ベクトル検索エンジン Supabase with pgVector
この記事はSupabaseのベクトル検索機能の紹介です。
Supabase ベクトル検索エンジン
Supabaseは基本的にはサーバレスのPostgresデータベースですが、pgvectorという拡張を使用することでベクトル検索エンジンとしても使用することができます。
ベクトル検索エンジンとは、文章・画像・音声などをベクトル化し、ベクトル間のコサイン類似度を使用して類似性の高いコンテンツを取得するDBです。
そして、ベクトル検索エンジンとRDBを悪魔合体させることで、SQLのWHERE句やテーブル・ジョインなどRDBの機能も使える、いいとこどりなDBになります。
ローカル開発環境
Supabase CLIツールを使用してローカル開発環境を構築します。Postgresサーバや管理ツールをローカルで起動できます。Dockerも必要になりますのでインストールしておいてください。
私のソースコードをこちらにおきます。
mkdir my-proj
cd my-proj
supabase init
supabase start
下図のように、各種サービスが起動します。ポート番号が連番になっています。Postgresサーバ(54322)や管理ツール(54323)になります。
anon keyは後で作成するAPIを呼び出すためのAPIキーになりますので控えておいてください。DB URLはPostgresに接続する接続文字列です。

WebブラウザがらStudio URL(localhost:54323)にアクセスすると管理ダッシュボードが開きます。
下図をご覧ください。テーブルのembeddingカラムに数値の配列(ベクトル)が保存されているのが分かると思います。
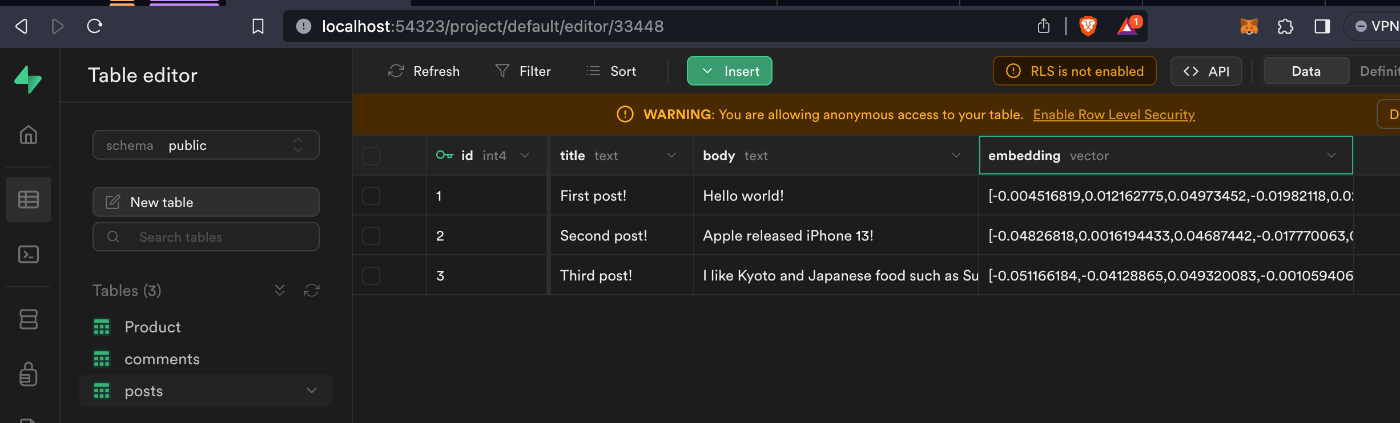
テーブルの作成
ではさっそく始めましょう。
まずはじめに、Postgresの拡張を有効化してベクトルデータを取り扱えるようにします。下記のSQLをpsqlやDataGripを使用して実行してください。Supabaseダッシュボートから実行することもできます。
create extension vector;
テーブルを作成します。記事のタイトル、本文、本文のベクトルデータの3つのカラムを作成します。通常のDDL文と同じですが、ベクトル型にvectorを指定します。その際にベクトルのサイズも指定します。ベクトルは固定長になります。
create table posts (
id serial primary key,
title text not null, <- タイトル
body text not null, <- 本文
embedding vector(384) <- bodyのベクトルデータ。384次元の固定長ベクトル
);
ベクトル・データの作成
SupabaseにはAWS LambdaのようなサーバレスでJavaScriptを実行するEdge Functionsというサービスがあります。ただし、これはDenoランタイムを使用したものですのでNode.jsとは少々違います。
supabaseコマンドを使用して、Edgeファンクションを作成します。
supabase functions new hello
するとmy-proj/supabase/functions/hello/index.tsにこのようなサンプル・コードが作成されます。
import { serve } from "https://deno.land/std@0.168.0/http/server.ts"
console.log("Hello from Functions!")
