GCP GPU T4 インスタンスで Elyza, gpt-oss, Gemma を動かす
GCPクラウドのGPUインスタンス NVIDIA T4を使用して、Elyza、gpt-oss、Gemmaを動かす手順書になります。おまけで、Ollamaもやります。
GCPインスタンスの作成
まずはじめに、GCPコンソールからVMインスタンスを作成します。
GPUs > NVIDIA T4を選択します。

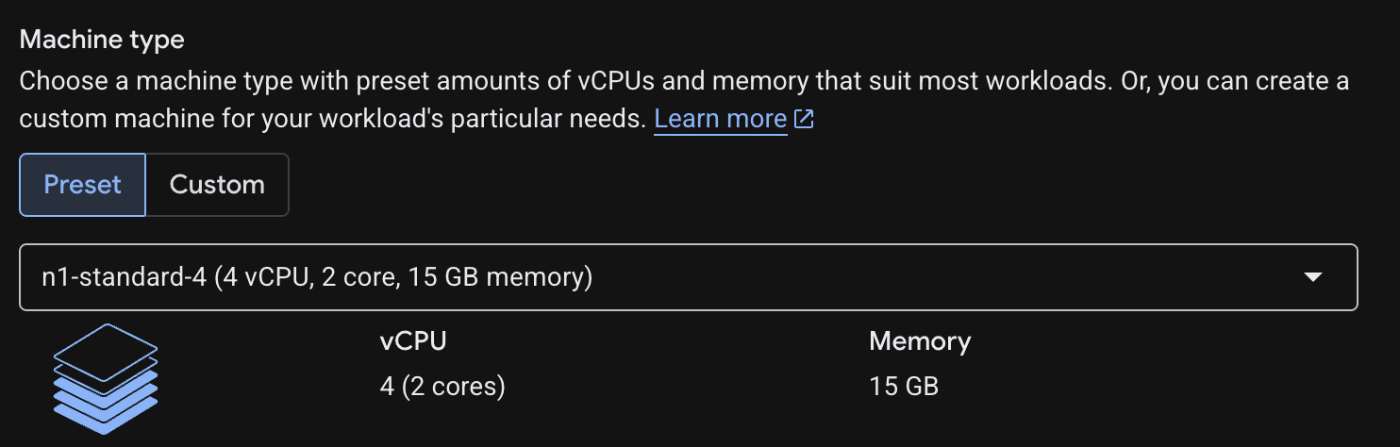
マシン・タイプをn1-standard-4 (4 vCPUs, 15 GB Memory)に変更します。
次に、OSを変更します。Switch imageをクリックします。
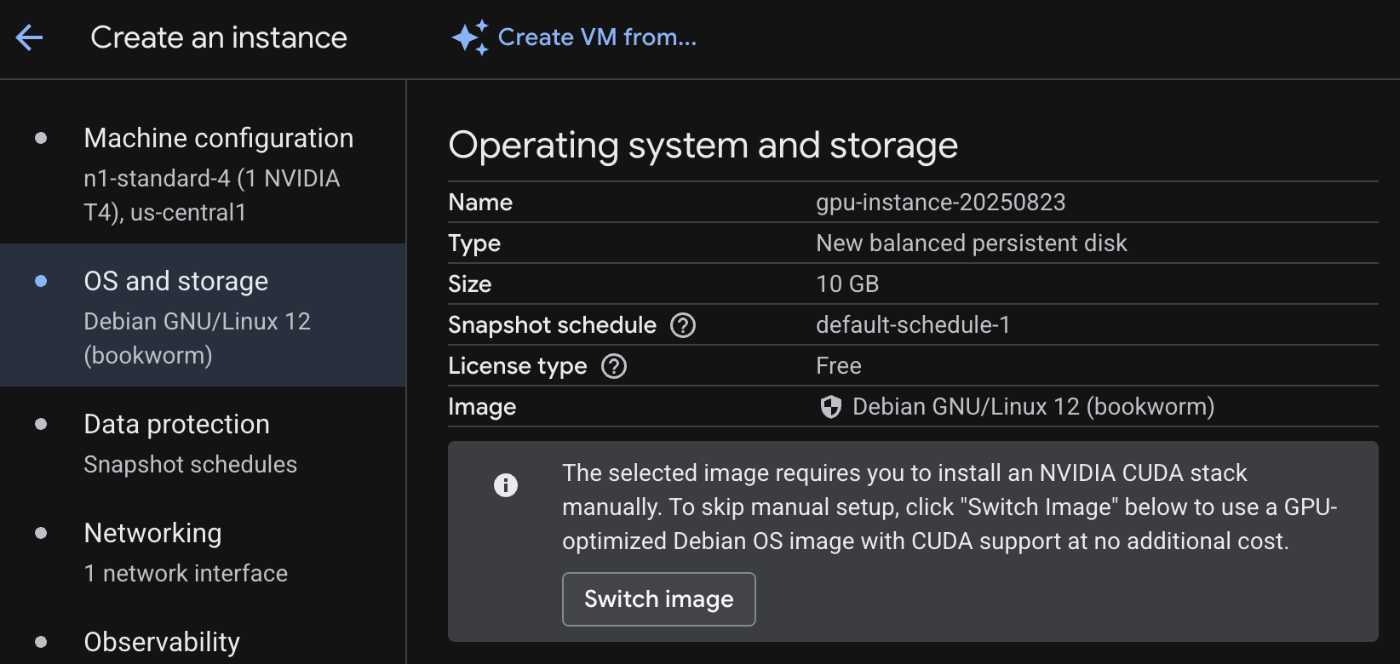
Deep Learning VM with CUDA 12.4 を選択します。ディスク容量も、LLMモデルのダウンロードでたくさん必要でので500GBに増やしておきましょう。

