IoT端末で測定したデータをAmazon Timestreamに保存して可視化する
Amazon Timestreamとは、フルマネージドでサーバレスな時系列データベースです。時系列データとは、IoT端末での気温の測定値や株価の推移のような時間とともに変化するデータです。
Timestreamのテーブルのコンセプト
時系列データと言っても、リレーショナルデータベースのテーブルと同じような考え方で扱えるはずですが、Timestreamは少し変わったテーブル形式でデータを保存します。(恐らく性能上の都合でしょう)
ディメンション(dimension)、タイムスタンプ(timestamp)、測定名(measure name)、測定値(measure value)の4つの列のコンセプトが重要になります。
普通のRDBMSでは以下のようなテーブルがあるとすると、
| デバイスID | タイムスタンプ | co2 | temperature | humidity |
|---|---|---|---|---|
| device_1 | 2022-04-20 05:51 JST | 652 | 24.1 | 40.4 |
| device_2 | 2022-04-20 05:52 JST | 731 | 22.8 | 38.9 |
| device_1 | 2022-04-20 05:54 JST | 663 | 24.0 | 40.5 |
Timestreamでは以下のような形で格納されます。
| デバイスID (ディメンション) |
タイムスタンプ | 測定名 | 測定値 |
|---|---|---|---|
| device_1 | 2022-04-20 05:51 JST | co2 | 652 |
| device_1 | 2022-04-20 05:51 JST | temperature | 24.1 |
| device_1 | 2022-04-20 05:51 JST | humidity | 40.4 |
| device_2 | 2022-04-20 05:52 JST | co2 | 731 |
| device_2 | 2022-04-20 05:52 JST | temperature | 22.8 |
| device_2 | 2022-04-20 05:52 JST | humidity | 38.9 |
| device_1 | 2022-04-20 05:54 JST | co2 | 663 |
| device_1 | 2022-04-20 05:54 JST | temperature | 24.0 |
| device_1 | 2022-04-20 05:54 JST | humidity | 40.5 |
ディメンションは複数の列にすることもできます。
| 県名 (ディメンション1) |
デバイスID (ディメンション2) |
タイムスタンプ | 測定名 | 測定値 |
|---|---|---|---|---|
| Tokyo | device_1 | 2022-04-20 05:51 JST | co2 | 652 |
| Tokyo | device_1 | 2022-04-20 05:51 JST | temperature | 24.1 |
| Tokyo | device_1 | 2022-04-20 05:51 JST | humidity | 40.4 |
| Osaka | device_2 | 2022-04-20 05:52 JST | co2 | 731 |
| Osaka | device_2 | 2022-04-20 05:52 JST | temperature | 22.8 |
| Osaka | device_2 | 2022-04-20 05:52 JST | humidity | 38.9 |
| Tokyo | device_1 | 2022-04-20 05:54 JST | co2 | 663 |
| Tokyo | device_1 | 2022-04-20 05:54 JST | temperature | 24.0 |
| Tokyo | device_1 | 2022-04-20 05:54 JST | humidity | 40.5 |
Timestreamの構成
Timestreamは以下のような構成になっています。

(AWSのドキュメントより)
書き込みは、AWS SDK(JavaScript等)で、統合層(Integration layer)のサーバにデータをアップロードします。統合層はまず、ストレージ層のインメモリ・ストア(In-memory store)に書き込みます。設定された日数が経過すると磁気ストア(Magnetic store)にデータが移動されます。これによって直近のデータは高速に読み書きでき、安く長期保存できるようになり、一般的な用途では低価格で高性能なシステムとして利用できるようになります。
