TIL (Things / Today I've learned)
atuinで異なる端末間で履歴を同期する時は、それぞれの端末で同じバージョンのatuinをインストールしている必要がある。
loginしてsyncしても全然履歴が同期されなかったんだけど、古い端末の方のatuinをバージョンアップしてバージョンを揃えたら同期した。
config
filter_mode = "directory"
1passwordを使ってるとssh鍵の引っ越しも不要で大変助かる。
スクリーンショットアプリ
macOS向けスクリーンショットアプリ。
Shottrは無料ですか?
Shottr は、好きなだけ無料で使用できます。ほとんどの機能は無料ユーザーでも利用できます。ただし、アプリが時々購入を検討するよう促すことがあります。Shottr は、一般的に、アクティブ化されたバージョンで全体的なエクスペリエンスが向上しており、今後は機能を追加して価格を上げる予定です。
https://shottr.cc/
無料版の制限?
- 画像編集で枠を描画する時、枠の色をプリセット以外に追加できない
スリープ設定管理アプリ
Amphetamine
モニターの電源を切らないとか、細かい設定がMacos標準機能ではできないので、このソフトウェアが必要。
クリップボード履歴
有料で高機能なアプリは色々あるけど、まずはこれで必要十分かと。
AWS IdentityCenter の 許可セットとグループとAWSアカウントの対応。
最初はなかなか理解が難しかったので絵にしてみた。

絵の都合上、一番上にAWSアカウントが来ているが実際に構築する順番は許可セットから。
以下の説明も下から読んだほうがわかりやすい。
AWSアカウント
グループ
許可セット
今zshだけどfishへの切り替えを検討したい
やっと出たかー!って感じのサービス。
マルウェア感染した拡張機能はここ最近よく聞くようになったし。
AWS IdentityCenter のIdpとしてOktaをセットアップした時のメモ。
わけあってOktaグループをTerraformで管理していたので、グループ情報の元データをどこ(リポジトリ)が持つ?という検討をした。
結果、tfstateはちょっと複雑になるということで、OktaとAWSの両方のリポジトリで同じグループを作成&参照することに。
| 概要 | 作業の順番 | 構成ファイル配置場所 | 対向からの参照方法 | 管理 | メリット | デメリット |
|---|---|---|---|---|---|---|
| AWS環境を先にデプロイして、その設定を元にOktaもデプロイする | AWSのリポジトリで設定ファイル作成 AWSデプロイ Oktaのリポジトリでremote_state参照してデプロイ Oktaの画面でグループに人をアサイン |
AWSのリポジトリ、tfstate | remote_state | AWSリポジトリ | カスタムポリシーの制御がしやすい | SCIMではなくTerraformでAWSにグループを作成する形になる コンソール上の見た目が「手動作成」になる |
| Oktaを先にデプロイしてAWSにグループができた状態で、AWSの許可セットとかを作る | Oktaのリポジトリで設定ファイル作成 Oktaデプロイ Oktaの画面でグループに人をアサイン SCIMでグループ作成 (Oktaのremote_stateを参照する) AWSデプロイして、AWSアカウントとグループを関連付けする |
Oktaのリポジトリ、tfstate | remote_state | Oktaリポジトリ | AWS画面でグループ作成が「SCIM」になる 流れが自然 |
OktaのリポジトリでAWSの許可セットなどを管理することになる 個別ポリシーとか出てくるとまためんどくさい |
| 同じ設定ファイルを参照するのを行わず、AWSとOktaでそれぞれデプロイする | Oktaのリポジトリで設定ファイル作成 Oktaデプロイ Oktaの画面でグループに人をアサイン SCIMでグループ作成 AWSのリポジトリで設定ファイルを作成 AWSデプロイして、AWSアカウントとグループを関連付けする |
