郎', role: '主人公', type: '人間'})
CREATE (ojiisan:Character {name: 'おじいさん', role: '育ての親', type: '人間'})
CREATE (obaasan:Character {name: 'おばあさん', role: '育ての親', type: '人間'})
CREATE (inu:Character {name: '犬', role: '仲間', type: '動物'})
CREATE (saru:Character {name: '猿', role: '仲間', type: '動物'})
CREATE (kiji:Character {name: '雉', role: '仲間', type: '動物'})
CREATE (oni:Character {name: '鬼', role: '敵', type: '妖怪'})
"""
)
print("登場人物を作成しました")
# 場所を作成
session.run(
"""
CREATE (mura:Place {name: '村', description: '桃太郎が育った場所'})
CREATE (onigashima:Place {name: '鬼ヶ島', description: '鬼が住む島'})
"""
)
print("場所を作成しました")
# リレーションシップを作成
session.run(
"""
MATCH (momotaro:Character {name: '桃太郎'})
MATCH (ojiisan:Character {name: 'おじいさん'})
MATCH (obaasan:Character {name: 'おばあさん'})
MATCH (inu:Character {name: '犬'})
MATCH (saru:Character {name: '猿'})
MATCH (kiji:Character {name: '雉'})
MATCH (oni:Character {name: '鬼'})
MATCH (mura:Place {name: '村'})
MATCH (onigashima:Place {name: '鬼ヶ島'})
// 育ての親の関係
CREATE (ojiisan)-[:RAISED {relation: '育ての親'}]->(momotaro)
CREATE (obaasan)-[:RAISED {relation: '育ての親'}]->(momotaro)
// 仲間の関係(きびだんごで仲間になった)
CREATE (inu)-[:JOINED {kibidango: 1, skill: '嗅覚'}]->(momotaro)
CREATE (saru)-[:JOINED {kibidango: 1, skill: '身のこなし'}]->(momotaro)
CREATE (kiji)-[:JOINED {kibidango: 1, skill: '空からの偵察'}]->(momotaro)
// 戦いの関係
CREATE (momotaro)-[:FOUGHT {result: '勝利'}]->(oni)
CREATE (inu)-[:FOUGHT {result: '勝利'}]->(oni)
CREATE (saru)-[:FOUGHT {result: '勝利'}]->(oni)
CREATE (kiji)-[:FOUGHT {result: '勝利'}]->(oni)
// 場所の関係
CREATE (momotaro)-[:BORN_AT]->(mura)
CREATE (ojiisan)-[:LIVES_AT]->(mura)
CREATE (obaasan)-[:LIVES_AT]->(mura)
CREATE (oni)-[:LIVES_AT]->(onigashima)
CREATE (momotaro)-[:TRAVELED_TO]->(onigashima)
"""
)
print("関係性を作成しました")
result = session.run(
"MATCH (c:Character) RETURN c.name as name, c.role as role ORDER BY c.role"
)
print("\n登場人物:")
for record in result:
print(f" - {record['name']} ({record['role']})")
result = session.run(
"""
MATCH (c:Character)-[r:JOINED]->(momotaro:Character {name: '桃太郎'})
RETURN c.name as name, r.kibidango as kibidango, r.skill as skill
"""
)
print("\n桃太郎の仲間:")
for record in result:
print(
f" - {record['name']} "
f"(きびだんご: {record['kibidango']}個、特技: {record['skill']})"
)
result = session.run(
"""
MATCH (c:Character)-[r:FOUGHT]->(oni:Character {name: '鬼'})
RETURN c.name as name
"""
)
print("\n鬼と戦った者:")
for record in result:
print(f" - {record['name']}")
print("\nサンプルデータの作成が完了しました!")
finally:
driver.close()
if __name__ == "__main__":
create_sample_data()
クエリのサンプルコード
import os
from dotenv import load_dotenv
from neo4j import GraphDatabase
def query_sample_data() -> None:
"""
データに対してクエリを実行する.