月額の使用料金の見積もりは、$325.94 ($0.45 hourly) ほどになります。
SSHログインする
インスタンスの作成が完了したら、SSHでログインします。引数はよしなに変更してください。
gcloud compute ssh --zone "us-central1-f" "gpu-instance-20250823" --project "my-project-1"
初回ログイン時に、Nvidiaドライバーをインストールするか聞かれます。
Would you like to install the Nvidia driver? [y/n]
yとタイプして、インストールします。
nvidia-smiコマンドを実行し、正常にドライバーがインストールされたか確認します。

uvをインストールします
uvをインストールします。
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
uv --version
次に私が作成したサンプル・コード一式をgit cloneします。
ディレクトリに移動し、uv venvを実行します。
こんな感じです。

uv syncを実行します。PyTorchなどの必要なライブラリがバーチャル環境にインストールされます。
簡単なプログラムで動作確認する
念の為、PyTorchからGPUが利用できるか確認しておきます。
サンプル・コードのcheck_gpu.pyを実行します。
uv run check_gpu.py

以上で設定は完了です。次にLLMsを動かしていきましょう。
Elyzaを動かす
Elyza(elyza/ELYZA-japanese-Llama-2-7b-instruct)を動かしてみます。
ソースコードはこちらになります。
コードの中で、日本食の特徴は何ですかと聞いています。uv run transformer_jp_elyza.pyで実行します。モデルがメモリに乗ってから、約10秒ほどで答えが返ってきます。

gpt-oss 20Bを動かす
先日リリースされたOpenAIのオープン・ウェイトモデル(openai/gpt-oss-20b)を動かしてみます。
必要に応じて max_new_tokens を調整してください。
実行します。さすがですね。

余談ですが、日本食は海外に比べると、薄味で、化学調味料が少ないです。ただ、塩分が多いかなとは思います。
Gemma
Googleのオープン・ウェイトモデル(google/gemma-3-270m-it)を動かしてみます。
単位が、BではなくMからも分かるようにかなり小型のLLMになります。
少し面倒ですが、Huggingfaceにアカウントを作成し、Gemmaの利用許諾書にOKする必要があります。していない場合は、モデルのダウンロードで403エラーが発生します。

許諾した上で、APIトークンを払い出してください。
環境変数にAPIトークンを設定します。
export HUGGINGFACE_HUB_TOKEN=hf_qLG...
ソースコードになります。
こちらのコードは、WEELさんのブログ記事を参考にさせていただきました。AI関連の情報を幅広くカバーしており、大変参考になる素晴らしいサイトです。
実行します。やはり、小型のモデルですのでファイン・チューニング無しでは、あまり良い回答は得られません。