AWSのリポジトリ Oktaのリポジトリ |
無し | AWSのリポジトリ Oktaのリポジトリ |
AWSとOktaの両方に不要な設定を保持することが無くなる それぞれのリポジトリに必要な設定があるので、はじめて見た人にわかりやすい |
同じグループ名の設定をOktaとAWSの両方の設定ファイルで行う必要がある Oktaに作成したグループ名と同じグループ名をAWS側でも手作業で設定する必要がある |
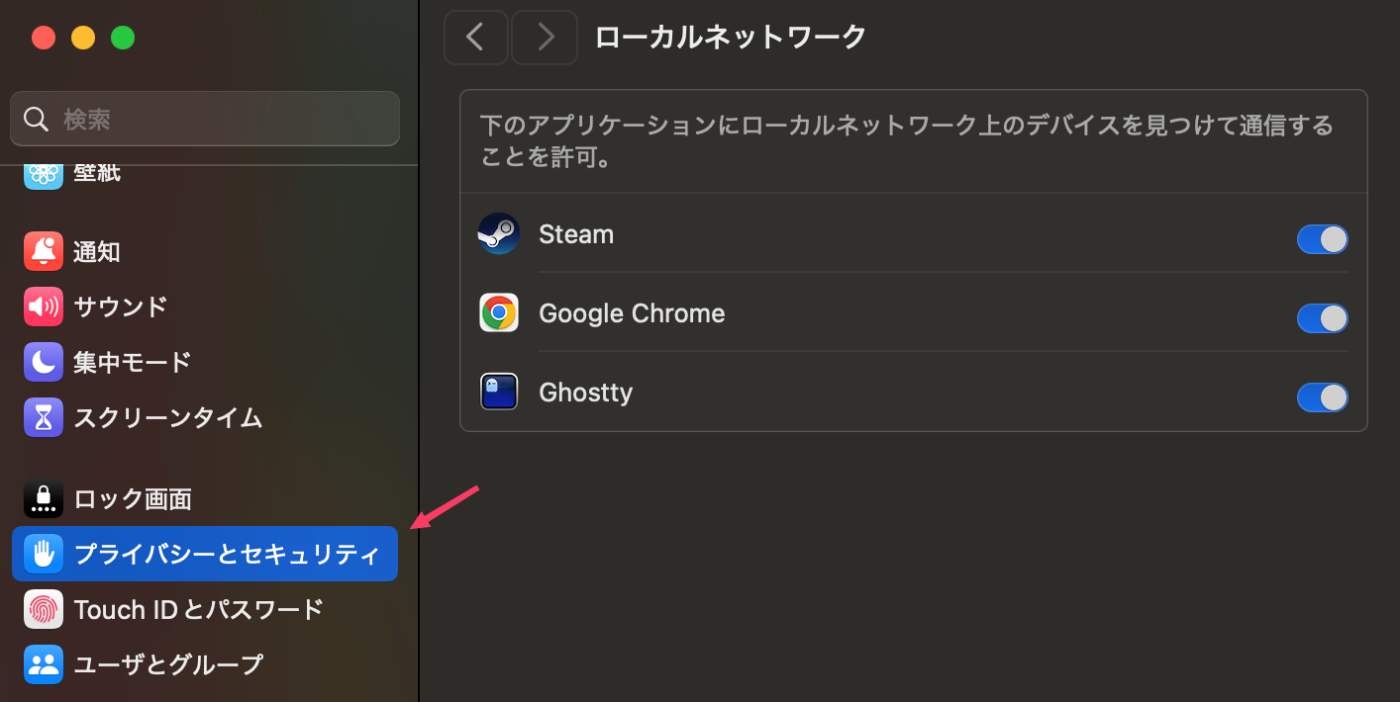
同じLANにあるRaspberryPiの管理画面が表示できなくなってしまった。
セキュリティの設定にローカルネットワークというのが増えていて、Chromeにチェックが入ってないことが原因だった。
IAM Identity CenterのIdpの話。
アイデンティティソースを変更する際の考慮事項のページでActive Directoryへの切替だけ独立した章立てがされていて、この場合はアクセスポータルのURLも変わるらしい。
アクセスポータルの URL が変更されます– IAM Identity Center と Active Directory 間で ID ソースを変更すると、AWS アクセスポータルの URL も変更されます。
この違いはよくわからないけど、IAM Identity Centerの画面でも明確に分かれている。

Active Directory(Microsoft Entra IDとも異なる?)だけなんか特殊なんだなぁという感想。
Workers AI で画像生成したくなったので、提供されているモデルをChatGPTに整理してもらった。
| モデル名 | 元の解説 (日本語訳) | 追加解説 |
|---|---|---|
| dreamshaper-8-lcm | Stable Diffusionモデルで、フォトリアリズムを向上させつつ、幅広い表現力を維持するようにファインチューニングされています。 | フォトリアリズムを重視した画像生成を求めるユーザーに適しており、アートスタイルからリアルな人物・風景まで幅広く対応できます。 |
| flux-1-schnell | FLUX.1 [schnell]は、12B(120億)パラメータを持つ修正フロー変換モデルで、テキストの説明から画像を生成することができます。 | 修正フロー変換(Rectified Flow Transformer)を採用することで、安定した高品質な画像生成が可能です。生成スピードが速い点が特徴です。 |
| stable-diffusion-v1-5-img2img | Stable Diffusionは、潜在テキスト・画像変換拡散モデルで、フォトリアルな画像を生成できます。Img2imgは、入力画像を基に新しい画像を生成する機能です。 | 既存の画像を加工・変換する用途に適しており、リファイン(修正)やイラストのスタイル変更などに活用されます。 |
| stable-diffusion-v1-5-inpainting | Stable Diffusion Inpaintingは、潜在テキスト・画像変換拡散モデルで、テキスト入力を基にフォトリアルな画像を生成できます。さらに、マスクを使用して画像の一部を補完するインペインティング機能を持ちます。 | 画像の一部を修正・置き換えするのに適しており、写真の不要な要素の削除や、破損した画像の復元に利用できます。 |
| stable-diffusion-xl-base-1.0 | Stability AIによる拡散ベースのテキスト・画像生成モデル。テキストプロンプトを基に画像を生成および編集できます。 | Stable Diffusionの進化版で、解像度や細部の表現力が向上しています。商業利用や高度なクリエイティブ作業にも適しています。 |
| stable-diffusion-xl-lightning | SDXL-Lightningは、超高速のテキスト・画像生成モデルです。数ステップで高品質な1024px画像を生成できます。 | 高品質な画像を短時間で生成できるため、リアルタイム用途やプロトタイピングに適しています。 |
