Vercel AI SDK + Next.js + OpenAI + Edge Runtime で作るチャットボット・サービス
Vercel AI SDKとはChatGPT風のチャットボット・サービスを作るためのTypeScriptのSDKライブラリです。OpenAIなど各社からLLMサービスが公開されていますが、APIのインターフェースの差異を吸収してくれるものです。また、Vercelと言えばNext.jsですが、App Routerのストリーミングをうまく利用してチャット機能を実装しています。
Vercel AI SDKとは?
OpenAI API、HuggingFace、Anthropic、ReplicateのチャットAPIサービス(セルフホストLLMでなく)を統一的に利用できるようにしたTSライブラリです。チャット・アプリではレスポンスをパラパラとタイプライター風に出力するとカッコいいです。特に最近のLLMは長文を返すことが可能になりましたので、ストリーミングで少しずつレスポンスを返すことでユーザ体験が向上します。また、Webストリーミングではアップストリームへのキャンセルやバックプレッシャーを実装しないとリソースを食い尽くして(課金される)しまいますが、Vercel AI SDKではクライアントからプル方式で取得するように実装されているので途中でブラウザを閉じられても安心です。
公式のデモサイトもあります。

Edge Runtimeとは?
Vercelプラットフォームでは、2つのランタイム Node.jsとEdgeを提供しており、エンドポイント単位で指定できます。Vercel自体はサーバー環境を持っていません。Node.jsランタイムの実体はAWS Lambadaです。Edgeランタイムは最近追加されたもので、今流行りのCloudflare WorkersのV8 Isolatesが実体です。
EdgeランタイムはNode.jsランタイムと比較して以下のメリットがあります。(つまり、CF V8 Isolatesのメリット)
- CPU時間での課金なので、I/Oバウンドな処理(チャット)に向いている
- Cloudflareの世界中に配置されたエッジサーバで処理ができる (リージョン=地球)
- コールド・スタートがゼロ
Next.jsではJSファイルの先頭で以下のようにランタイムを指定することで、エンドポイント単位にデプロイ先のランタイムを指定することができます。
export const runtime = 'edge' // 'nodejs' (デフォルト) or 'edge'
Edge Runtimeの制限はこちら。
使い方
公式サイトのサンプル・コードに従って説明します。
インストール
新規にNext.jsプロジェクトを作成しましょう。aiとopenai-edgeをインストールします。pnpmを使用します。
npx create-next-app@latest
rm -rf node_modules/
pnpm install
pnpm i ai openai-edge
実装
サーバ側とクライアント側の2つのコードを作成します。ソースコードをこちらにおきます。
サーバ側
サーバ側はApp RouterのRouter Handlerを使用して実装します。レスポンスをStreams APIで返します。Steams APIはNext.jsのServer ComponentsのSuspenseでレスポンスをprograssiveに返すのにも使用されています。
import {OpenAIStream, StreamingTextResponse} from 'ai'
import {Configuration, OpenAIApi} from 'openai-edge'
const config = new Configuration({
apiKey: process.env.OPENAI_API_KEY // ご自身のOpenAI APIキー sk-xxx
})
const openai = new OpenAIApi(config)
// Edge Runtimeにデプロイします
export const runtime = 'edge'
export async function POST(req: Request) {
// プロンプトを受け取ります
const {messages} = await req.json()
try {
const response = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
top_p: 0.75,
// temperature: 0.9,
stream: true, // レスポンスをServer Sent Eventで返します
messages
})
// ブラウザ側にもストリームでパラパラ返します
const stream = OpenAIStream(response)
return new StreamingTextResponse(stream)
} catch (error) {
return new Response(JSON.stringify({error: 'An error occurred while creating the chat completion'}), {status: 500})
}
}
export const runtime = 'edge'を指定すると、Edge Runtimeにデプロイされます。もちろん、ローカル開発環境でも動作します。
openai.createChatCompletionでVercel製のopenai-edgeを使用します。冒頭でも書きましたが、本家のライブラリopenaiはEdge Runtimedでは動きません。
VercelにデプロイするとEdgeにデプロイされたことが確認できます。GLOBALと表記されているのがゾクゾクしますね。