検索は、AWS SDKを使って問合せ層(Query layer)のサーバに問合せします。問合せ層のワーカーが並列で、ストレージの一団に対して検索を実行する事によって大量に保存されたデータを高速に検索できるようになっています。
この問合せには、SQLライクな問合せ言語を使う事ができるので、SQLに慣れた開発者には学習コストを抑えて利用できます。
Timestreamのデータベース、テーブルの作成
Timestreamの概略を理解したので、実際に使ってみます。
まず、データベース、テーブルを以下の手順で作成します。
- TimestreamのAWSコンソールを開く
- ナビゲーション・ペインで Database を選択
- Create database をクリック
-
create database ページで、次のように操作
- Choose a configuration で、Standard database を選択
- Name でデータベース名を入力(例: RoomCondition)
- Create database をクリック
- ナビゲーション・ペインで Tables を選択
- Create table をクリック
-
Create table ページで、以下のように操作
- Database name で、作成したデータベースを選択
- Table name で、テーブル名を入力(例: conditions)
- Data retention で保存期間について、 Memory store retention、 Magnetic store retention を設定
- create table をクリック
テーブルへの書き込み
node.jsを使って、テーブルにデータを書き込んでみます。
(この前にAWS CLIを実行できるようにセットアップする必要がありますが、やり方の情報は世の中に溢れているので、例えばQiitaの記事を参照してください。)
import { TimestreamWriteClient, WriteRecordsCommand } from "@aws-sdk/client-timestream-write";
const client = new TimestreamWriteClient({ region: "us-west-2" });
const currentTime = Date.now().toString();
const dimensions = [{Name: "deviceId", Value: "1"}];
const co2 = {
Dimensions: dimensions,
MeasureName: "co2",
MeasureValueType: "DOUBLE",
MeasureValue: "600",
Time: currentTime.toString(),
}
const temperature = {
Dimensions: dimensions,
MeasureName: "temperature",
MeasureValueType: "DOUBLE",
MeasureValue: "24.5",
Time: currentTime.toString(),
}
const humidity = {
Dimensions: dimensions,
MeasureName: "humidity",
MeasureValueType: "DOUBLE",
MeasureValue: "41.7",
Time: currentTime.toString(),
}
const records = [co2, temperature, humidity];
const params = {
DatabaseName: "RoomCondition",
TableName: "conditions",
Records: records,
};
const command = new WriteRecordsCommand(params);
await client.send(command)
.then((data) => {
console.log(JSON.stringify(data));
}).catch((error) => {
console.log(JSON.stringify(error));
}).finally(() => {
// finally.
});
package.jsonを以下の通り作成します。
{
"name": "client_nodejs",
"version": "1.0.0",
"description": "",
"type": "module",