Oktaと似たような製品で無料で使えるサービスなにかあるかと探したらAuth0が該当するっぽい。
| 機能 | Auth0 | Okta |
|---|---|---|
| MFA機能 | - プッシュ通知、SMS、音声通話、OTP対応 | - プッシュ通知、SMS、音声通話、OTP対応 |
| - アダプティブMFA対応 | - アダプティブMFA対応 | |
| - リスクベース認証のポリシー設定可能 | - リスクベース認証のポリシー設定可能 | |
| SAML連携 | - SAML認証対応、Active Directory統合可能 | - 7,000以上の事前構築済みSAML統合 |
| - カスタム統合構築可能 | - 1,400以上のSAML / OpenID Connect統合 | |
| SCIM連携 | - SCIM 2.0対応 | - SCIMプロビジョニング対応 |
| - ユーザーの作成・更新・削除の自動化可能 | - ユーザーデータの同期と管理が可能 |
Dify
プロンプト構築
DifyにはJinja2ノードがあるがワークフロー全体でのバージョン管理がされていないため、プロンプトだけ前のバージョンに戻したいとか、前のバージョンとどこが変わったとかの管理が難しい。
少し使ってみた感じpromptlayerが結構いい感じ。
公式のプラグインは無いけれど、REST APIが提供されているのでHTTPノードで取得してJSON Processツールで抽出してあげるとよい。
会話履歴
Difyには標準で「メモリ」機能がありシステムプロンプトのサイズを見て、LLMが受け入れるコンテキストの最大数まで過去履歴を挿入してくれる。(明示的に件数を入れることも可能)
だが大体の場合、LLMに送信する履歴は最低限のテキストのみが良しとされるので、自前で履歴を実装したほうがよい。
自力実装
json文字列をオブジェクト配列変数に代入(Append)する処理の参考になる。
import json
def main(arg1: str) -> object:
try:
# Parse the input JSON string
input_data = json.loads(arg1)
# Extract the memory object
memory = input_data.get("memory", {})
# Construct the return object
result = {
"facts": memory.get("facts", []),
"preferences": memory.get("preferences", []),
"memories": memory.get("memories", [])
}
return {
"mem": result
}
except json.JSONDecodeError:
return {
"result": "Error: Invalid JSON string"
}
except Exception as e:
return {
"result": f"Error: {str(e)}"
}
mem0
Difyは会話履歴からサマリを作成する管理する機能が無いので、こういうのを使うといいのかも。
mem0
MCP
ゲームできるといいなぁ。
Newrelicにnomadコンテナのログを転送する
Newrelicブログにコンテナログの取得と解析ルールの設定について書かれていたので、Nomadで動かしているコンテナに向けて設定してみた。
前提知識
Nomadでコンテナを動かした場合のコンテナ名は {taskName}-{allocId}が設定される。
コンテナには {taskName}-{allocId}という名前が付けられます。
これは、同じタスクから複数のコンテナをホストに配置するために必要です (例: count > 1)。
これは、各コンテナの名前がクラスター全体で一意であることも意味します。
nomad設定
loggingに関する箇所のみ抜き出したコンフィグが以下の通り。
tagにはNomadのMetadata変数を設定。
job "sample" {
group "apiserver" {
