日本語 Static EmbeddingとDuckDBを使用したベクトル検索RAGの構築方法
本ブログでは、@hotchpotch(セコン)氏の日本語用 Static Embedding と DuckDB を用いて、ベクトル検索システムを構築する方法をご紹介します。
概要
ChatGPT の登場以来、LLM へのプロンプトを拡張(Augment)する手法として、ベクトル検索が脚光を浴びるようになりました。通常、文章ベクトルを生成するには OpenAI API などの LLM を使用する必要がありますが、コストが高くつき、レイテンシが遅くなる問題があります。
そこで本記事では、文章ベクトルの生成に日本語対応のStatic Embeddingモデル(by セコン氏)を活用し、ベクトル検索エンジンとしてはインメモリで使える DuckDB を利用することで、低コストで爆速な RAG システムを構築する方法をご紹介します。
ソースコードはこちらにあります。
ライブドア・コーパス
今回も、以前も使用した ライブドア・コーパス を使って RAG システムを構築してみます。収録されている記事は 2012 年ごろのものであるため、AKB48 の前田敦子さんなど、懐かしいアイドルの名前が登場するのもご愛嬌です。当時はまだLLMは無かった訳ですが、いまだにコーパスとして貴重な存在です。感謝いたします。
ロンウイットさんのサイトからldcc-20140209.tar.gzをダウンロードし展開してください。
詳細は私の記事をご覧ください。
ファイルの読み込み
環境変数を設定します。CORPUS_DIRに展開したライブドア・コーパスのディレクトリを指定します。
import os
# ライブドアコーパスをここにおく。
# 例) CORPUS_DIR/it-life-hack/it-life-hack-6292880.txt
CORPUS_DIR = os.getenv("CORPUS_DIR", "/Users/tafu/live-door/corpus")
# 必要に応じて設定してください。
LIVEDOOR_JSON = os.getenv("LIVEDOOR_JSON", "livedoor.json")
UMAP_PNG = os.getenv("UMAP_PNG", "umap_livedoor_plot.png")
VECTORS_NPY = os.getenv("VECTORS_NPY", "vectors-livedoor-static.npy")
ライブドア・コーパスは1記事1ファイルで保存されています。Pythonで処理がしやすいようにJSONL形式で、1記事1行になるように加工処理します。ライブドアコーパスは7367文章あります。livedoor2.pyを実行すると、以下のような形式で、7367行のファイルlivedoor.jsonが出力されます。
{"url": "http://news.livedoor.com/article/detail/6234282/", "publisher": "sports-watch", "created_at": 1327966200, "body": "美人揃い!? スポーツ選手の2世タレントが熱い 2012年度ミス日本グランプリ決定コンテ...
jsonファイルをPandasに読み込みPyCharmでデータフレームを表示すると以下のようになります。PyCharmはユニーク数を表示してくれて便利です。bodyのユニーク数が7361であることから、重複した文章が6つ含まれていることが分かります。
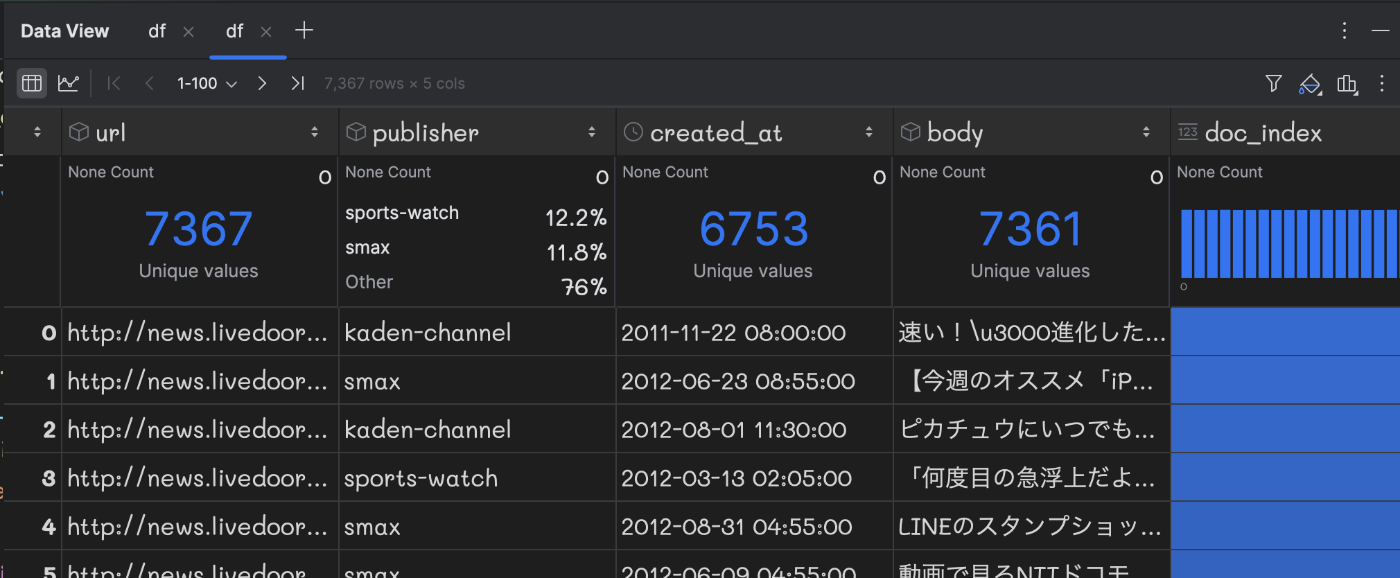
ソースコードはこちらになります。本件に本質ではないので特に説明はしません。
DuckDBへのデータ登録
"""
Do the same as livedoor.py, but using generator functions to yield documents one by one.
"""
import json
import datetime
from typing import Generator, Dict, Any
from pathlib import Path
import random
import consts
def read_document(path: Path) -> Dict[str, Any]:
"""Process a single document and return a dictionary."""
with path.open() as f:
lines = [line.rstrip() for line in f]
if len(lines) < 3:
return {}
try:
dt = datetime.datetime.strptime(lines[1], "%Y-%m-%dT%H:%M:%S%z")
created_at = int(round(dt.timestamp()))
except ValueError:
return {}
body = ' '.join(lines[2:])
return {
"url": lines[0],
"publisher": path.parent.name,
"created_at": created_at,
