Neo4J - グラフDB - 導入編 ①
はじめに
本記事では、ナレッジ・グラフ・データベースである Neo4J(ニオ・フォー・ジェイと発音) をご紹介します。長くなるので3回に記事を分けて公開する予定です。
Neo4Jはクラウド版を無料(クレカ登録不要)で利用できます。また、ローカルのデスクトップ・アプリ版も提供されています。Python, Java, JavaScriptのSDKも提供されています。
また、後編では生成AIを活用したグラフRAGも説明する予定です。
ナレッジ・グラフとは?
ナレッジ・グラフとは、その名のとおり、知識をグラフで表現したものです。グラフとは、ツリー構造のように、ノードを線でつなげたものです。ノードをエンティティと呼び、実体のあるモノを表現します。一方、線をエッジと呼び、エンティティ間の関係性を表現します。
例えば、
(イーロンマスク) - [支持] -> (トランプ)
のように表現します。ここで、イーロンマスク、トランプがエンティティで、支持がエッジになります。
(イーロンマスク) - [経営] -> (テスラ) <- [所有] - (トランプ)
(イーロンマスク) - [対立] -> (ビルゲイツ) - [支持] -> (民主党) - [対立] -> (共和党)
こうした網の目のような複雑な関係性を、グラフでモデル化し、デジタル化し、生成AIも活用することで、現実世界をキャプチャーするアイデアです。
そのナレッジ・グラフの実装の一つがNeo4Jです。RDBのように、データのCRUDをを提供するデータベースと、ビジュアルに表示するツールを提供しています。これにより、人間の思考に近い形でデータのつながりを表現できるのが特徴です。
ナレッジ・グラフ自体、2000年以前から研究が進み、2012年にはGoogle検索エンジンにも取り入れられた昔からある技術です。ここ最近の生成AIブームで、文章のような非構造データからグラフを自動抽出することが可能になり、RAGのブームもあり、再び脚光を浴びるようになりました。
Cypher
Neo4Jでは、CypherというSQL風のクエリ言語を使用してデータを操作します。例えば、Aliceがフォローしているアカウントを取得するCypherは以下のようになります。
MATCH (p:Person)-[:FOLLOWS]->(f:Person)
WHERE p.name = 'Alice'
RETURN f.name
ここで、()はノード、[]はエッジを表します。これに等価なSQLは以下のようになります。
SELECT friend.name
FROM Person p
JOIN Follow f ON f.from_id = p.id
JOIN Person friend ON friend.id = f.to_id
WHERE p.name = 'Alice';
次の例は、AliceとBobの共通のフォローを取得するCypherです。
MATCH (a:Person)-[:FOLLOWS]->(f:Person)<-[:FOLLOWS]-(b:Person)
WHERE a.name = 'Alice' AND b.name = 'Bob'
RETURN f.name
これに等価なSQLは以下のようになります。このように、JOINが複雑になるのが分かります。
SELECT p2.name
FROM Person AS p2
JOIN Follows AS k1 ON k1.to_id = p2.id
JOIN Person AS a ON k1.from_id = a.id AND a.name = 'Alice'
JOIN Follows AS k2 ON k2.to_id = p2.id
JOIN Person AS b ON k2.from_id = b.id AND b.name = 'Bob';
グラフRAGとは?