task "server" {
driver = "docker"
config {
logging {
type = "json-file"
config {
max-size = "5m"
max-file = "2"
tag = "${NOMAD_JOB_NAME}-${NOMAD_GROUP_NAME}-${NOMAD_TASK_NAME}"
}
}
}
}
}
}
Newrelic設定
ブログに解析ルールの設定画面へ到達する方法が書かれていなかったのでメモ。

参考
感想
久しぶりにNR触ると、アラートの作り方からアラートポリシーの作り方から全部忘れててつらい。
ZabbixのHA設定を説明しているウェブサイトは幾つかあるけど、どこもZBX_AUTOHANODENAMEに触れていないのはなんでだろう。
Google検索してもZBX_AUTOHANODENAMEについてはほとんどヒットしない。
EC2インスタンスにZabbixを構築しているとホスト名は固定されいなことがほとんどだと思うので必須設定に思える。
設定してみたら普通に動作したので、みなさん便利に使うとよいかと思いました。
所得税と消費税の支払い。
クレジットカード支払いは手数料が高額なので、ネットバンキング支払が良い。
e-TAXへのログインが手間そうに見えるけど、マイナポータルからe-TAXにログインしてお知らせのリンクからネットバンキング支払を選ぶと簡単。
納付番号とかがうまいこと連携されてネットバンクのログインができればタップしているだけで納付完了する。
本に移動。
Gemini
上限

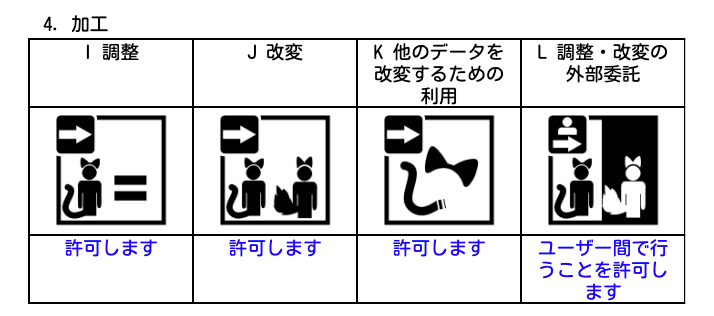
BOOTHで販売されている3Dモデルの規約。
「L 調整・改変の外部委託」の項目に設定される「ユーザー間で行うことを許可します」が非常にわかりにくい。
選択肢
まず規約を作る側の選択肢としては次の選択肢がある。
・許可します
・ユーザー間で行うことを許可します
許可しますとは別に「ユーザー間で行うことを許可します」がある。
「ユーザー間で行うことを許可します」が選択されていた場合はなんらか制限を適用したい意図が読み取れる。

「ユーザ」とは
「ユーザー間で行うことを許可します」が選択されていた場合は、「ユーザ」について理解する必要がある。
「ユーザー」
個人または法人のいずれかであるかを問わず、正規の方法での購入や正規の方法でのダウンロードなどにより、権利者または権利者の指定する第三者から本データを正当に入手した者。
https://docs.google.com/document/d/1r5exLnCwh1Bny-cH1ZPrjIX8wrnfDfZspCQq1b92ZYo/edit?tab=t.0
平たく言うと「お金を出してアバターを買ったひと」のことと理解した。
改変を委託する場合
髪型の変更や衣装変更を1,000円くらいで対応してくれる大変ありがたいクリエイターの方々がいるが、「ユーザー間で行うことを許可します」が選択されている規約のモデルを改変委託する場合、クリエイターが編集するモデルも依頼者側で負担する必要がある。
そのため改変委託にかかる費用として、モデルの費用が5,000円だと委託者5,000円+請負側5,000円+作業費1,000円で合計11,000円かかる。
感想
確かに「ユーザー間で行うことを許可します」を選択しておかないと、改変委託と称してモデルの無制限受け渡しが実現してしまうので制限したくなる気持ちはわかるがモデルは改変前提になっている背景もあるため双方良い形があればなぁと思う。
改変サービスを探す中で、Discordで画面共有しながら改変のお手伝いをしますというサービスを幾つか見かけたが、こういう背景があるからかなーと納得した。
例えば、UnityWebみたいなサービスができて、そこにモデルを入れて作業権限のみを委託先へ付与できると、このあたりの問題が解決しそうな気がする。
3DモデルをVRChat(FBX)形式からVRM0.X(VRM1.0)に変換してみた感想。
結論としては、XWear Packagerを使ったXAvatar経由のVRM変換が一番簡単だった。