"body": body
}
def iter_documents_from_livedoor() -> Generator[Dict[str, Any], None, None]:
"""Yield each document from the corpus as a dictionary."""
corpus = list(Path(consts.CORPUS_DIR).rglob('*-*.txt'))
random.shuffle(corpus)
for path in corpus:
doc = read_document(path)
if doc: # skip empty or failed parses
yield doc
def write_documents_to_jsonl(output_path: str) -> None:
"""Write documents one by one in JSONL format."""
with open(output_path, 'w', encoding="utf-8") as fp:
for doc in iter_documents_from_livedoor():
json.dump(doc, fp, ensure_ascii=False)
fp.write('\n')
if __name__ == '__main__':
write_documents_to_jsonl(consts.LIVEDOOR_JSON)
文章ベクトル化
次に、@hotchpotch (セコン)氏の日本語 Static Embeddingを使用して、先ほど整形したライブドアのドキュメントを文章ベクトル化していきます。
おなじみのHuggingFaceのSentenceTransformerを使用してベクトル化します。
embeddings = model.encode(texts, batch_size=64, show_progress_bar=True)
下図は、PyCharm のデバッガーを使って処理を一時停止した際の様子です。
グレーで表示されている部分は、デバッガーによって取得された変数のスナップショット(現在の値)を表しています。

ベクトル化の処理model.encodeは、私のmacbook air M2(24GB)でわずか3秒で完了しました。圧巻のスピードです。1記事当たり0.4msで処理していることになります。
以前の記事で紹介した、株式会社リクルートのAI研究機関のGiNZA v5.1では、速くても数10msは必要です。『100倍速い』はあながち間違ってはいません。
さらに無料でベクトル化できるのも魅力です。OpenAI(text-embedding-3-small)を使用するとお金も時間もかかります。億単位の文章ファイルをベクトル化するには数十万円必要になります。
ベクトル化部分の全体のコードはこちらになります。
Static Embeddingでベクトル化
import numpy as np
import pandas as pd
from sentence_transformers import SentenceTransformer
import time
import consts
# Load the static embedding model
model_name = "hotchpotch/static-embedding-japanese"
model = SentenceTransformer(model_name, device="cpu", truncate_dim=1024)
# Load your JSONL file
df = pd.read_json(consts.LIVEDOOR_JSON, lines=True)
print(df.head())
# Encode all texts
texts = df["body"].tolist()
start = time.time()
embeddings = model.encode(texts, batch_size=64, show_progress_bar=True)
end = time.time()
print(f"Embedding time: {end - start:.4f} seconds")
# Save embeddings as a NumPy array
np.save(consts.VECTORS_NPY, embeddings, allow_pickle=False)
再利用できるように、1024次元のベクトルデータをnumpy形式でファイルconsts.VECTORS_NPYに保存します。全体で、7367x1024の行列ということです。しかしながら、これだけ速ければ毎回実行しても苦痛ではありません。
UMAP
高次元のベクトル(ここでは1024次元)を2次元に圧縮して可視化する手法としては、t-SNEやUMAPがよく知られています。
下図はUMAPを使用して次元削減し、plotlyで可視化したものです。

publisherごとにクラスターが構成されていることから、文章ベクトル化が上手くできてることが分かります。
一方で、livedoor-hommeだけは、文章ベクトルがあちこちに散らばり、クラスターを形成していないことがわかります。

