オレオレChatGPTのかんたん実装 (Google検索 + ベクトル検索)
いやあChatGPTすごいですね。最近は、ググる→StackOverflowの機会がグンと減りました。Copilotも便利ですね。エンジニアに求められるスキルが大きく変わりそうです。
そんな革命的なChatGPTですが、残念ながらオープンソースではないためカスタマイズができません。そこでこのブログでは、ChatGPTクローンのオープンソースのChatbot UIを使っての俺流ChatGPTの作り方をご紹介します。ソースコードはこちら。
それでは以下の順に説明していきたいと思います。
- ChatbotUIとは?
- Google検索プラグイン
- ベクトル検索プラグイン
1. ChatbotUIとは?
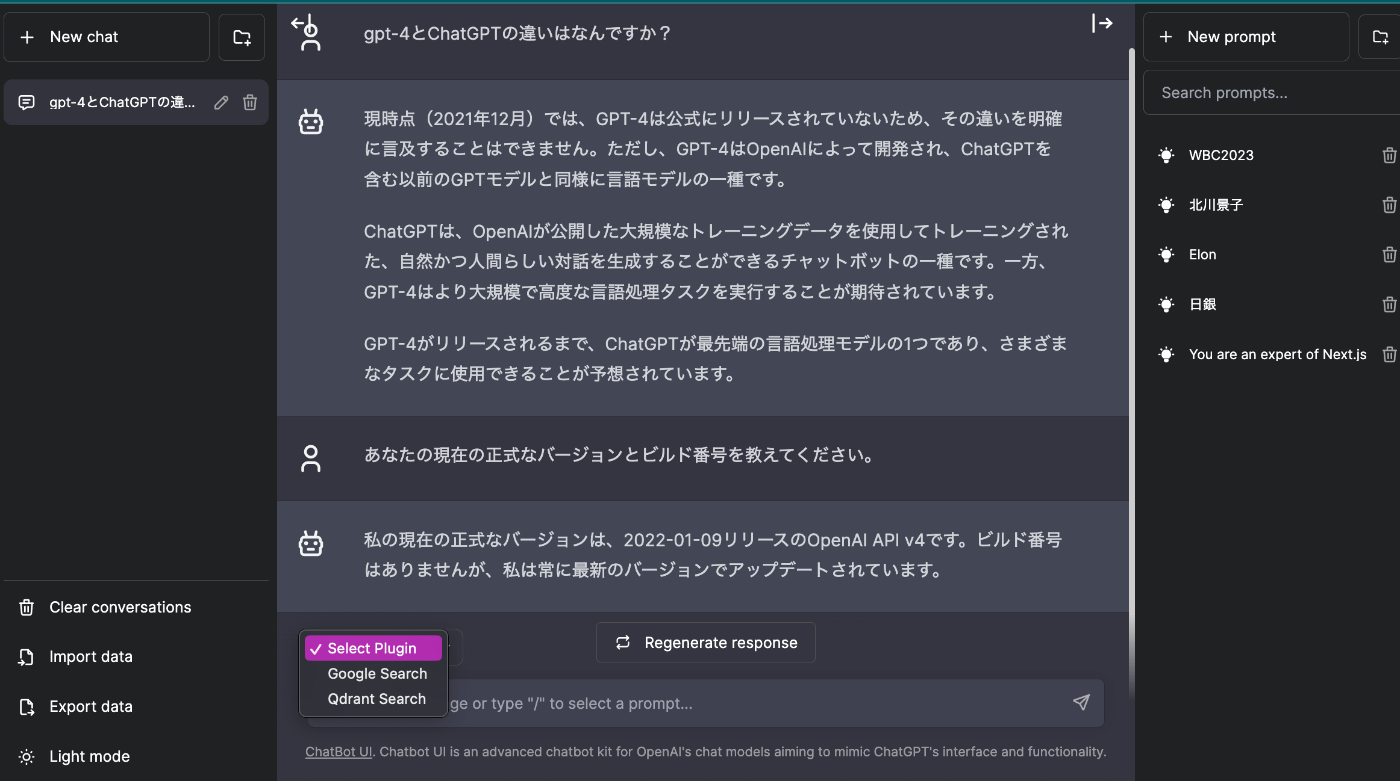
公式ChatGPTと見た目も機能もほぼ同じです。違うところは右側にサイドバーがあり、ここによく使うプロンプトを登録しておくことができます。プロンプトの入力で/(スラッシュ)をタイプすると登録したプロンプトが補完されます。プラグインを組み込めるようになっていますが、公式のプラグインとは互換性はありません。
内部的にはOpenAPI APIを呼び出しています。利用するには環境変数にご自身のAPIキーを登録する必要があります。
実装技術
今やWebアプリのデファクトスタンダードとも言えるNext.jsで実装されています。基本はSPAな作りでpagesを使用したSSR(getServerSideProps)です。Next.jsのapiがOpenAI API呼び出しへのプロキシーになっています。TypeScript、Tailwindを使用しています。状態管理にはlocalStorageを使用しています。recoil、axios、TanStack等は使用していません。LangChainのライブラリも使用していません。不思議と国際化対応i18nがされています。
かなり原始的な作りですが、シンプルでソースコードを読むのは楽です。
面白いなと思ったところ
ストリーミング処理とWebassemblyの使用は興味深いことろです。
OpenAIのAPIはストリーミング処理をサポートしていますので、ChatbotUIでもレスポンスはチャンクでパラパラと出力されます。
トークン数を数えるためのtiktokenのエンコーダーのロードにwebassemblyが使用されています。Vercelのエッジサーバなどリソースに制約のある環境で動かすことを想定したものです。