"main": "index.js",
"scripts": {
"start": "node src/main.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"@aws-sdk/client-timestream-write": "^3.72.0"
}
}
AWSコンソールで、クエリを実行してみると以下のような結果になります。

HTTP経由でのTimestreamへINSERT
HTTPサーバ経由でTimestreamにデータを保存してみましょう。ここでは、HTTPサーバはnode.jsでサーバを立ててみます。
まず以下のコマンドを実行して、Node.jsのパッケージを作成します。
npm init -y
次にpackage.jsonを以下のように編集します。
{
"name": "dbproxy",
"version": "1.0.0",
"description": "",
"type": "module",
"main": "index.js",
"scripts": {
"start": "sudo node src/main.js",
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"@aws-sdk/client-timestream-write": "^3.72.0"
}
}
src/main.js を以下の通り作成します。
import http from "http";
import { TimestreamWriteClient, WriteRecordsCommand } from "@aws-sdk/client-timestream-write";
const insertTimestream = async (co2, temperature, humidity) => {
const client = new TimestreamWriteClient({ region: "us-west-2" });
const currentTime = Date.now().toString();
const dimensions = [{Name: "deviceId", Value: "1"}];
const co2Record = {
Dimensions: dimensions,
MeasureName: "co2",
MeasureValueType: "DOUBLE",
MeasureValue: co2.toString(),
Time: currentTime.toString(),
}
const temperatureRecord = {
Dimensions: dimensions,
MeasureName: "temperature",
MeasureValueType: "DOUBLE",
MeasureValue: temperature.toString(),
Time: currentTime.toString(),
}
const humidityRecord = {
Dimensions: dimensions,
MeasureName: "humidity",
MeasureValueType: "DOUBLE",
MeasureValue: humidity.toString(),
Time: currentTime.toString(),
}
const records = [co2Record, temperatureRecord, humidityRecord];
const params = {
DatabaseName: "RoomCondition",
TableName: "conditions",
Records: records,
};
const command = new WriteRecordsCommand(params);
return client.send(command)
.then((data) => {
console.log(JSON.stringify(data));
});
};
var server = http.createServer(async (req, res) => {
const buffers = [];
for await (const chunk of req) {
buffers.push(chunk);
}
const body = Buffer.concat(buffers).toString()
let data = null;
try {
data = JSON.parse(body);
await console.log(data);
} catch(e) {
await console.log(new Date().toISOString() + " : " + body);