この理由は、livedoor-hommeが男性向けライフスタイルをテーマにしたWebマガジンであり、コンテンツがマンション、デジタル用品、車、スポーツなどの幅広いテーマを扱ったニュース記事のためです。
グラフで可視化するとこうした傾向が簡単に発見することができます。
UMAP可視化
import json
import pandas as pd
import plotly.express as px
import umap
from sentence_transformers import SentenceTransformer
from typing import List
from utils import fold_text
import consts
# Load documents from the JSONL file
with open(consts.LIVEDOOR_JSON, 'r', encoding='utf-8') as fd:
docs = [json.loads(line) for line in fd]
# Extract texts and publishers
texts: List[str] = [doc.get("body", "") for doc in docs]
publishers: List[str] = [doc.get("publisher", "Unknown") for doc in docs]
# Load the embedding model
model_name = "hotchpotch/static-embedding-japanese"
model = SentenceTransformer(model_name, device="cpu")
# Generate embeddings
embeddings = model.encode(texts, batch_size=64, show_progress_bar=True)
# Reduce dimensions using UMAP
reducer = umap.UMAP(n_neighbors=15, min_dist=0.1, random_state=42)
embedding_2d = reducer.fit_transform(embeddings)
# Prepare data for plotting
df_plot = pd.DataFrame({
"x": embedding_2d[:, 0],
"y": embedding_2d[:, 1],
"publisher": publishers,
"text": [fold_text(text) for text in texts]
})
# Create the scatter plot
fig = px.scatter(
df_plot,
x="x",
y="y",
color="publisher",
hover_data={"text": True},
title="UMAP Projection of Livedoor Articles",
labels={"x": "UMAP Dimension 1", "y": "UMAP Dimension 2"}
)
# Adjust marker size for better visibility
fig.update_traces(marker=dict(size=5))
# Display the plot
fig.show()
fig.write_image(consts.UMAP_PNG, width=1000, height=800)
DuckDB
さて、ここまででドキュメントと対応する文章ベクトルが揃いましたので、いよいよベクトル DB に登録していきましょう。
以前は Qdrant や Pinecone など、ベクトル検索専用の DB しか選択肢がありませんでしたが、最近では PostgreSQL や Snowflake など、さまざまなデータベースがベクトルカラムに対応し始めています。
今回は、Python 界隈で人気のインメモリ DB DuckDB を採用してみたいと思います。インメモリ型であるため外部にサーバを立てる必要がなく、ローカルファイルに永続化も可能なので、再実行してもデータが失われることはありません。
ライブドア・コーパスのDuckDBへの取り込み
一旦、Polarsのデータフレームにデータを読み込み、そのあとで、SELECT文でDuckDBのテーブルを作成しています。
HNSWについては後ほど説明します。今は気にしないでください。
import textwrap
import time
import numpy as np
import pandas as pd
import polars as pl
import duckdb
import consts
# Load precomputed vectors and metadata
vectors = np.load(consts.VECTORS_NPY) # Shape: (N, D)
assert vectors.shape[1] == 1024, "Expected 1024-dimensional vectors"