グラフRAGとは、ベクトルのコサイン類似度(セマンティック検索)の代わりにナレッジ・グラフを使用したRAGのことを指します。
RAGといえばベクトル検索ですが、RAG(Retrieval Augmented Generation)とは外部のリソースからコンテンツを取得して、プロンプトを盛ることを指します。LLMはベスト・エフォートで答えを返してしまうため、不足情報をコンテキストに与え、LLMのハルシネーションを抑制することが重要です。
コンテンツを外部から取得する手法は規定されてなく、Google検索、ElasticSearch、TF-IDF、グラフDBなど別の手段も考えられます。
ベクトルRAGの問題点
ベクトルRAGの問題点は、一つの長い文章をチャンクに分割する必要があるため、文章が分断されることによって、全体のコンテキストがぼやけてしまう問題があります。
スタック・オーバーフローのようなQAの文章において、質問とその回答がチャンクで切り離されてしまう問題があります。ブログのコメントもそうです。論文のアブストラクトや、ブログの中間に埋め込まれた広告的な文章など、チャンクに分断することで、前後関係が分からなくなります。
ナレッジ・グラフではそうした問題を緩和することが可能になります。チャンク文章間のつながりをグラフで保持できるからです。マインドマップやObsidianのように、関係性の保持が可能なので、文脈を作ることができるわけです。ベクトル検索では、関係性をコサイン類似度に頼っています。例えば、ソースコードのRAGでは、import文で読み込まれたファイルを取り込むことができません。ASTのような構文解析が必要になります。
ベクトル検索 & グラフ検索のハイブリッド式
実際には、ベクトル検索とのハイブリッド方式で実装します。実は、Neo4Jではベクトル検索もサポートしています。ベクトル検索でガバッと候補を抽出し、そこからさらにナレッジ・グラフでリランキングする2段階方式が実用的でしょう。
ハイブリッド式についてはまた後日、別のブログにします。
使い方
クラウドの無料版で試してみましょう。クレカの登録は不要です。Gmail等のOAuth2でサインアップできます。ローカルで動くアプリ版もあります。
このようなJupyter Notebook風のUIでグラフDBを使用することができます。

Neo4J Auraでインスタンスを作成すると、接続のために必要なID/パスワードを設定したファイルのダウンロードが可能になります。あとでPythonプログラムからNeo4Jを使うときに必要になるので、大切に保存しておきましょう。
関係の作成
関係を作成するには、CREATE文を使用します。SQLで言えば、レコードをINSERTすることに等価です。
CREATE (a:Person {name: "Alice"})-[:FOLLOWS]->(b:Person {name: "Bob"})
スキーマは自動的に作成されますので、前もってPersonやFOLLOWSを定義する必要はありません。SQLのCREATE TABLEに相当するものはありません。スキーマを確認するには以下を実行します。
CALL db.schema.visualization()

スキーマ
検索
グラフを検索するにはMATCHを使用します。SQLで言うところのSELECT文になります。
MATCH path = (p:Person) - [:FOLLOWS] -> (b:Person) RETURN path
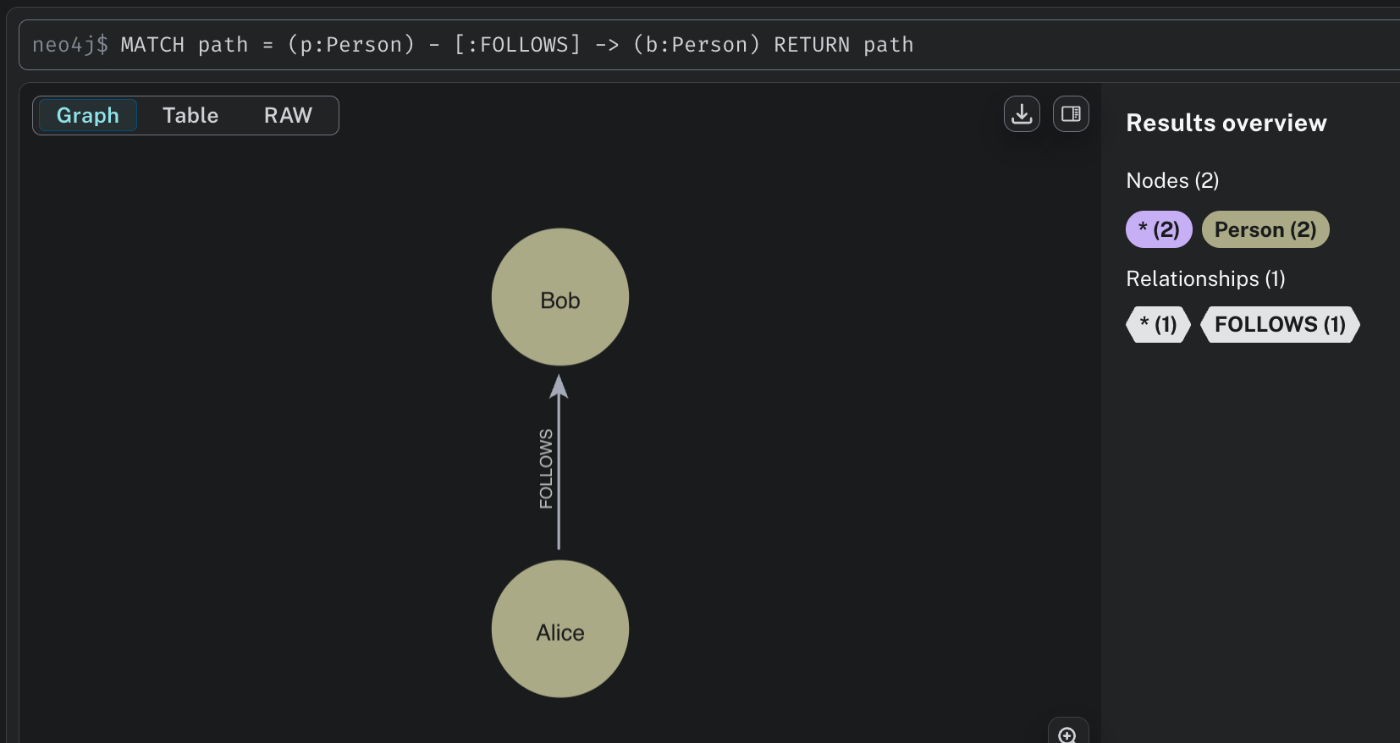
グラフの検索 MATCH
