Nadaraya-WatsonモデルをPythonコードを交えて紹介
はじめに
PRML(Pattern Recognition and Machine Learning)でNadaraya-Watsonモデルについて学んだ内容をまとめて、人工的に生成したデータを使って学習しました。主に6.3節の内容です。pythonコードは必要に応じて読んでください。
表記について
- 訓練データの説明変数:
\mathbf{X} = \left\{\mathbf{x_1}, \mathbf{x_2}, \cdots \mathbf{x_N}\right\}, \mathbf{x_n} = (x_{n, 1}, x_{n, 2}, \cdots, x_{n_D})^T - 訓練データの目的変数:
\mathbf{t} = \left\{t_1, t_2, \cdots t_N\right\} - 新たな入力データ:
\mathbf{x_*} -
\mathbf{x_*} t_* -
\mathbf{x_*} y(\mathbf{x}_*)
近いデータで予測する
「近い」データを使って、新たな入力データに対する出力を予測することを考えます。
import文
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
np.random.seed(28)
データ
今回は以下の
作図コード
line_x = np.linspace(0.0, 2*np.pi, num=500)
line_t = [np.sin(x) + 0.1*x**2 for x in line_x]
plt.plot(line_x, line_t)

次のように45個のデータを生成しました。今回はこれを訓練データとして学習をします。
作図コード
beta = 0.5
data_x = np.random.rand(45) * 2 * np.pi
data_t = [np.sin(x) + 0.1*x**2 + np.random.normal(0, beta) for x in data_x]
plt.scatter(data_x, data_t)
plt.plot(line_x, line_t)

最近傍法
最近傍法では、訓練データの中でその説明変数と
k-近傍法
k-近傍法は最近傍法と似ていますが、訓練データの中でその説明変数と
下の図で、左上の
学習と作図コード
def kNN(k, xs, ts, x_star):
distance = [[abs(x - x_star), t] for (x, t) in zip(xs, ts)]
distance.sort()
t_star = 0
for i in range(k):
t_star += distance[i][1]
t_star /= k
return t_star
def RMSE(true_t, pre_t):
sum = 0
for (tt, pt) in zip(true_t, pre_t):
sum += (tt - pt) ** 2
rmse = np.sqrt(sum / len(true_t))
return rmse
ks = list(range(1, 21))
kNN_RMSEs = []
nearest_neighbour_ts = [[] for _ in range(len(ks))]
for (i, k) in enumerate(ks):
for x in line_x:
nearest_neighbour_ts[i].append(kNN(k, data_x, data_t, x))
kNN_RMSEs.append(RMSE(line_t, nearest_neighbour_ts[i]))
fig = plt.figure(figsize=(12, 9))
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
ax1.scatter(data_x, data_t)
ax1.plot(line_x, line_t)
ax1.plot(line_x, nearest_neighbour_ts[0], label="k=1")
ax2.scatter(data_x, data_t)
ax2.plot(line_x, line_t)
ax2.plot(line_x, nearest_neighbour_ts[2], label="k=3")
ax3.scatter(data_x, data_t)
ax3.plot(line_x, line_t)
ax3.plot(line_x, nearest_neighbour_ts[8], label="k=9")
ax4.scatter(data_x, data_t)
ax4.plot(line_x, line_t)
ax4.plot(line_x, nearest_neighbour_ts[19], label="k=20")
ax1.legend(loc = 'upper left')
ax2.legend(loc = 'upper left')
ax3.legend(loc = 'upper left')
ax4.legend(loc = 'upper left')
plt.show()

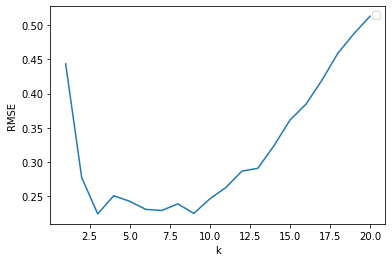
下の図は
作図コード
plt.plot(ks, kNN_RMSEs)
plt.xlabel("k")
plt.ylabel("RMSE")
plt.show()
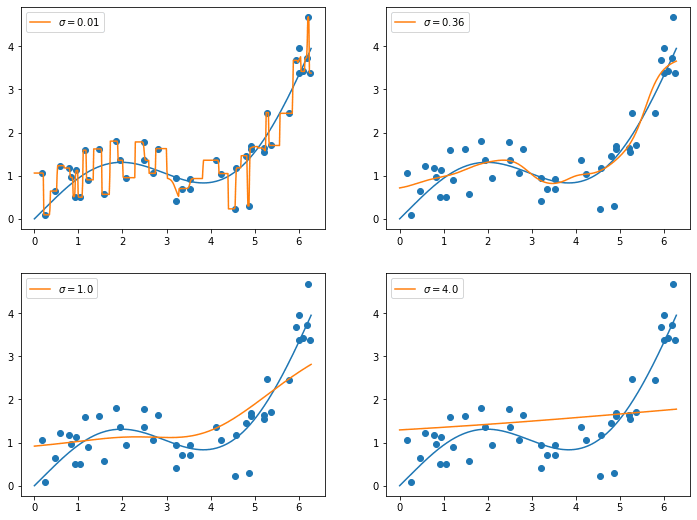
Nadaraya-Watsonモデル
k-近傍法の考え方をもう少し広げてみて、
そして、この関数を用いて次のように
ここで定義より、
次に、以下のように具体的な
学習と作図コード
def nadaraya_watson(sigma, xs, ts, x_star):
prob_sum = 0
tmp_t = 0
for (x, t) in zip(xs, ts):
prob = norm.pdf(x_star, x, sigma)
prob_sum += prob
tmp_t += prob * t
pre_t = tmp_t / prob_sum
return pre_t
sigmas = [(0.1*i) ** 2 for i in range(1, 21)]
nw_RMSEs = []
nadaraya_watson_ts = [[] for _ in range(len(sigmas))]
for (i, sigma) in enumerate(sigmas):
for x in line_x:
nadaraya_watson_ts[i].append(nadaraya_watson(sigma, data_x, data_t, x))
nw_RMSEs.append(RMSE(line_t, nadaraya_watson_ts[i]))
fig = plt.figure(figsize=(12, 9))
ax1 = fig.add_subplot(2, 2, 1)
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
ax4 = fig.add_subplot(2, 2, 4)
ax1.scatter(data_x, data_t)
ax1.plot(line_x, line_t)
ax1.plot(line_x, nadaraya_watson_ts[0], label="$\sigma=0.01$")
ax2.scatter(data_x, data_t)
ax2.plot(line_x, line_t)
ax2.plot(line_x, nadaraya_watson_ts[5], label="$\sigma=0.36$")
ax3.scatter(data_x, data_t)
ax3.plot(line_x, line_t)
ax3.plot(line_x, nadaraya_watson_ts[9], label="$\sigma=1.0$")
ax4.scatter(data_x, data_t)
ax4.plot(line_x, line_t)
ax4.plot(line_x, nadaraya_watson_ts[19], label="$\sigma=4.0$")
ax1.legend(loc = 'upper left')
ax2.legend(loc = 'upper left')
ax3.legend(loc = 'upper left')
ax4.legend(loc = 'upper left')
plt.show()
作図コード
plt.plot(sigmas, nw_RMSEs)
plt.xlabel("sigma")
plt.ylabel("RMSE")
plt.show()

理論
モデル
目的変数
これを変分法を用いて
解の導出
まず、
とします。これを
となります。
とします。これは全ての
を選べば良いです。また、こうすることで、
今、
となります。これで、確かに
Discussion