df = pd.read_json(consts.LIVEDOOR_JSON, lines=True)
df["doc_index"] = df.index
# Convert to Polars DataFrame
pl_df = pl.DataFrame({
"doc_index": df["doc_index"],
"feature": vectors.tolist()
})
# Connect to DuckDB
con = duckdb.connect("livedoor_vectors.duckdb")
# Install and load the VSS extension
con.execute("INSTALL vss;")
con.execute("LOAD vss;")
# Optional: Enable experimental persistence for HNSW index
con.execute("SET hnsw_enable_experimental_persistence = true;")
# Register the Polars DataFrame as a DuckDB table
con.register("pl_df", pl_df)
# Create or replace the 'docs' table with the vector data, casting to FLOAT[1024]
# populate livedoor documents with their vectors into DuckDB from Polars DataFrame
con.execute("""
CREATE OR REPLACE TABLE docs AS
SELECT
doc_index,
feature::FLOAT[1024] AS feature
FROM pl_df
""")
# Create an HNSW index on the 'feature' column using cosine distance
con.execute("""
CREATE INDEX my_docs_hnsw
ON docs
USING HNSW (feature)
WITH (metric = 'cosine');
""")
# Query to find top similar pairs using cosine similarity
print("Executing query to find top similar pairs...")
TARGET_DOC_INDEX = 1234 # Example: using the first document as the target
print(f"{df.loc[TARGET_DOC_INDEX, 'publisher']}): {df.loc[TARGET_DOC_INDEX, 'body'][:200]}...")
query_vector = vectors[TARGET_DOC_INDEX].astype(np.float32).tolist() # ndarray to list conversion
start = time.time()
top_k_docs = con.execute(
"SELECT doc_index, array_cosine_similarity(?::FLOAT[1024], feature) AS sim FROM docs ORDER BY sim DESC LIMIT 5",
[query_vector]
).fetchall()
end = time.time()
print(f"Embedding time: {end - start:.4f} seconds")
for i, score in top_k_docs:
print(f"\n🔗 Similarity: {score:.4f}")
print(f"[{i}] ({df.loc[i, 'publisher']}): {df.loc[i, 'body'][:200]}...")
#
# Alternative query using HSNW index
# EXPLAIN sql shows that HNSW index is used
sql = textwrap.dedent(f"""
SELECT
doc_index,
array_cosine_distance(feature, ?::FLOAT[1024]) AS score
FROM docs
ORDER BY score
LIMIT 5;
""")
start = time.time()
top_k_docs_2 = con.execute(sql, [query_vector]).fetchall()
end = time.time()
print(f"Embedding time: {end - start:.4f} seconds")
for i, score in top_k_docs_2:
print(f"\n🔗 Similarity: {1 - score:.4f}")
print(f"[{i}] ({df.loc[i, 'publisher']}): {df.loc[i, 'body'][:200]}...")