"""
# 環境変数を読み込み
load_dotenv()
uri = os.getenv("NEO4J_URI", "bolt://localhost:7687")
user = os.getenv("NEO4J_USER", "neo4j")
password = os.getenv("NEO4J_PASSWORD", "password")
# Neo4j に接続
driver = GraphDatabase.driver(uri, auth=(user, password))
try:
with driver.session() as session:
print("Neo4j に接続しました\n")
# 1. すべての登場人物を取得
print("=== すべての登場人物 ===")
result = session.run(
"""
MATCH (c:Character)
RETURN c.name as name, c.role as role, c.type as type
ORDER BY c.role
"""
)
for record in result:
print(f"{record['name']} - {record['role']} ({record['type']})")
# 2. 桃太郎の仲間を検索
print("\n=== 桃太郎の仲間 ===")
result = session.run(
"""
MATCH (c:Character)-[r:JOINED]->(momotaro:Character {name: '桃太郎'})
RETURN c.name as name, r.skill as skill, r.kibidango as kibidango
"""
)
for record in result:
print(
f" - {record['name']} (特技: {record['skill']}, "
f"きびだんご: {record['kibidango']}個)"
)
# 3. 人間のキャラクターを検索
print("\n=== 人間のキャラクター ===")
result = session.run(
"""
MATCH (c:Character {type: '人間'})
RETURN c.name as name, c.role as role
"""
)
for record in result:
print(f" - {record['name']} ({record['role']})")
# 4. 鬼と戦った登場人物を検索
print("\n=== 鬼と戦った登場人物 ===")
result = session.run(
"""
MATCH (c:Character)-[r:FOUGHT]->(oni:Character {name: '鬼'})
RETURN c.name as name, r.result as result
"""
)
for record in result:
print(f" - {record['name']} (結果: {record['result']})")
# 5. 桃太郎を育てた登場人物を検索
print("\n=== 桃太郎を育てた登場人物 ===")
result = session.run(
"""
MATCH (c:Character)-[r:RAISED]->(momotaro:Character {name: '桃太郎'})
RETURN c.name as name, r.relation as relation
"""
)
for record in result:
print(f" - {record['name']} ({record['relation']})")
# 6. 各場所に関連する登場人物
print("\n=== 場所と登場人物の関係 ===")
result = session.run(
"""
MATCH (c:Character)-[r]->(p:Place)
RETURN c.name as character, type(r) as relation_type, p.name as place
"""
)
for record in result:
relation_ja = {
"BORN_AT": "生まれた",
"LIVES_AT": "住んでいる",
"TRAVELED_TO": "旅した",
}
relation = relation_ja.get(record["relation_type"], record["relation_type"])
print(f" - {record['character']} は {record['place']} に{relation}")
# 7. 桃太郎から鬼へのリレーションシップの経路
print("\n=== 桃太郎から鬼への関係性 ===")
result = session.run(
"""
MATCH path = (momotaro:Character {name: '桃太郎'})-[*]-(oni:Character {name: '鬼'})
WHERE length(path) <= 2
WITH path, length(path) as len
ORDER BY len
LIMIT 3
RETURN [node in nodes(path) | node.name] as characters,
[rel in relationships(path) | type(rel)] as relations
"""
)
for record in result:
chars = record["characters"]
rels = record["relations"]
path_str = chars[0]
for i, rel in enumerate(rels, 1):
if i < len(chars):
path_str += f" -[{rel}]-> {chars[i]}"
print(f" {path_str}")
# 8. タイプ別の登場人物の数
print("\n=== タイプ別の登場人物数 ===")
result = session.run(
"""
MATCH (c:Character)
RETURN c.type as type, count(*) as count
ORDER BY count DESC
"""
)
for record in result:
print(f" - {record['type']}: {record['count']}人")
# 9. 桃太郎のリレーションシップの数
print("\n=== 桃太郎の関係性 ===")
result = session.run(
"""
MATCH (momotaro:Character {name: '桃太郎'})-[r]-()
RETURN type(r) as relation_type, count(*) as count
"""
)
relation_ja = {
"RAISED": "育てられた",
"JOINED": "仲間になった",
"FOUGHT": "戦った",
"BORN_AT": "生まれた",
"TRAVELED_TO": "旅した",
}
for record in result:
relation = relation_ja.get(record["relation_type"], record["relation_type"])
print(f" - {relation}: {record['count']}件")
print("\nクエリの実行が完了しました!")
finally:
driver.close()
if __name__ == "__main__":
query_sample_data()
おわりに
本記事では、グラフデータベースNeo4jの基本的な使い方を紹介しました。
Neo4jは、Cypherやデータブラウザなどエコシステムが十分に発達しており、非常に使いやすいサービスだと思います。ベクトルデータのデータ形式にも対応しており、GraphRAGなどを自由度高く開発するための有効な選択肢だなと感じました。
今後は、Neo4jを使ったグラフRAG関連の事例なども紹介できればと考えています。
タイムラボでは、一緒に働ける仲間を募集しています。もし、この記事に興味を持たれた方、カレンダーサービスの開発に興味がある方、AIの活用に関心がある方などがいれば、ぜひ私のXアカウント(@hakoten)やコメントで気軽にお声がけください。
まずはカジュアルにお話できることを楽しみにしています!

Discussion