IMEに漢検熟語を一気に登録してみた
Win11のMicrosoft日本語IMEで行いました。
きっかけ
私は個人的に漢字検定を嗜んでいます。
そのため、普通使われないような語を自分用のメモなどには定期的に用いるのですが、
使われないことが災いし、変換しても目的の熟語が出てこない時がよくあります。
しばらくはそのことを受け入れていたのですが、
IMEに一気に熟語をユーザー登録すれば解決するのではないかということに私は気づきました。
備忘録も兼ねて、やり方を記事にしましたので、同じことをやりたいが上手くいかないという方の助けになれたらと思います。
やり方
使用したもの
- 漢字逞筆様のExcelファイル
- Excel
- 文字コードを変換できるエディタ
Excelファイルを用意
まず、漢字逞筆様の
問題一覧ページから、音読みのExcelファイルをダウンロードします。

Excelファイルをダウンロード

中身はこんな感じ
これを、以下図のように、
読み(ひらがな) -> 熟語(漢字) -> 名詞 の順に、
移してください。
テキストだけコピー&ペーストし、「名詞」と一括入力すれば10秒で終わります。

後でコピー&ペーストします。
テキストファイルを作成
ここで、適当な場所に新しくテキストファイルを作成してください。
(デスクトップで構いません)
そしてこれを文字コードの変換が可能なエディタで開き、
文字コードをUTF16-LEにして、先ほどのExcelの内容をコピーして保存してください。
例としてVSCodeで説明します。
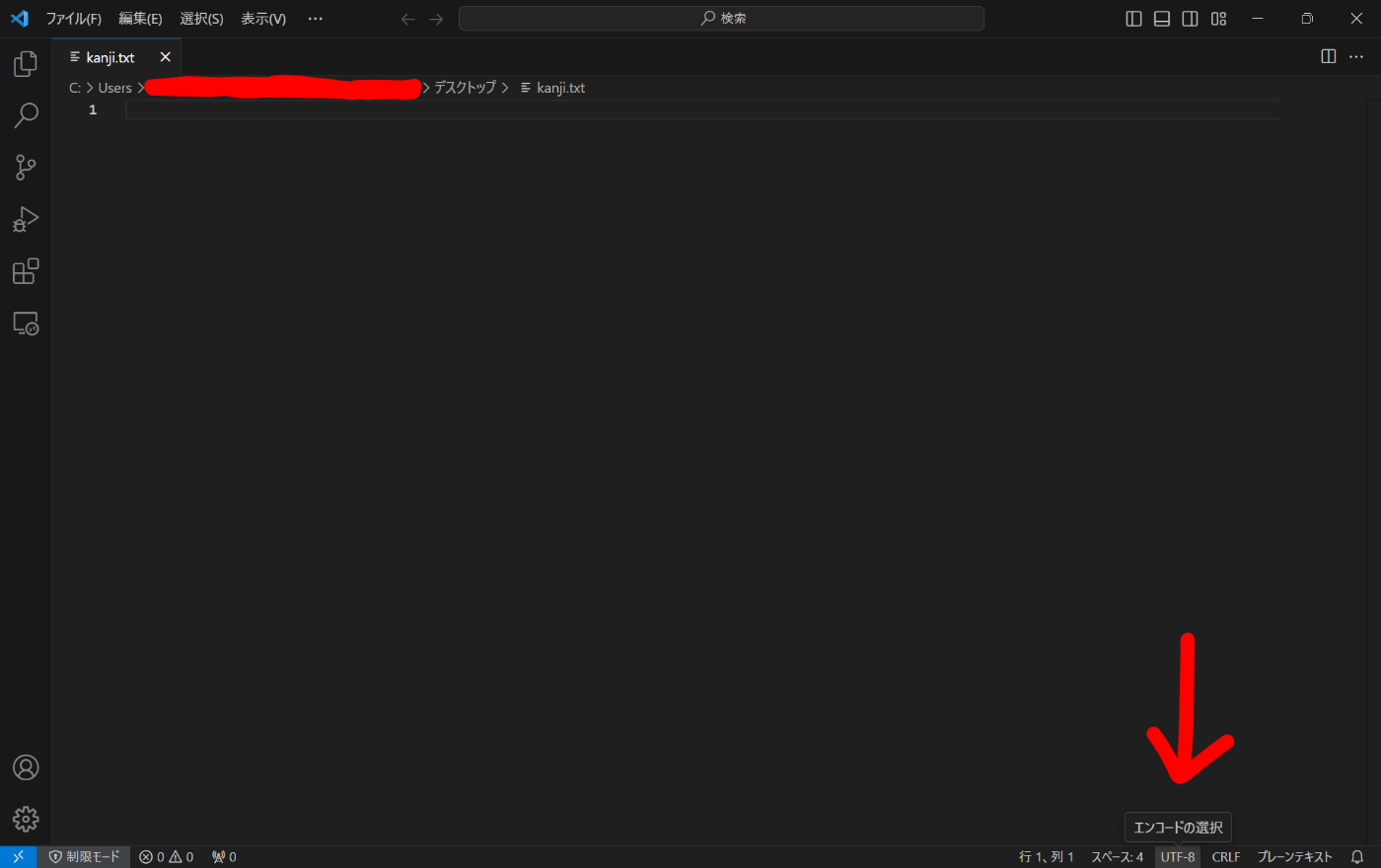
右下の文字コードの表示を押す