Ollama
ローカルLLMを動かす場合は、OllamaやvLLMを使用した方が楽かと思います。
Ollamaは至って簡単です。
curl -fsSL https://ollama.com/install.sh | sh
ollama --version
gpt-oss:20bを動かしてみましょう。
ollama run gpt-oss:20b "日本食の特徴はなんですか?"
結果です。
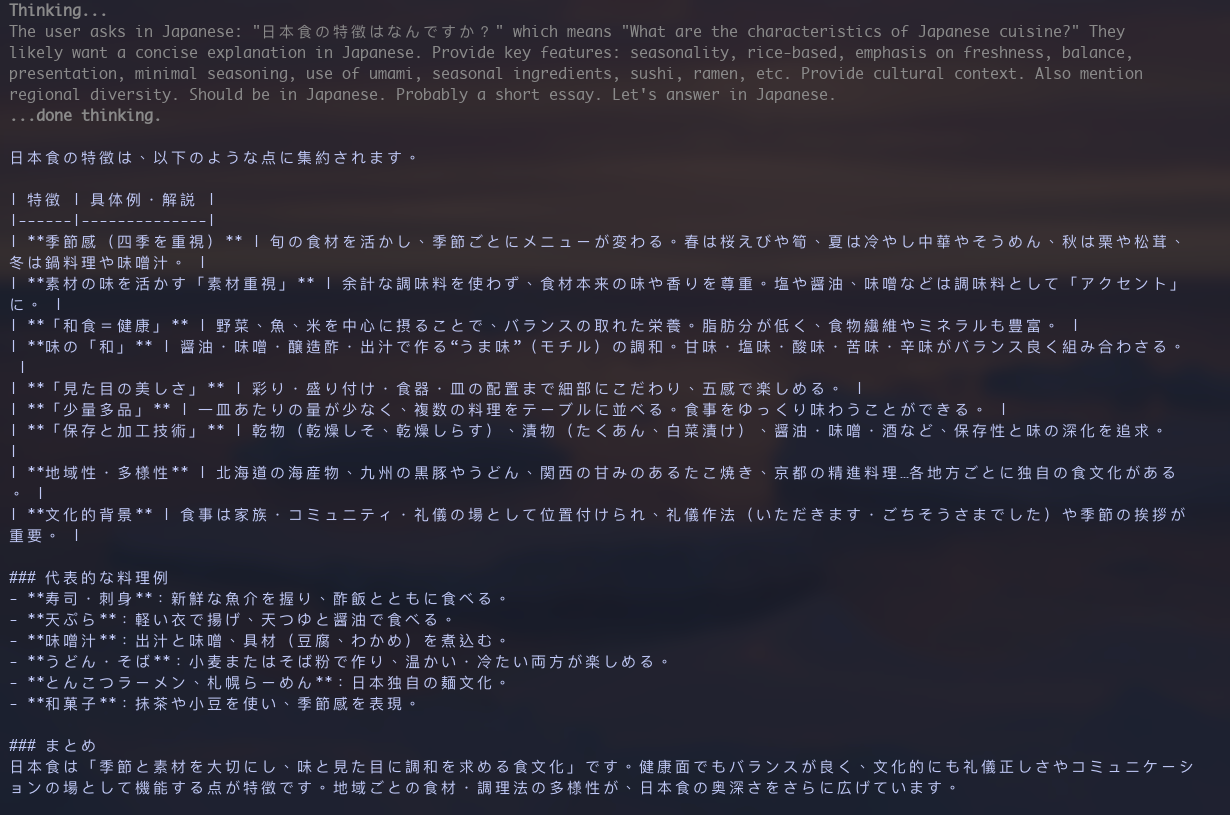
gpt-5には劣りますが、なかなかのクオリティです。
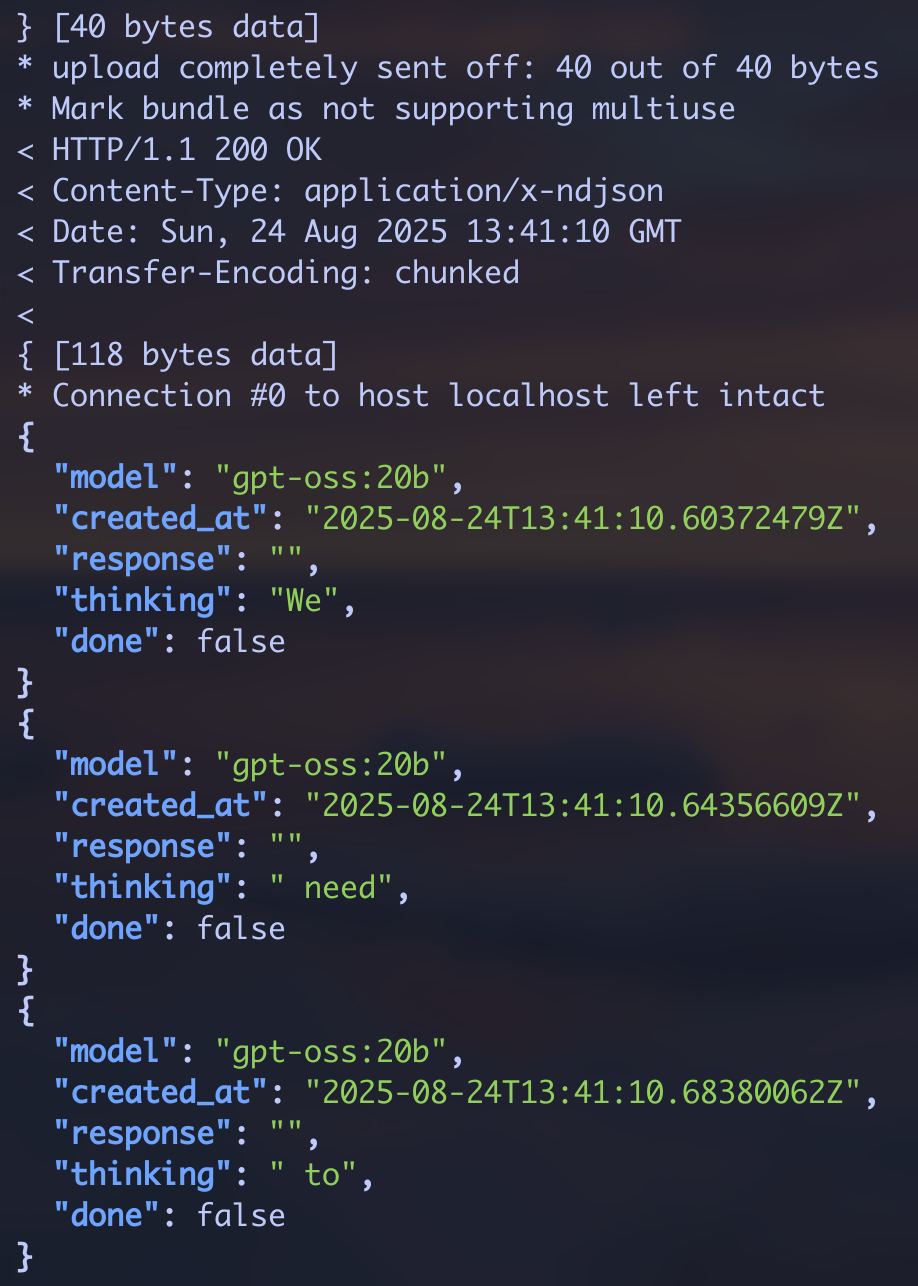
また、OllamaはHTTP経由で呼び出すことも可能です。
curl -s http://localhost:11434/api/generate -d '{"model":"gpt-oss:20b","prompt":"Hello"}' | jq .
このようにチャンクで返してくれます。
終わりに
数年前、筆者はTensorFlowでディープラーニングをしていたこともありますが、その時に比べると、LLM環境の構築がかなりお手軽にできることに驚きました。
ここで取り上げたLLM以外にも、メタのLLaMA、中国系のDeepSeek、ヨーロッパのMistralなどのLLMも存在します。
OpenAI APIと比較したとき、ローカルLLMの利点としてはインターネットの外に社内の機密情報が流れないことや、GPUのコストをある程度コントロールできること、ネットワーク自体のレイテンシが速いことがあるかと思います。
また、AWS BedrockのようにホスティングされたLLMを利用する選択肢もあります。VercelやCloudflareでプロキシーする手法もあります。
また追って紹介していきたいと思います。
Discussion