リンク先の記事に「VRM1.0のみ出力」がデメリットとして記載されていますが、VRMRemakerを用いることでVRM1.0からVRM0.Xへの変換が可能です。
その他の方法
いわゆるUniVRM(とそれを支援するツールを)を使う方法は揺れものの設定(SpringBoneColliderなど)と表情(BlendShape)の設定は手作業として残るため、これが非常に手間だった。
VRMConverterForVRChatを用いると表情部分と揺れものの下準備はかなり実施してくれるが、揺れものの設定がすべて詰め込まれたsecondaryを再設定していく作業も非常に手間だった。
感想
今回はモデルをロードする先がVRM0.Xしか対応していないためVRM0.Xをゴールとしたが、できればVRM1.0を採用できるよう動いていくのが苦労しない道なんだろうなと思った。
あと、どの方法にしてもUnityへのパッケージインポートがそれなりに発生するんだけど、このあたりnodejsのpackage.jsonみたいなのが整備されてnpm installで全部インストールされるような仕組みができると解説記事書くひとも楽なんじゃないかなーと。
BOOTHで売ってるモデルがVRChat(FBX)形式が多いのも意外だった。
外部プログラムから色々操作する面でVRMが非常に便利なんだけど、みんなはそんな用途よりもVRChatでわいわいやるのに使うモデルのほうが需要あるんだぁと。

AivisSpeech
スタイルとプリセットがある。

スタイルはAIVM / AIVMX ファイルに事前定義されている「幸せ」「悲しい」とかの感情。
プリセットは音声合成画面で変更できる「話速」や「スタイルの強さ」など。
正直、スタイルを変更しても音声にはあまり変化は無くて、自分好みの音声にしたい時にはプリセットを編集することになる。
このプリセットはaudio_queryで作成したクエリの中に埋め込まれる。
{
<snip>
"speedScale": 1,
"intonationScale": 1,
"tempoDynamicsScale": 1,
"pitchScale": 0,
"volumeScale": 1,
"prePhonemeLength": 0.1,
"postPhonemeLength": 0.1,
"pauseLength": null,
"pauseLengthScale": 1,
"outputSamplingRate": 44100,
"outputStereo": false,
"kana": "こんにちは"
}
https://qiita.com/aqua_ix/items/196b235e83798b8c3631#%E9%9F%B3%E5%A3%B0%E5%90%88%E6%88%90%E3%81%AE%E3%83%AA%E3%82%AF%E3%82%A8%E3%82%B9%E3%83%88
ChatdollKitに入門してみる。
プロジェクトテンプレート
UnityのSRP (Scriptable Render Pipeline) プロジェクトテンプレートは使用しないでください。

3D Built-in Render Pipeline を選ぶ。
必要パッケージのインストール
ほとんどのパッケージはUPMでインストールできる。
| パッケージ名 | インストール | URL |
|---|---|---|
| Burst | UPM | com.unity.burst |
| JSON.NET | UPM | com.unity.nuget.newtonsoft-json |
| UniTask | UPM | https://github.com/Cysharp/UniTask.git?path=src/UniTask/Assets/Plugins/UniTask |
| uLipSync | UPM | https://github.com/hecomi/uLipSync.git#upm |
| com.vrmc.gltf | UPM | https://github.com/vrm-c/UniVRM.git?path=/Assets/UniGLTF#v0.127.2 |
