🐍
GoogleのNER LangExtractでエンティティ抽出をやってみた
本記事は、Google謹製の文章からエンティティを抽出するPythonライブラリLangExtractの紹介になります。
ユースケースとしては、ニュース記事などの非構造化データから、人物名など特定のキーワードを抽出し、文章にタグをつけたり、グラフDBを作成することで、RAGのコンテキストの精度を高めることができます。
インストール方法
Pythonのライブラリをインストールします。
langextractのインストール
uv add langextract
Gemini APIキー
Gemini APIには無料枠がありますので今回をこれを利用します。Google AI StudioからAPIキーを払い出します。
GEMINI_API_KEYにセットしてください。
ソースコード
コードはとてもシンプルです。
prompt_descriptionにシステム・プロンプトを記述します。
examplesにfew-shotを記述します。
import langextract as lx
result = lx.extract(
text_or_documents=clinical_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
ざっと公式のサンプル・コードを載せます。
英語プロンプトになりますが、薬とその処方に関しての文章になります。後ほど、日本語バージョンも説明します。
実行する
uvプロジェクトになってます。venvで環境を作成し、実行します。
実行する
uv venv
uv run sample2.py
この手のはLLMに清書してもらうと分かりやすいです。
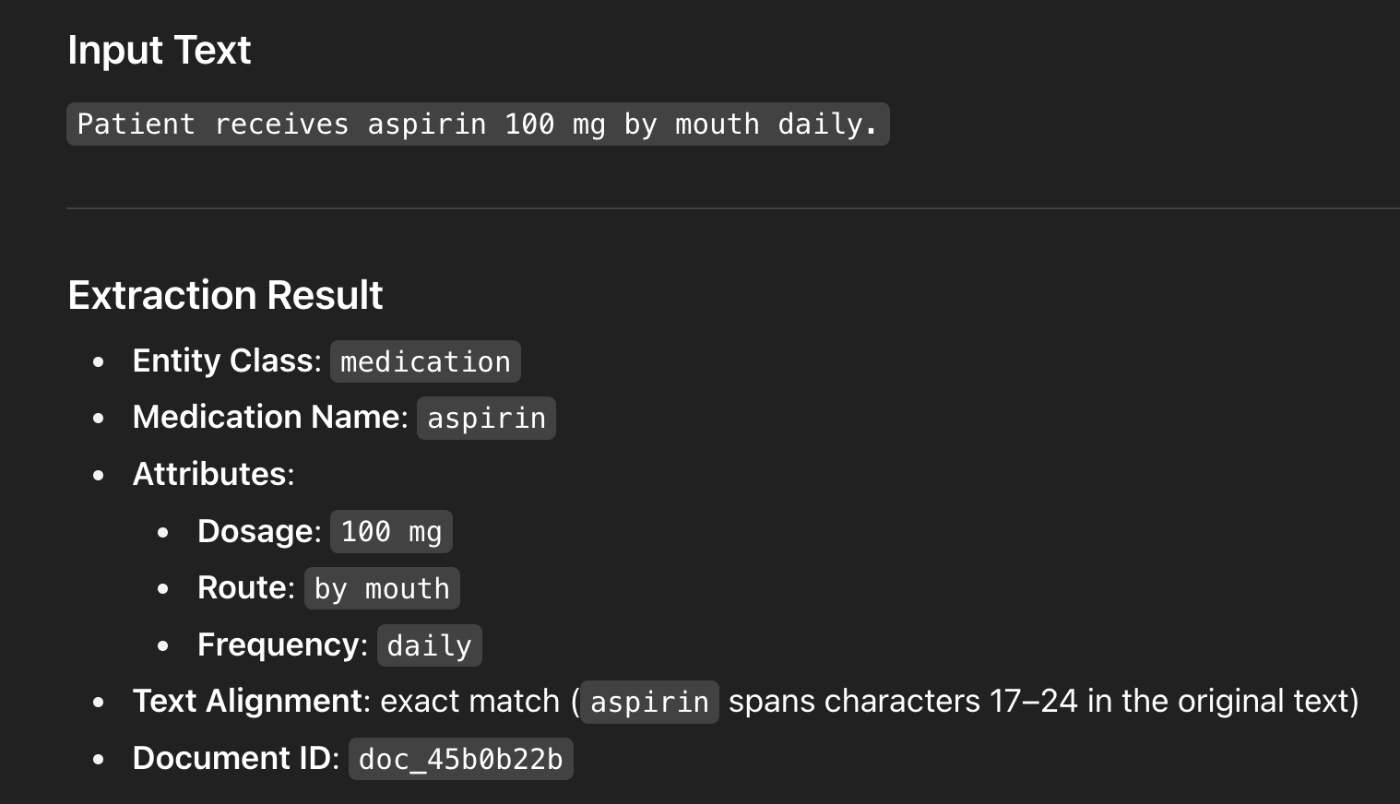
よく出力を見ると、何文字目に抽出した単語aspirinがあるかも返してくれます。
試しに日本語でも試してみました。このように正確に抽出することができました。

2025年9月4日のお天気ニュースのページを抽出してみました。

オリジナルのコンテンツはお見せできませんが、かなり正確に抽出しています。自分の住んでいる地域の情報だけを知りたい場合に便利です。
Ollama gemma2:2b で検証
ollama gemmaのインストール
brew install ollama
brew services start ollama
ollama run gemma2:2b "say hello in one short line"
ソースコードを以下のように修正します。
gemma
# Run the extraction
result = lx.extract(
text_or_documents=clinical_text,
prompt_description=prompt,
examples=examples,
# model_id="gemini-2.5-pro", # or another suitable model
model_id="gemma2:2b", # Automatically selects Ollama provider
model_url="http://localhost:11434",
fence_output=False,
use_schema_constraints=False
)
Discussion