serve(async (req) => {
const { name } = await req.json()
const data = {
message: `Hello ${name}!`,
}
return new Response(
JSON.stringify(data),
{ headers: { "Content-Type": "application/json" } },
)
})
ローカルで実行します。54321ポートでサーバが起動します。
supabase functions serve
Serving functions on http://localhost:54321/functions/v1/<function-name>
cURLで呼び出します。APIのエンドポイントはlocalhost:54321になります。BearerにAnonキーを渡します。
curl -X POST --location "http://localhost:54321/functions/v1/hello" \
-H "Authorization: Bearer eyJhbG...blYTn_I0" \ <- Anonキー
-H "Content-Type: application/json" \
-d "{\"name\": \"あいうえお\"}"
さて、次にこのEdgeファンクションに公式のベクトル化の手順を参考にして、文章のベクトル化を実装しましょう。
HuggingfaceのTransformers.jsを使用してベクトル化(Embedding)します。
import {serve} from 'https://deno.land/std@0.168.0/http/server.ts'
import {env, pipeline} from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.5.0'
// Configuration for Deno runtime
env.useBrowserCache = false;
env.allowLocalModels = false;
console.log("loading function...")
const pipe = await pipeline(
'feature-extraction', // ベクトル化
'Supabase/gte-small', // モデルの指定
);
// POSTパラメータinputにベクトル化する文章を渡します。
serve(async (req) => {
const {input} = await req.json(); // POSTパラメータの取得
// ベクトル化します。
const output = await pipe(input, {
pooling: 'mean',
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
// Return the embedding
return new Response(
JSON.stringify({embedding}),
{headers: {'Content-Type': 'application/json'}}
);
});
実行します。POSTパラメータ(input)にベクトル化する文章を渡します。384次元のベクトルが返ります。
curl -X POST --location "http://localhost:54321/functions/v1/pgvector-embed" \
-H "Authorization: Bearer ANONキー" \
-H "Content-Type: application/json" \
-d "{\"input\": \"I visited Tokyo and Osaka, and went to Mt. Fuji.\"}"
...
{
"embedding": [
-0.024296224117279053,
-0.02617856115102768,
0.026475246995687485,
OpenAI APIのように外部のサービスを使うのではなく、Edgeファンクション上でモデルを動かしてベクトル化しています。ローカル開発環境だとモデルのダウンロードとCPUでの実行のため数秒かかります。
pipeに使用するモデル(gte-small)を指定します。使用できるモデルの一覧はこちらにあります。
pipe()でサポートしているタスクとモデルには、ベクトル化以外にもカテゴリ分類や画像・音声処理などがあります。

ベクトルデータのインサート
Supabaseの各種サービスを利用するためのJSのSDK@supabase/supabase-jsを使用します。
共通関数として別ファイル_shared/pg-client.tsに定義します。
import {createClient} from 'https://esm.sh/@supabase/supabase-js@2'
export const supabase = createClient(
// Supabase API URL - env var exported by default.
Deno.env.get('SUPABASE_URL')!,
// Supabase API ANON KEY - env var exported by default.
Deno.env.get('SUPABASE_ANON_KEY')!
)
先ほど作成したベクトル化のEdgeファンクションを修正します。supabase.from('posts').insertで生成したベクトルデータをインサートします。
import {serve} from 'https://deno.land/std@0.168.0/http/server.ts'
import {env, pipeline} from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.5.0'
import {supabase} from "../_shared/pg-client.ts";
(省略)
serve(async (req) => {
const {title, body} = await req.json(); // POSTパラメータ titleとbody
// bodyをベクトル化する
const output = await pipe(body, {
pooling: 'mean',
normalize: true,
});
(省略)
// Postgresのpostsテーブルにインサートする。
const {error} = await supabase.from('posts').insert({
title,
body,
embedding, // ベクトルデータ
})
以下の3つの検証用のデータをインサートしておきます。後で利用します。
title, body
Japan, I like Kyoto and Japanese food such as Sukiyaki and Sushi!
Japan, Japanese yen is weak against the dollar.
US, Apple released iPhone 15 and iPod Air.