Node.jsランタイムでも動きますが、VercelのHobbyプランの場合は実行時間が最大10秒の制約があることに注意してください。gptからの回答が長くなると10秒を超過する可能性があります。また、アメリカ東海岸などの特定のリージョン(AWS Lambda)にデプロイされます。その点、Edgeランタイムはグローバルのエッジ・サーバ(CloudFlare Worker)にデプロイされるし、CPU時間で計測される、つまりI/O待ちはカウントされないので問題ありません。
MSのOpenAIが日本でサービスを始めればトラフィックは全て日本国内で完結します。
クライアント側
クライアントのコードになります。Vercel AI SDKのカスタム・フックuseChatを使いましょう。apiに先ほど作成したサーバのエンドポイント/api-openaiを指定します。
'use client'
import {useChat} from 'ai/react'
export default function Chat() {
// カスタム・フックを利用します
const {messages, input, handleInputChange, handleSubmit} = useChat({api: "/api-openai"})
return (
<div className="mx-auto w-full max-w-md py-24 flex flex-col stretch">
{messages.map(m => (
<div key={m.id}>
{m.role === 'user' ? 'User: ' : 'AI: '}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<label>
Say something...
<input
className="fixed w-full max-w-md bottom-0 border border-gray-300 rounded mb-8 shadow-xl p-2 text-black"
value={input}
onChange={handleInputChange}
/>
</label>
<button type="submit">Send</button>
</form>
</div>
)
}
公式のスタイルだとダークモードだと真っ暗になるため少し調整しました。
ブラウザから、/chatにアクセスしてください。冒頭の動画のようなチャット画面が表示されます。画面下部のテキストボックスに質問を入力してください。パラパラと応答がかえります。
ChromeのDev ToolからPOSTのペイロードを確認してみましょう。
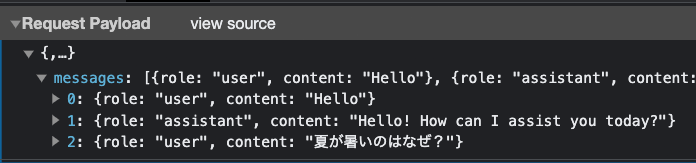
--data-raw $'{"messages":[{"role":"user","content":"Hello"},{"role":"assistant","content":"Hello\u0021 How can I assist you today?"},{"role":"user","content":"夏が暑いのはなぜ?"}]}'
動かない場合
OpenAI APIの無料枠を使い切ってしまうと429エラー(Too Many Requests)が発生します。レートリミットなどの制限を超えた場合に返るエラーコードです。
An error occurred while creating the chat completion: [Error: Failed to convert the response to stream. Received status code: 429.]
OpenAIのPlaygroundのチャット機能が使えるか確認してください。動かなければクレカを登録してください。
Huggingface
次はOpenAI APIではなくHuggingfaceを使用してみます。無料で使えるところが良いですね。
ライブラリをインストールします。
pnpm i @huggingface/inference
Huggingfaceのサイトにログインして、APIキーを払い出します。
HUGGINGFACE_API_KEY=hf_yFdj..ngkCv
OpenAIと同じように、Route Handlerに実装してみましょう。
LLMには OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5を使用しています。
面倒なのは使用するLLMによってプロンプトの形式が異なるため前処理が必要になります。buildOpenAssistantPromptで実装しています。
import { HfInference } from '@huggingface/inference'
import { HuggingFaceStream, StreamingTextResponse } from 'ai'
// APIキーを設定します
const Hf = new HfInference(process.env.HUGGINGFACE_API_KEY)
export const runtime = 'edge'
// OpenAssistant用のプロンプトを作成します
function buildOpenAssistantPrompt(
messages: { content: string; role: 'system' | 'user' | 'assistant' }[]
) {
return (
messages
.map(({ content, role }) => {
if (role === 'user') {
return `<|prompter|>${content}<|endoftext|>`
} else {
return `<|assistant|>${content}<|endoftext|>`
}
})
.join('') + '<|assistant|>'
)
}
// ここから下は OpenAI とほぼ同じです。
export async function POST(req: Request) {
const { messages } = await req.json()
const response = Hf.textGenerationStream({
model: 'OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5',
inputs: buildOpenAssistantPrompt(messages),
parameters: {
max_new_tokens: 200,
// @ts-ignore (this is a valid parameter specifically in OpenAssistant models)
typical_p: 0.2,
repetition_penalty: 1,
truncate: 1000,
return_full_text: false
}
})
// Convert the response into a friendly text-stream
const stream = HuggingFaceStream(response)
return new StreamingTextResponse(stream)
}
クライアント側は共通化できます。APIのエンドポイントだけ変更するだけで動きます。いいですね。
const api = ["/api-ai", "/api-huggingface", "/api/anthropic"][1]
const {messages, input, handleInputChange, handleSubmit} = useChat({api})
サーバー・コンポーネントに実装
次はサーバ側をNext.jsのサーバー・コンポーネントで実装する方法です。(APIではなく)
export default async function Page({searchParams} : {
searchParams: Record<string, string>
}) {
const prompt = searchParams['prompt'] ?? 'Give me code for generating a JSX button'
const messages: Message[] = [
{content: 'Hello, assistant!', role: 'user'},
{content: 'How can I assist you today?', role: 'assistant'},
{content: 'System initializing...', role: 'system'},
{content: prompt, role: 'user'},
];
const response = Hf.textGenerationStream({
model: HF_Model,
inputs: buildOpenAssistantPrompt(messages),
...
})
const stream = HuggingFaceStream(response)
const reader = stream.getReader()
// 再起的にストリームをレンダリングします。
return (
<Suspense>
<Reader reader={reader}/>
</Suspense>
)
}
最初このコードを見たときは目が点になりました。もともと、サーバ・コンポーネントはレスポンスをStreams APIでチャンクでプログレッシブに返す作りになっています。
コンポーネントを再帰的にレンダリングすることで応答をチャンクで返すことができます。Readerはasync関数ですのでPromiseを返します。Suspenseで囲むことで、一旦処理を中断しブラウザに読み込んだtextを返します。終了条件として、doneがセットされたらnullを返すようにしています。
import {Suspense} from "react";
export default async function Reader({
reader
}: {
reader: ReadableStreamDefaultReader<any>
}) {
const {done, value} = await reader.read()
if (done) { // 再帰処理の終了条件
return null
}
const text = new TextDecoder().decode(value)
return (
<span>
{text}
<Suspense>
<Reader reader={reader}/> // 再帰呼び出し
</Suspense>
</span>
)
}
実行するには、ブラウザからこのエンドポイントにアクセスします。自己完結しているので、クライアント側のchatは不要です。http://localhost:3000/server-component?prompt=hello
GETパラメータpromptにプロンプトを渡します。urlエンコードする必要がありますので、ネット上の変換サービスなどでエンコードしてください。
「一番高い山は?」と質問した例です。
http://localhost:3000/server-component?prompt=what%20is%20the%20highest%20mountain%3F%0A