con.close()
コサイン類似度
RAGシステムでは、プロンプトの文章と似ている文章を検索する訳ですが、その類似性の尺度に、コサイン値が使用されます。ベクトルのなす角が0度に近づくほど、cos(0)=1に近づきます。逆に離れている場合は0に近づきます。この数値を利用して文章の類似性を判定します。
DuckDBでコサイン類似度を計算するには array_cosine_similarity関数を使用します。各社DBで、関数名がバラバラなので統一して欲しいところです。
SELECT doc_index, array_cosine_similarity(?::FLOAT[1024], feature) AS sim FROM docs ORDER BY sim DESC LIMIT 5
下図は、『さんまさんのサッカーに関する発言に関しての記事』とコサイン類似度の高いものを検索した結果です。当たり前ですが、自分自身の文章(同一ベクトル)との類似度が1になり、類似性が一番高くなります。

DuckDB UI
DuckDBにはちょっとしたWeb UIも提供されています。コマンドラインから以下のコマンドを実行するとWebサーバが起動します。
duckdb -ui
Jupyter Notebookのような感じのUIが開きます。ここから、SQL文やPythonスクリプトを実行することができます。実行結果がインラインで表示されます。

DuckDBの永続化ファイルを読み込むこともできます。実際、上の画面ではライブドア・コパスのlivedoor_vectors.duckdbを読み込んでいます。
注意点として、他のプロセスがオープンしている場合は、ファイルにロックがかかり読み込めません。他のプロセスが利用していないか確認してから開きます。
ちなみに上の画面では、ドキュメントの全ペアのコサイン類似度を計算し、top-20を表示したものです。類似度計算に順序は関係ないため、a.doc_index < b.doc_indexとしています。
この結果からも、全く同じ内容の文章ペアが6つあることが分かります。
HNSW (Hierarchical Navigable Small Worlds)
コサイン類似度の計算は、文章ペア毎に計算する必要があるため、文章の数が増えると、計算量 O(n)で実行時間は長くなります。そこで、K近傍で最寄りの類似文章のグラフを構築しておくことで、類似文書の探索を高速化することができます。これをさらにグラフ自体を階層化(skip linked list)することで高速化 O(logN) する手法がHNSWになります。
QdrantやPostgreSQL(pgvector)などのベクトル検索DBでHNSWをサポートしています。
DuckDBでも試験的に導入していますので、使ってみましょう。
設定方法は、すでにcos_similar_duckdb.pyでお見せしていますが、vss拡張を有効化する必要があります。
# Install and load the VSS extension
con.execute("INSTALL vss;")
con.execute("LOAD vss;")
次に、インデックスの作成をします。対象のテーブル名docsとベクトル・カラムfeatureを指定します。その際に、WITH (metric = 'cosine')と指定します。(注:デフォルトはユークリッド距離)
# Create an HNSW index on the 'feature' column using cosine distance
con.execute("""
CREATE INDEX my_docs_hnsw
ON docs
USING HNSW (feature)
WITH (metric = 'cosine');
""")
コサイン距離を計算するにはarray_cosine_distance()を使用します。これは、1 - array_cosine_simililarityに等しくなります。つまり、似てるものほど0に近づきます。したがって、order by score ASCにします。引数にベクトルの次元数を指定する必要があります。このサンプルでは1024次元ベクトルを使用しています。

最後に
ベクトル検索単体のRAGには、コンテキスト(文脈)が失われてしまう問題があります。通常、文章ベクトルを生成するには、数行ごとに分割(チャンク)してからベクトル値に変換します。この分割する作業によって、全体の文章のコンテキストが失われることになります。(ローカル最適)
例えば、
『Next.jsが遅すぎて、Remixにした』
という釣りタイトルのような文章に対して、色々とツッコミどころが満載かと思います。
この文章だけでは、どのようなコンテキスト、例えばチャットAIのようなSPA型のアプリなのか?Vercelなのかセルフ・ホストなのか?Page RouteなのかApp Routeなのか?レンダリングが遅いのか、DBアクセスが遅いのか?などなど、文脈が不明瞭です。
このように細かなチャンクに分割してしまうと、こうした前後の文章とのつながりが失われてしまい、LLMの回答の手助けになりません。
逆にチャンクのサイズを大きくしてしまうと、ディテールがぼやけてしまいますし、それならロング・コンテキストで良いわけで、RAGの意味がなくなります。
これを補う手法に、グラフDBを併用してコンテキストを補足する手法があります。2段階方式で、まずはベクトル検索で候補を選出し、さらにグラフ検索で絞り込み or リランキングする方法です。
次回は、Neo4Jを使用したグラフRAGをご紹介したいと思います。
Discussion