データベース・ファンクションの作成
データベース・ファンクションとはストアードプロシージャのことです。DBサーバ上でプログラムを実行します。DBに近いところでプログラムを実行できるため通信のオーバーヘッドが無く、膨大なデータの処理をするときに向いています。
また、Supabaseのライブラリが複雑なクエリーをサポートしていないためストアードで実装する必要があります。
ベクトル同士の比較はドット積<#>を使用します。ベクトルの生成時にベクトルを正規化したことを思い出してください。Postgresの演算子がASC順のインデックスしかサポートしていないためドット積は-1が一番類似度が高くなります。スコア値の計算のところで再度-1して戻しています。
posts.embedding <#> query_embedding // -1 が類似度が高い
create or replace function match_documents_dot (
query_embedding vector(384), # インプット・パラメータ
match_threshold float, # スコアのフィルター条件
match_count int # 取得件数
)
returns table ( # 戻り値
id bigint,
title text,
body text,
similarity float # スコア(類似度が高いと1に近づく)
)
language sql stable
as $$
select
posts.id,
posts.title,
posts.body,
(posts.embedding <#> query_embedding) * -1 as similarity # スコア
from posts
where (posts.embedding <#> query_embedding) * -1 > match_threshold # スコアのフィルター条件
order by similarity desc # スコアでソート
limit match_count;
$$;
インデックスの作成
データベースと言えばインデックスの作成がとても重要になります。インデックスが正しく作成されていないとフルスキャンになりパフォーマンスが悪化します。
ベクトル・カラム用のインデックスにはIVFとHNSWがあります。どちらも近似最近傍探索(ANN)になります。愚直に全てのベクトル間のコサイン類似度を求めるのではなく、近似的な計算で精度を犠牲にしてスループットを追求する手法です。
create index on posts using ivfflat (embedding vector_ip_ops)
with
(lists = 100);
# HNSWの場合は、ivfflatをhnswにする。
# コサイン類似度の場合は、vector_ip_opsをvector_cosine_opsにする。ipはinner product(内積)
# https://github.com/pgvector/pgvector#ivfflat
HNSWの方が後発でパフォーマンスと精度が向上したようです。一方で、インデックスが遅い、メモリを多く消費する欠点があるようです。