2. Google検索プラグイン
まずはGoogle検索プラグインを動かしてみましょう。ここで言うプラグインとはChatbotUI独自のプラグインです。ChatGPT公式のプラグインとは違います。このプラグインを使用すると、プロンプトの内容でGoogle検索を実行します。オリジナルのプロンプトに検索結果を添えてOpenAI APIのchat/completionsを呼び出します。OpenAIの学習モデルは2021年以降の情報を持たないため、Google検索で最新情報を教えてあげるわけです。この手法はBingChatでも使用されています。
Google Custome Search API
Google検索をAPIで利用するにはGoogle Custom Search APIを有効にしてAPIキーを払い出す必要があります。1日100リクエストまでは無料で使用できます。それ以降は0.6円/リクエストです。念の為、リクエスト数にQuotaを設定しておくと安心でしょう。APIキーに制限も加えておいてください。こちらにGoogle Mapに関しての説明がありますので、Custom Search APIに読み替えて実施してください。
次にProgrammable Search Engineを作成する必要があります。以下のように検索対象のドメインを登録します。ex. ja.wikipedia.org/wiki/*
作成が完了するとSearch engine IDが割り当てられます。
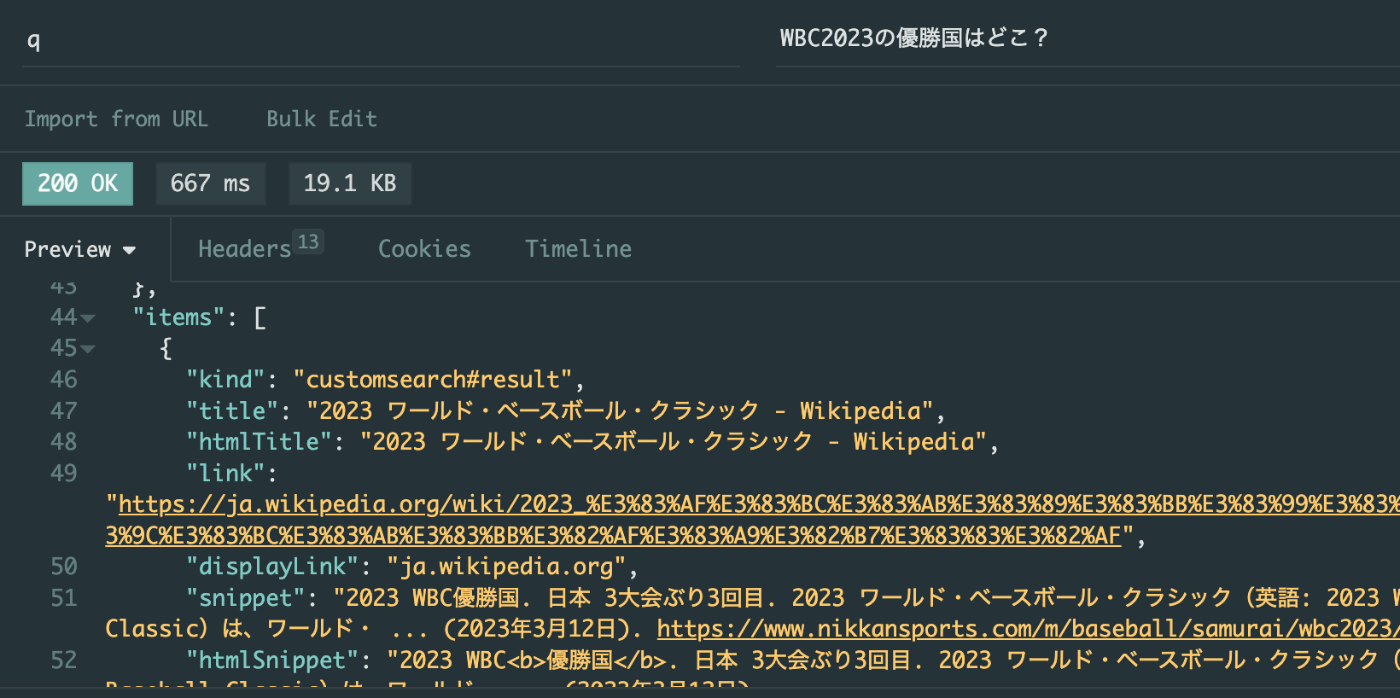
cURLで動作確認をしましょう。取得したAPI Key、Search engine ID、クエリー文字列をGETパラメータに渡します。
curl --request GET \
--url 'https://customsearch.googleapis.com/customsearch/v1?key=(API Key)&cx=(Search engine ID)&q=(クエリー)'
itemsに検索結果一覧が返ります。Insomniaでの実行例。
Chatbot UIからGoogle検索を利用するには?
入力ボックスの稲妻アイコンをクリックするとプラグインを選択することができます。Google Searchを選択します。

実はトークン数が多すぎる理由でしばしばエラーになります。日本語はトークン数が英語の約2倍になるのですが、どうやらそのあたりの考慮がされていないようですう。