res.end();
return;
}
insertTimestream(data.co2, data.temperature, data.humidity)
.then(() => {
res.end();
}).catch((e) => {
console.log(new Date().toISOString() + " : " + e);
res.writeHead(500);
res.end();
})
}).listen(80);
編集し終えたら、以下のコマンドを実行してサーバを起動します。
nohup npm start &
テストとして、curlを使ってPOSTしてみましょう。
curl -X POST -H "Content-Type: application/json" -d '{"co2": 550, "temperature": 24.2, "humidity": 48.2}' http://ホスト名/
もしくは、Wio TerminalにSDC30を接続してPOSTしてもよいです。
Grafanaを使って可視化
Grafanaを使ってデータをグラフ形式でみてみましょう。
まず、Grafanaをインストール後に、Timestreamのプラグインをインストールします。
sudo grafana-cli plugins install grafana-timestream-datasource
その後Grafanaを再起動します。
sudo systemctl restart grafana-server
AWS CLIでTimestreamのクエリ用のエンドポイントを確認します。リージョンは適宜変更してください。
aws timestream-query describe-endpoints --region us-west-2 | jq -r '.Endpoints[].Address'
GrafanaのGUI画面で、 Add data source のアイコンをクリックします。

Add data xource 画面で、 Amazon Timestream を選択します。
Authentication Provider は、Access & secret key を選択し、以下のように設定し、Save & Testをクリックします。
| 項目 | 値 |
|---|---|
| Authentication Provider | Access & secret key |
| Access Key ID | IAMユーザーのアクセスキーID |
| Secret Access Key | IAMユーザーのシークレットアクセスキー |
| Assume Role ARN | 空欄のまま |
| External ID | 空欄のまま |
| Endpoint | AWS CLIで調べたqueryエンドポイント |
| Default Region | us-west-2 |
Create の Dashboard を選択します。

Add a new panel を選択します。

Data sourceでAmazon Timestreamを選択し、Database、Table、measureを選択します。
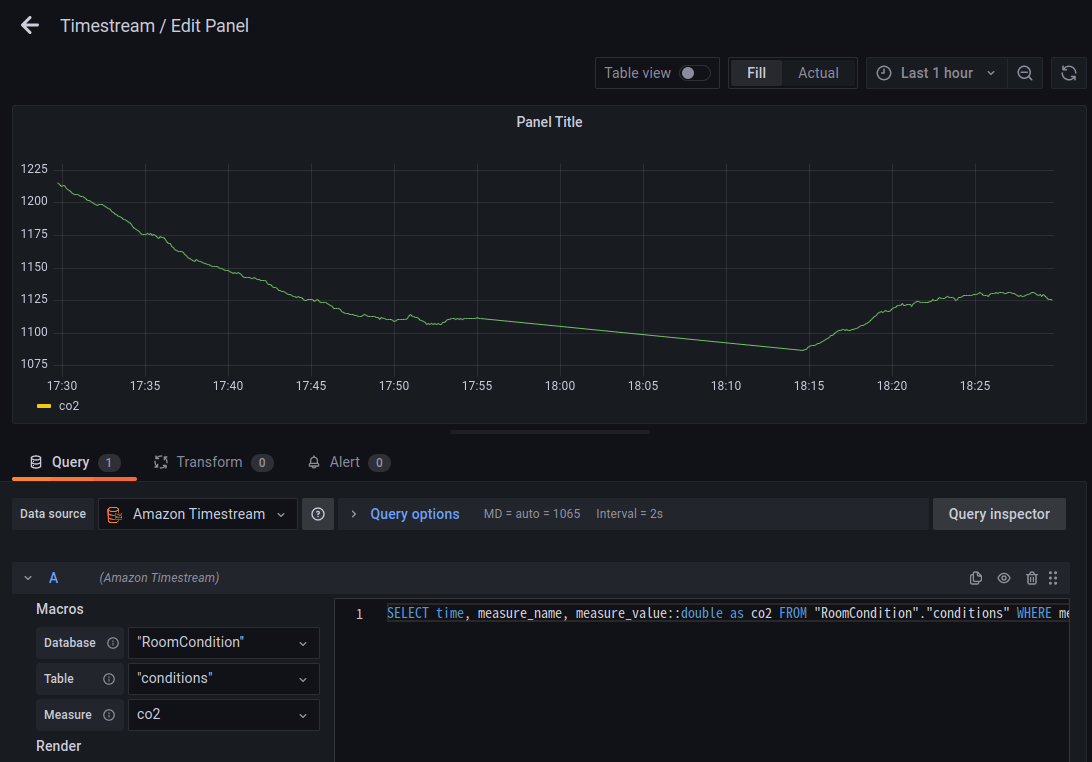
以下のクエリを設定し、画面右上のApplyをクリックします。
SELECT time, measure_name, measure_value::double as co2 FROM "RoomCondition"."conditions" WHERE measure_name = 'co2' ORDER BY time
データ集計する
セットアップできたので、色々と集計してみましょう。
SQL
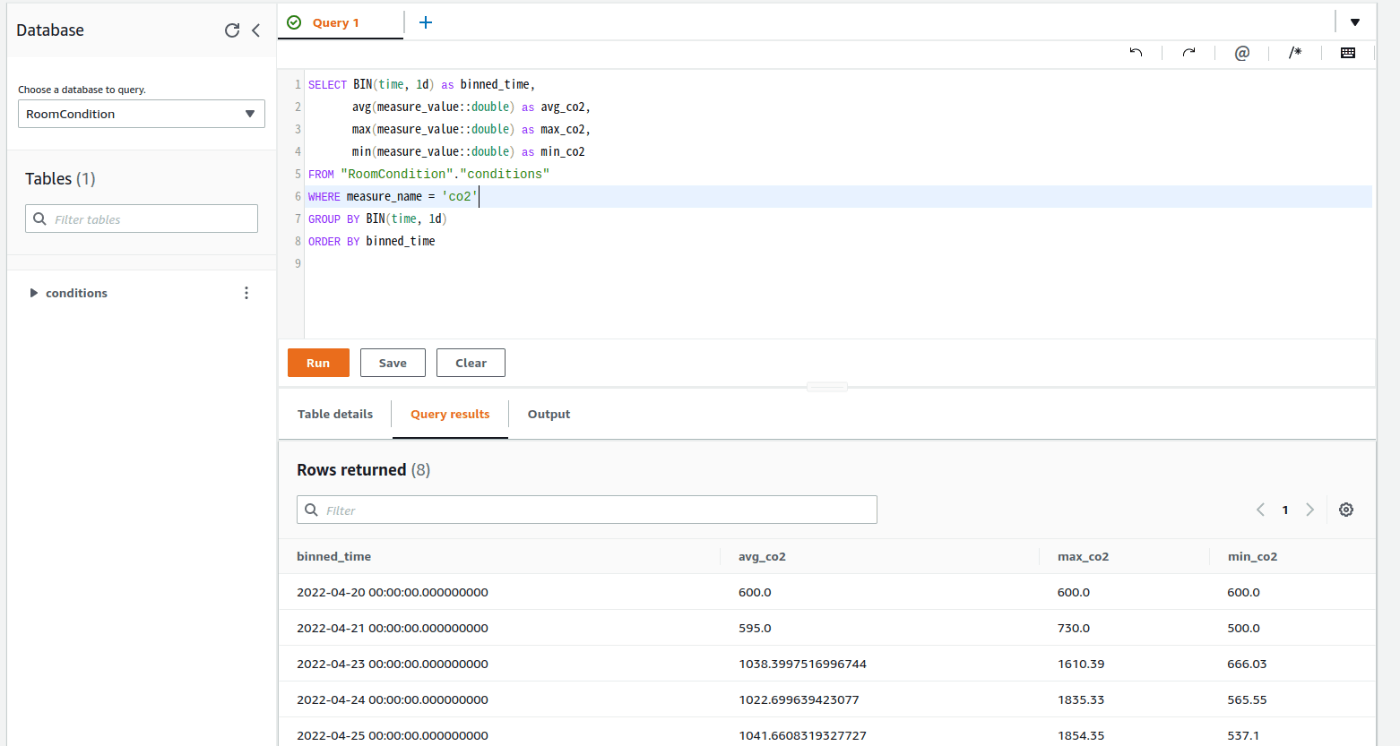
AWSコンソール上で、以下のクエリを実行すると、1日の平均値、最大値、最小値を求める事ができます。
SELECT BIN(time, 1d) as binned_time,
avg(measure_value::double) as avg_co2,
max(measure_value::double) as max_co2,
min(measure_value::double) as min_co2
FROM "RoomCondition"."conditions"
WHERE measure_name = 'co2'
GROUP BY BIN(time, 1d)
ORDER BY binned_time
AWS コンソールでの実行結果
Grafana
Grafana上で、上述のクエリを設定すると、以下のようにグラフ化できます。

Discussion