クエリー
長くなりましたが以上でデータの準備が整いました。さて、いよいよ類似検索をしましょう。RPCで先ほど作成したデータベース・ファンクションを叩きます。supabase.rpc('match_documents_dotのようにコールします。
serve(async (req: { json: () => PromiseLike<{ query: any; }> | { query: any; }; }) => {
const {query} = await req.json()
const output = await pipe(query, {
pooling: 'mean',
normalize: true,
})
const embedding = Array.from(output.data) // クエリーをベクトル化する
// RPCでストアード・ファンクションを呼び出す。
const {data: documents, error} = await supabase.rpc('match_documents_dot', {
query_embedding: embedding,
match_threshold: 0.00, // 閾値
match_count: 10, // 検索結果数
})
return new Response(JSON.stringify(documents), {
headers: {'Content-Type': 'application/json'},
})
実行しましょう。cURLで呼び出します。
curl -X POST --location "https://osiqudxwqwndsdvulexl.supabase.co/functions/v1/pgvector-hf" \
-H "Authorization: Bearer ANONキー" \
-H "Content-Type: application/json" \
-d "{\"query\": \"I visited Tokyo and Osaka, and went to Mt. Fuji.\"}"
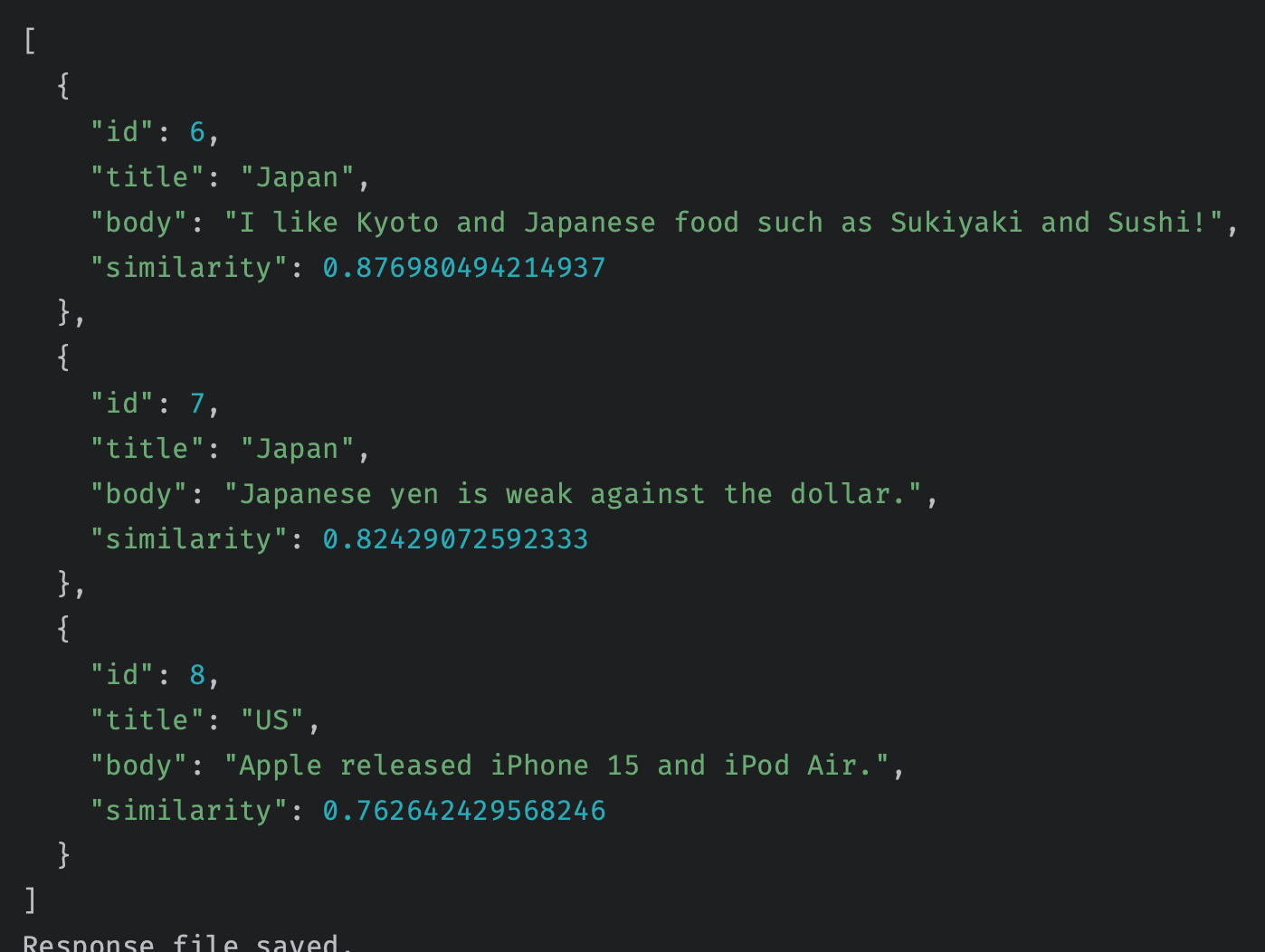
実行結果です。日本の観光に関連した文章の類似度が高くなりました。クエリーに使用した単語Tokyo, Fujiは含まれていませんが、それに近い単語のKyoto, Sushiが含まれた文章のスコア値が高くなりました。
本番へのデプロイ
クラウド環境にデプロイしましょう。--project-refにデプロイ先のプロジェクトIDを指定します。プロジェクトIDはダッシュボードを開いた時のURLhttps://supabase.com/dashboard/project/(この部分)になります。
supabase functions deploy --project-ref (プロジェクトID)