この再帰呼び出しはクライアント側ではどう処理されているのか気になりましたので、Chrome Dev Toolでソースコードを調べてみました。
highest、mountainとチャンクで渡された部分はhiddenになっており、Suspenseの部分はプレースホルダーtemplateになっています。この部分にJSでチャンクをはめ込んでいるようです。

token
<Tokens>を使用すると先ほどの再起呼び出しをよしなにやってくれます。
// app/server-component/render.tsx と同じ
const stream = HuggingFaceStream(response)
return <Tokens stream={stream}/>
Tokensのソースコードを覗き見るとSuspenseと再帰処理で同様に実装しています。

クライアント・コンポーネント
クライアント・コンポーネントにはランタイムを指定することはできません。この場合、サーバ・コンポーネントでラップすることで指定することが可能になります。
import Chat from './client'
export const runtime = 'edge'
export default function Page() {
return <Chat />
}
Replicate
インストールします。
pnpm install replicate
使用できるモデルはこちらから探します。プログラムからはバージョン番号を指定します。
import { ReplicateStream, StreamingTextResponse } from 'ai'
import Replicate from 'replicate'
import { experimental_buildLlama2Prompt } from 'ai/prompts'
// Create a Replicate API client (that's edge friendly!)
const replicate = new Replicate({
auth: process.env.REPLICATE_API_KEY || ''
})
export const runtime = 'edge'
const models = {
'Llama 2 70b Chat': '2c1608e18606fad2812020dc541930f2d0495ce32eee50074220b87300bc16e1',
'stablelm-tuned-alpha-7b': 'c49dae362cbaecd2ceabb5bd34fdb68413c4ff775111fea065d259d577757beb'
}
export async function POST(req: Request) {
// Get the prompt from the request body
const { messages } = await req.json()
const response = await replicate.predictions.create({
stream: true,
version: models['Llama 2 70b Chat'],
// Format the message list into the format expected by Llama 2
// @see https://github.com/vercel-labs/ai/blob/99cf16edf0a09405d15d3867f997c96a8da869c6/packages/core/prompts/huggingface.ts#L53C1-L78C2
input: {
prompt: experimental_buildLlama2Prompt(messages)
}
})
const stream = await ReplicateStream(response)
return new StreamingTextResponse(stream)
}
Anthropic
アンソロピックという会社でOpenAIの元社員が起業した会社です。ClaudeというChatGPTのようなAIボットをクラウドで提供しています。Googleとパートナー提携しています。Slack、Notion、QuoraなどのAIサービスで使用されています。
似たような感じなのでコードは割愛します。詳しくは公式をご覧ください。
レートリミット
Vercel KV(Redis)を使用してレートリミットをかける方法です。
Discussion