次の2箇所を修正します。それでも動かない場合はさらに数値を減らしてください。
const googleRes = await fetch(
`https://customsearch.googleapis.com/customsearch/v1?key=${
googleAPIKey ? googleAPIKey : process.env.GOOGLE_API_KEY
}&cx=${
googleCSEId ? googleCSEId : process.env.GOOGLE_CSE_ID
}&q=${userMessage.content.trim()}&num=4`, // 検索結果を4件に減らす
);
return {
...source,
// TODO: switch to tokens
text: sourceText.slice(0, 500), // 500文字に減らす
} as GoogleSource;
では、何か質問してみましょう。先日のWBC(2023年)の優勝国を聞いてみましょう。もちろん、公式のChatGPTは2021年までしか知りません。

Google検索プラグインを使用した場合(上側)は2023年の情報が反映されているのがわかります。
コードの説明
ソースコードを少し説明します。
pages/api/google.tsを見ると以下のようなテンプレートがあるのが分かるかと思います。質問と答えのサンプル(お手本)を与えます。この手法はone-shot promptingと呼ばれ、回答の精度が上がります。
const answerPrompt = endent`
Provide me with the information I requested. Use the sources to provide an accurate response. Respond in markdown format. Cite the sources you used as a markdown link as you use them at the end of each sentence by number of the source (ex: [[1]](link.com)). Provide an accurate response and then stop. Today's date is ${new Date().toLocaleDateString()}.
Example Input:
What's the weather in San Francisco today?