エンコード付きで再度開く
UTF16-LEを選択する
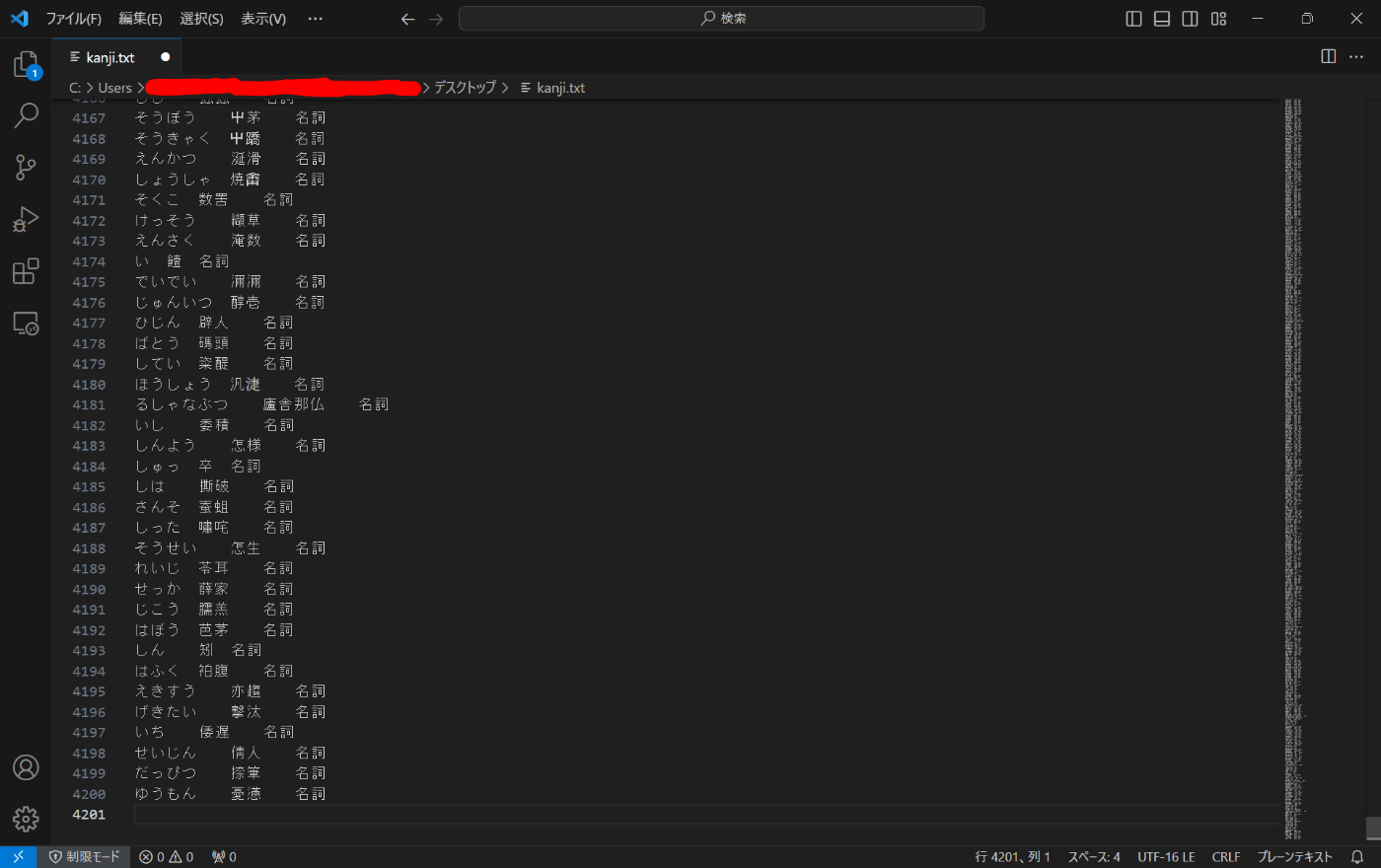
Excelファイルの内容をコピー&ペースト

同様に、エンコード付きで保存
ユーザー辞書に登録
右下のMicrosoft IMEのアイコンを右クリックしてメニューを開き、
「単語の追加」を選択、そして「ユーザー辞書ツール」(メニューの左下)を選択します。

こうして開かれたユーザー辞書ツールの、上のタブの「ツール」から、「テキストファイルからの登録」を選択し、先ほどのテキストファイルを選択します。

以上で完了です!!
補足
文字コードをUTF16-LEにしたのは、「それで上手くいったから」というだけです。
UTF16-BEでも上手くいくかもしれません。
ただし、Shift-JISでは、一部漢字が文字化け (e.g.品騭 -> 品?) してしまうようです。
最初に調べていた時は、UTF-8ではなくShift-JISにすれば登録できるとばかり書かれていたので、ちょっぴり苦労しました……
下は参考になったサイトです。
課題点
このやり方では、複数読みが存在する熟語に対応できません。
(e.g.潺湲は「せんかん」とも「せんえん」とも読みますが、せんえんと書いても出てきません)
加筆(2023/12/24)
現在では、ユーザー辞書ではなくシステム辞書として登録し、かつ使用設定をオフにしています。

こうしないと、今回登録した単語たちが一番上、つまり最も優先順位の高い語として扱われ、実際の使用頻度と逆転してしまうからです。
基本的に登録した漢字は出ないものの、出そうと思えば出せるという、理想的な状況となりました。


Discussion