| UniVRM (v0.127.2) | UPM | https://github.com/vrm-c/UniVRM.git?path=/Assets/VRM#v0.127.2 |
| Azure Speech SDK (オプション) | UPM | com.microsoft.cognitiveservices.speech |
| ChatdollKit VRM Extension |
.unitypackage | https://github.com/uezo/ChatdollKit/releases |
| ChatdollKit | .unitypackage | https://github.com/uezo/ChatdollKit/releases |
AivisSpeech のプリセット指定
いい方法が思いつかなかったので /ChatdollKit/Scripts/SpeechSynthesizer/VoicevoxSpeechSynthesizer.cs の中でごりっと書き換え。
// JSONをパースし、プリセットの値を変更
var preset = Newtonsoft.Json.Linq.JObject.Parse(audioQuery);
preset["speedScale"] = 0.95; // 話速
preset["intonationScale"] = 2.00; // スタイルの強さ
preset["tempoDynamicsScale"] = 0.80; // テンポの緩急
preset["pitchScale"] = 0.00; // 音高
preset["volumeScale"] = 1.00; // 音量
preset["prePhonemeLength"] = 0.10; // 開始無音(秒)
preset["postPhonemeLength"] = 0.10; // 終了無音(秒)
audioQuery = preset.ToString();
Anim
外部制御アプリ
ChatdollKit AITuber Controllerを使って外部から制御するアプリを作る場合。

OpenAIの無料枠来てた。

lobehubはLLMのフロントエンドでした。
Auth0 AWS
Auth0をAWS IAM Identity Center の Idp として使えないか軽く検証してみた。
結論としては使えないだった。
auth0がもともとアプリケーション向けの認証サービスなので、SAML連携はおまけくらいの機能っぽい。なので設定UIもあまり洗練されていないし、手順書も不親切な部分が多かった。
このあたりは設定する人ががんばればいいので、そんなに欠点ではないけど。
使えないと判断したポイントはSCIM(Systems for Cross-domain Identity Management)を使ったユーザ情報の同期ができないこと。
Idpと連携する目的って単純なSSOだけじゃなくて、退職したユーザを関連システムから確実に削除するとか、ユーザがいつどこから関連システムにログインしたかを追いかけるとかのセキュリティ要素が期待値として多くあるので、このあたりを満たせそうにないAuth0は足りないかなぁと。
だったらもうAWS IAM Identity Center の Identity Center ディレクトリ でいいかなぁみたいな判断。
手順
スクリーンショットメモ



IAMユーザのMFA
IAMは、USB、Bluetooth、NFC経由でデバイスに接続するFIDO2セキュリティデバイスをサポートしています。また、TouchIDやFaceIDなどのプラットフォーム認証もサポートしています。
https://docs.aws.amazon.com/IAM/latest/UserGuide/id_credentials_mfa_fido_supported_configurations.html#id_credentials_mfa_fido_supported_devices
と書いてあるのに、ToutchIDが選択肢に出てこないのはなんでだろうねぇ。
iCloudキーを設定していないから?