Example Sources:
[Weather in San Francisco](https://www.google.com/search?q=weather+san+francisco)
Weather in San Francisco is 70 degrees and sunny today.
Example Response:
It's 70 degrees and sunny in San Francisco today. [[1]](https://www.google.com/search?q=weather+san+francisco)
Input:
${userMessage.content.trim()}
Sources:
${filteredSources.map((source) => {
return endent`
[${source.title}] (${source.link}):
${source.text}
`;
})}
Response:
`;
このテンプレのfilteredSourcesのところにGoogle検索結果(Wikipediaのコンテンツ)をねじ込みます。

完成系のプロンプトです。これでOpenAI APIのchat/completionsを呼び出します。

Google先生の場合は関連するページへのリンクだけを教えてくれ、あとは自分で読めや。広告も見ろよ。クリックしてくれたら最高っすなのですが、ChatGPT先生はページに目を通し、答えの部分だけを教えてくれる、とてもあまあまな先生なのです。
3. ベクトル検索プラグイン
前置きが長くなりましたが、いよいよベクトル検索機能を実装しましょう。ここではベクトル検索エンジンQdrantを使用します。
ベクトルデータ自体は前もって用意しておく必要があります。例のごとく、ライブドアニュースを使用しました。詳細はこちらの記事をご覧ください。
プラグインの実装
次の3つのステップで構成されます。
- ユーザが入力したプロンプトをOpenAI APIを使用してベクトル化します。(getEmbedding)
- ベクトル検索エンジンAPIを呼び出し、似ている文書一覧を取得します。(fetchContents)
- OpenAI APIを呼び出して、回答を得ます。(getAnswerFromChatGPT)
// a handler for Qdrant
export default async function qdrantHandler(
req: NextApiRequest,
res: NextApiResponse<any>,
): Promise<any> {
try {
const { messages, key, model } = req.body as ChatBody;
const userMessage = messages[messages.length - 1]; // prompt from user
// 1. get a vector of the user prompt using OpenAI API
const vector = await getEmbedding(userMessage.content.trim(), key);
// 2. get a list of docs that are similar to the vector using Qdrant API
const sourcesWithText = await fetchContents(vector);
// 3. get an answer from ChatGPT(OpenAI API) using the augmented prompt
const answer = await getAnswerFromChatGPT(
userMessage,
sourcesWithText,
key,
model,
);
以下に、3つの関数を詳しくみていきます。
getEmbedding
プロンプト文字列を浮動小数点のベクトル(1536次元)に変換します。OpenAI API以外の手段でベクトル化しても良いのですが、Node.js上で実行する必要があるためPython実装のライブラリ(ex. GiNZA)が使用できないはまりポイントがあります。そこでコストがかかりますが、OpenAI API Embeddingを使用することにしました。
// fetch a vector of the given text using OpenAI API
async function getEmbedding(title: string, key?: string): Promise<number[]> {
const response = await fetch('https://api.openai.com/v1/embeddings', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${key ? key : process.env.OPENAI_API_KEY}`,
},
body: JSON.stringify({
input: title,
model: 'text-embedding-ada-002',
}),
});
fetchContents
次は取得したベクトルを使用して、Qdrantベクトル検索エンジンから似ている文章の一覧を取得します。ここで大事なことは、クエリーに使用するベクトルとQdrantに保存されているベクトルは同じ手法でベクトル化したものである必要があることです。
// fetch similar docs to the given vector from Qdrant search engine
// vector size should be 1536, which is created by OpenAI API
async function fetchContents(
vector: number[],
collName: string = 'livedoor-openai-summary',
): Promise<GoogleSource[]> {
const body = {
vector, // クエリーのベクトル値
with_payload: true,
with_vector: false,
limit: 3,
};
const QDRANT_URL = process.env.QDRANT_API_URL || 'http://localhost:6333';
const response = await fetch(
`${QDRANT_URL}/collections/${collName}/points/search`,
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(body),
},
);
getAnswerFromChatGPT
最後にオリジナルのプロンプトにベクトル検索結果をねじ込んで、OpenAI APIのchat/completionを呼び出します。
export async function getAnswerFromChatGPT(userMessage: Message, filteredSources: GoogleSource[], key: string, model: OpenAIModel): Promise<string> {
const answerPrompt = endent`
Provide me with the information I requested. Use the sources to provide an accurate response. Respond in markdown format. Cite the sources you used as a markdown link as you use them at the end of each sentence by number of the source (ex: [[1]](link.com)). Provide an accurate response and then stop. Today's date is ${new Date().toLocaleDateString()}.