APIのエンドポイントは、https://(プロジェクトID).supabase.co/functions/v1/pgvector-embedになります。
SQLの例
WHERE句で絞り込みをしてから、ベクトル検索します。
SELECT * FROM posts WHERE title = 'Japan' ORDER BY posts.embedding <-> '[0.1,0.2,...]';
タイトル毎にベクトルの平均値AVGを求めます。
SELECT title, AVG(embedding) FROM posts GROUP BY title;
Huggingface
最後に、Supabase EdgeからHugginfaceのInference APIを呼び出すAPIをご紹介します。この場合、Huggingfaceのサーバ側でタスクが実行されます。
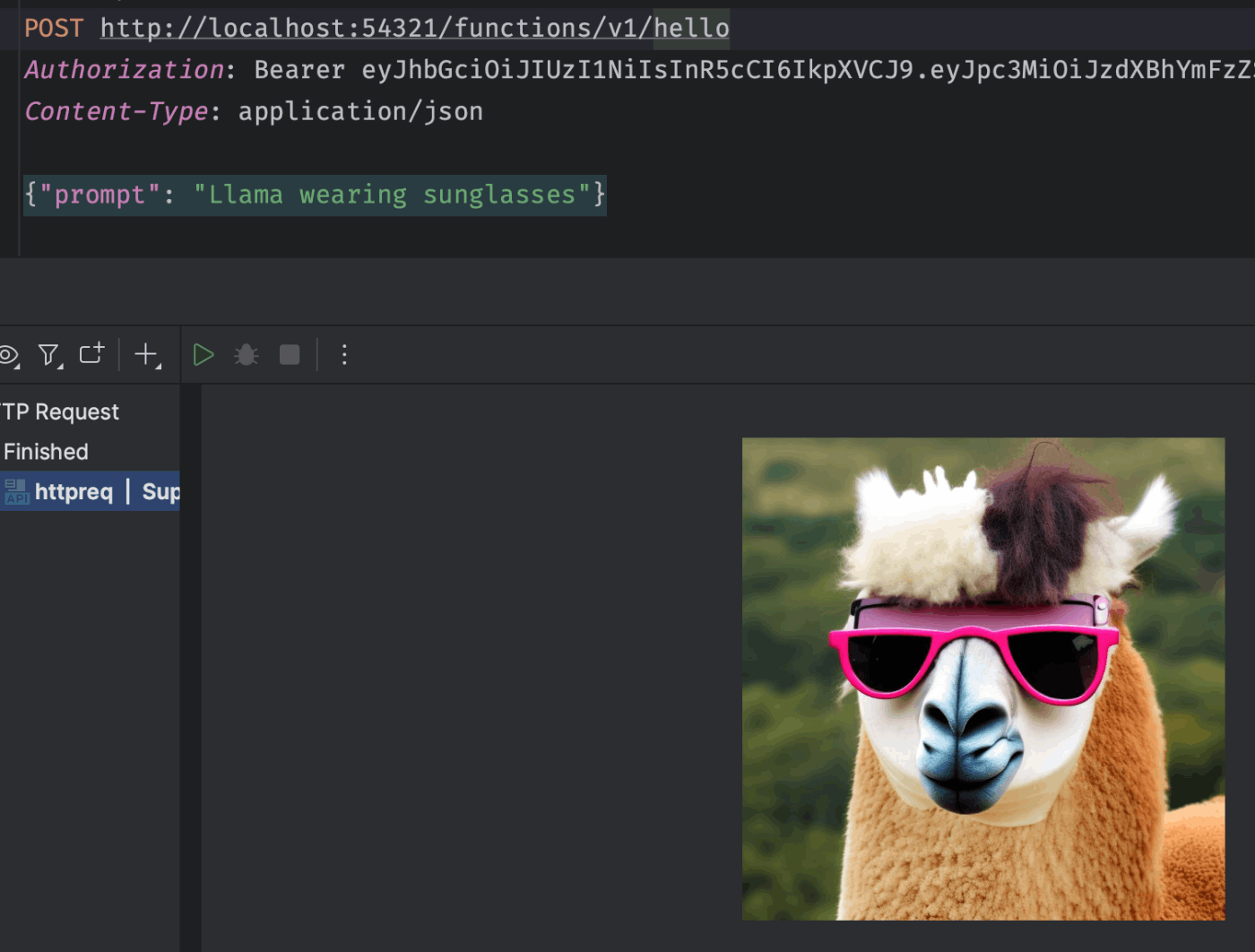
次のサンプルは、プロンプトから画像を生成するものです。OpenAIのDALL·E 3のようなものです。
import { serve } from 'https://deno.land/std@0.168.0/http/server.ts'
import { HfInference } from 'https://esm.sh/@huggingface/inference@2.3.2'
const hf = new HfInference(Deno.env.get('HUGGING_FACE_ACCESS_TOKEN'))
serve(async (req) => {
const { prompt } = await req.json()
const image = await hf.textToImage(
{
inputs: prompt,
model: 'stabilityai/stable-diffusion-2',
},
{
use_cache: false, // プロンプトをキャッシュする
}
)
return new Response(image)
})
cURLなどで呼び出します。
curl -X POST --location "http://localhost:54321/functions/v1/hf-image" \
-H "Authorization: Bearer ANONキー" \
-H "Content-Type: application/json" \
-d "{\"prompt\": \"animation character like hybrid of rabbit and cat\"}" \
--output result.jpg
ベクトル化の場合はfeatureExtractionを使用します。
const embedding = await hf.featureExtraction({
model: "sentence-transformers/distilbert-base-nli-mean-tokens",
inputs: prompt,
});
Discussion