Unity Behavior
[Unity] ビヘイビアでターン制バトルの思考ルーチンをグラフで組めるようにしてみた #C# - Qiita
【Unity】Unity謹製ビヘイビアツリー「Unity Behavior」の使い方まとめ - LIGHT11
UnityのBehaviorパッケージを使って敵のAIを作ってみる #Unity6 - Qiita
AIを使った対人コミュニケーションアプリを作っていると、多くの人が「AIはリアルタイムに学習する」と思い込んでることに気づく。
多くの人がイメージしている学習はLLMの世界でいうfine tuningが該当すると思う。
でも、fine tuningにはコンピューティングリソースが必要だし、時間もかかるのでリアルタイムに行うというのはかなり非現実的。
でも、AIとは会話が成り立つしなんとなく前に話したことを覚えているような気がするのはプロンプトに過去の会話や履歴を反映しているから。
AIはLLM(モデル)とプロンプトで構成されていて、それぞれはまったく異なるもの。
LLMへの介在は非常に難しい反面、プロンプトの修正は簡易に行うことができる。
プロンプトもSYSTEMプロンプトとUSERプロンプトに分かれていて、それぞれ用途は全く異なる。
USERプロンプトには利用者の発話のみを含むのが当たり前のように思えるけど、そうではなく例えば必ず遵守させたいことのように重要度や、変化せずキャッシュされやすい情報という意味でSYSTEMを選択し、大してそれなりに変更のある内容をUSERに含めるなど。
なかなか奥が深くて面白い。
CloudflareのAutoRAGを使ってみた。
- 読み込ませるデータの整理大事
- JSONが良かった
- jsonlもRAGと相性良いと思うので対応してほしい
- https://developers.cloudflare.com/autorag/configuration/data-source/#file-types
- クエリの書き換え大事そうなんだけど、設定画面で書き換えたクエリが反映されない
- プレイグラウンドで試したクエリの詳細はAI Gatewayの画面で確認できる
- 左のメニューに有る
- ログを確認しても設定したクエリが反映されていない
一晩使ってみたけど、すっごい遅いな。
クエリ変換が遅いのか検索が遅いのか。
- ローカルで動かしたいアプリはDockerコンテナにしてHahsicorp Nomadで動かしていた
- fastapi+uvicornで作った軽いアプリをわざわざコンテナにするのがめんどくさかった
- fastapi+uvicornで作ったアプリのデプロイ先としてpikuがとても良かった
RAG色々
weaviate
- 重すぎ
- docker composeでローカル起動した環境にはWebGUIが無い
Qdrant
- ちょうど良い
- FastEmbedめっちゃ早い
- モデルはsentence-transformers/paraphrase-multilingual-MiniLM-L12-v2が良い
2.0と2.5でFew-shotの扱いが変わったらしい。
こういうの追いかけるの難しいなぁ。
🔍 Gemini 2.0 で Few-shot が有効だった理由
1. 指示追従性能が2.5より弱かった
• Gemini 2.0はGemini 2.5ほど「ゼロショット指示の厳密な遵守」が強くなかったため、Few-shotを見せることで文体・フォーマットの学習を強制する必要がありました。
2. 応答がフォーマル寄りになりやすかった
• 2.0では、ルールだけだと硬い文章になりがちで、「独り言」「間投詞」などの自然さをFew-shotで補う必要がありました。
3. 速度とコストのトレードオフがまだ許容範囲だった
• Gemini 2.0のレイテンシがそもそもやや長めだったため、Few-shot削減での速度改善インパクトがそこまで大きくなかった。
⸻
🔥 Gemini 2.5 Flashで変わった点
• 指示追従精度が向上 → Few-shot無しでもフォーマット遵守が安定。
• 短文応答タスクに最適化 → Few-shotを入れるとトークン増でむしろ遅延が顕著。
• ゼロショット+明確ルール記述でほぼ期待通りに動作。
⸻
✅ まとめ
• Gemini 2.0 → Few-shot推奨(特に文体模倣・形式遵守のため)
• Gemini 2.5 Flash → ルール駆動+必要最小限Few-shotが最速安定
最近の気付きをGPT-5さんに整理してもらった。
IAMポリシーの Statement が評価される順序を理解する
AWS IAMポリシーの挙動で「Conditionが効いていない?」「Resourceを*にすると動く…?」という現象に遭遇したことはないでしょうか。
これは Statement 内での評価順序 を理解すると納得できます。
評価の基本ルール
AWSはリクエストを評価する際、複数のポリシーを統合して次の順序で判定します。
"By default, all requests are implicitly denied. An explicit allow overrides this default. An explicit deny overrides any allows."
— IAM JSON policy evaluation logic
つまり、
- 暗黙の拒否(Implicit Deny)が基本
- 明示的なDenyがあれば即拒否
- 明示的なAllowがあれば許可
- それ以外は拒否
Statement単位での内部評価フロー
IAMは1つのStatementを評価するとき、以下の順でフィルタリングします。
1. Action の一致確認
リクエストされたAPIアクションが Action または NotAction に一致しなければ、そのStatementは評価対象外になります。
"The Action element describes the specific action or actions that will be allowed or denied."