Example Input:
What's the weather in San Francisco today?
Example Sources:
[Weather in San Francisco](https://www.google.com/search?q=weather+san+francisco)
Weather in San Francisco is 70 degrees and sunny today.
Example Response:
It's 70 degrees and sunny in San Francisco today. [[1]](https://www.google.com/search?q=weather+san+francisco)
Input:
${userMessage.content.trim()}
Sources:
${filteredSources.map((source) => {
return endent`
[${source.title}] (${source.link}):
${source.text}
`;
})}
Response:
`;
const answerMessage: Message = {role: 'user', content: answerPrompt};
console.log(answerMessage)
const answerRes = await fetch(`${OPENAI_API_HOST}/v1/chat/completions`, {
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${key ? key : process.env.OPENAI_API_KEY}`,
...(process.env.OPENAI_ORGANIZATION && {
'OpenAI-Organization': process.env.OPENAI_ORGANIZATION,
}),
},
method: 'POST',
body: JSON.stringify({
model: model.id,
messages: [
{
role: 'system',
content: `Use the sources to provide an accurate response. Respond in markdown format. Cite the sources you used as [1](link), etc, as you use them. Maximum 4 sentences.`,
},
answerMessage,
],
max_tokens: 1000,
temperature: 1,
stream: false,
}),
});
const {choices: choices2} = await answerRes.json();
console.log(choices2)
console.log(answerRes.status)
return choices2[0].message.content;
プラグインとして組み込む
2つのファイルを修正します。これでGUIからプラグインを選択できるようになります。
if (plugin.id === PluginID.QDRANT_SEARCH) {
return 'api/qdrant';
}
[PluginID.QDRANT_SEARCH]: {
id: PluginID.QDRANT_SEARCH,
name: PluginName.QDRANT_SEARCH,
requiredKeys: [],
},
};
実行してみよう
次の質問を英語でしてみました。(英語の方が精度が良いので英語ベースでベクトル化しています)
オリコンの調査によると、スマートフォンの損傷の一般的な原因は何ですか?

日本語訳
オリコンの調査によると、スマートフォンが破損する主な原因は、水没が36.8%、画面が割れることが33.3%、落下により正常に起動しなくなることが18.4%である。[1]この調査は、従来の携帯電話と比較して、スマートフォンの画面の大きさのために画面がより損傷しやすいとされている。調査では、防水ケースを使用する、ストラップを使用して落下を防止するといった予防策も提供されていた。
公式のChatGPTではハルシネーション(嘘)が発生しましたが、ベクトル検索プラグインでは正しく答えることができました。
4. 補足
公式ChatGPT Pro
月額$20で使い放題でgpt-4を使うことができます。私はまだ順番が回ってこないですがプラグイン拡張も利用できます。内部的には4096トークンの制約も無いでしょうし、実際に裏でどのようなプロンプトを投げているのかはブラックボックスです。OpenAI APIに比べるとレスポンスが爆速であります。ずるいです。Azure版のAPIも試したいところです。
さらなる改良、課題について
ChatbotUIの開発は進んでいるようで、最近はtemparatureが追加されました。Google検索結果をベクトル検索エンジンに保持(記憶)する機能があると便利かなと思いました。最近はAutoGPTが流行っているようでGPTを利用したツール、サービスが色々出てきそうです。その一方で、マネタイズの問題があり、gpt-4ではコスト的にかなり厳しい気もしますし、OpenAIのgpt-3.5 turboではパフォーマンスや安定性に問題があります。当面はAzureでエンタープライズで利用されていくのかなと感じます。
Discussion