— Action element description
2. Resource の一致確認
次にリソースARNの一致を確認します。
ここで重要なのは、アクションがリソースレベルアクセスに対応しているかどうかです。
"If an action does not support resource-level permissions, you must specify a wildcard (*) for the resource element."
— Resource element
たとえば ec2:DescribeInstances はリソースレベル非対応なので、Resource が "*" でないと必ず不一致になり、Conditionの評価に進みません。
3. Condition の評価
ActionとResourceが一致した場合のみConditionが評価されます。
"When a policy has multiple conditions, all conditions must be met for the policy to match (logical AND). If a single condition operator contains multiple values, only one of the values must match (logical OR)."
— Condition element
- 異なるキーはAND
- 同じキーの複数値はOR
-
IfExistsを使うと、キーが存在しない場合はスキップしてtrue扱い
4. Effect の適用
-
Denyなら即拒否(他のAllowは無視) -
Allowなら許可候補として保持(他にDenyがなければ許可)
不整合でConditionに到達しない例
{
"Effect": "Allow",
"Action": "ec2:DescribeInstances",
"Resource": "arn:aws:ec2:ap-northeast-1:123456789012:instance/i-*",
"Condition": {
"StringEquals": {
"ec2:ResourceTag/Env": "prod"
}
}
}
ec2:DescribeInstances はリソースレベル非対応なので、Resource が "*" 以外の場合は一致せず、Conditionは評価されません。
まとめ
IAMポリシーのStatementは内部的に次の順で評価されます。
- Action一致? → Noなら終了
-
Resource一致? → Noなら終了(リソースレベル非対応アクションは
*必須) - Condition一致? → Noなら終了
- Effect適用(Deny優先)
これを理解すると「Resource: "*" にしたら動いた」現象の原因が見えやすくなります。多くの場合、ActionとResourceの組み合わせが不適切で、Conditionに到達していないケースです。
difyにはプロンプト構築の機能はほぼ無いに等しいので、自作してるんだけど、そしたらdifyのワークフローだいぶシンプルになった。
pikuでDenoアプリ(フレームワークはFresh)も普通にデプロイできた。
Procfileは普通。
release: deno task manifest && deno task build
web: deno run -A main.ts
"名もなきモーション"とか"Mixamo"とかでダウンロードできるFBXはRigがGenelicになっている。
Unityで扱うにはHumanoidに変換する必要がある。
手順は以下の通り。
Humanoid に変換する手順
1. FBX を Project にインポート(D&D)
- Assets/Animations/Mixamo/ などに配置。
- ***.FBXを選択してInspectorに表示する
2. Inspector > Rig タブを開く
- Animation Type を Generic → Humanoid に変更。
- Avatar Definition: Create From This Model を選択。
- Apply を押す。
3. Configure… をクリック
- ボーンの割り当て画面が開きます。
- Mixamo FBX は基本的に標準的な人型ボーン名なので、ほぼ自動で緑チェックになります。
- 手や指が赤/黄色の場合は「Assign」して補正。
- 完了したら Apply → Done。
4. Animation タブでクリップ確認
- アニメーションの開始・終了フレームを確認。
- 必要なら Loop Time ON。
- Root Transform の Y を Bake Into Pose ON にして足のめり込みを防ぐ。
5. .anim 抽出(任意)
- FBX 内蔵アニメを Project の Assets/Animations/Clips/ にドラッグして抽出しておくと管理が楽。
6. Animator Controller に登録
- .anim を Animator Controller に追加 → キャラクターの Animator に適用。
Githubでレビュー対象のPRが並んだダッシュボード画面。
上から変更の少ない順に並んで欲しい。
どう考えても小さくまとまったPRのほうが優秀なので、ちゃんとそれを実現しているPRが優先的にレビューされるべきだと思う。
考慮されたPRを優先的に終わらせて、余った時間で大きくて雑なPRを見るみたいな感じでいいじゃないかと思う。
ーーー
同時に、PR滞留時間も観測したいね。
ずっとレビュー待ちにいるPRとかだいたい・・・