上図で、Tableタブをクリックすると、Cypherを表示してくれます。
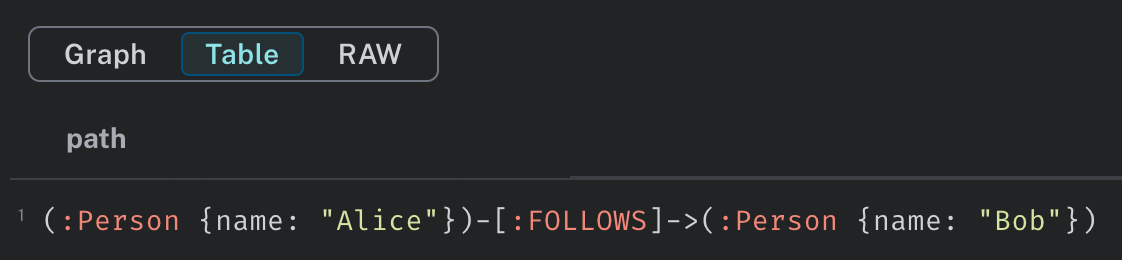
Cypher
この関係をリレーショナルDBで表現すると、SQL文は以下のようになります。CypherとSQLの比較表はこちらにあります。
SELECT
p1.id AS from_id,
p1.name AS from_name,
p2.id AS to_id,
p2.name AS to_name
FROM
Person p1
JOIN
FOLLOWS f ON p1.id = f.person_id_from
JOIN
Person p2 ON f.person_id_to = p2.id;
このように、リレーショナルDBでは関係表をJOINする複雑なSQL文になります。
上の例はまだ簡単ですが、例えば、テスラ車に乗ってる友達がいる人を検索するSQLはどうなるでしょうか?
Cypherではこのように簡潔に表記できます。
MATCH (p:Person)-[:FOLLOWS]->(b:Person)-[:HAS]->(c:Car)
WHERE c.brand = 'TESLA'
RETURN DISTINCT p
また、英語の文法の語順との相性の良さも特筆です。
英語で表記すれば、A person who follows a person who has a car where the brand is TESLA.
一方で、リレーショナルDBの場合はどうでしょうか?このようにJOINが複雑になることがわかります。
SELECT DISTINCT p.*
FROM Person p
JOIN FOLLOWS f ON p.id = f.person_id_from
JOIN Person b ON f.person_id_to = b.id
JOIN Cars c ON c.owner_id = b.id
WHERE c.brand = 'TESLA';
Python SDK
さて次は、プログラミングをしてみましょう。Neo4JではPython, JS, Java等のSDKが利用できます。
pip install neo4j
クラウド版Neo4Jに接続するための情報は、最初にダンロードしたファイルに定義されています。
NEO4J_URI=neo4j+s://8888888.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=uOg_6I...
NEO4J_DATABASE=neo4j
このファイルをdotenvからそのまま読み込みます。
from dotenv import load_dotenv
load_dotenv("neo4j.txt")
Neo4Jに接続します。
with GraphDatabase.driver(URI, auth=AUTH) as driver:
クエリーの実行は、session.execute_write(クエリー)を呼び出します。
with driver.session() as session:
session.execute_write(test_query)
test_query関数がコールバックで呼び出され、引数にトランザクションtxが渡されます。
tx.run()の引数に、Cypherステートメントを渡し実行します。
def test_query(tx):
result = tx.run("MERGE (t:Test {name1: 'Ping1'}) RETURN t.name AS name")
for record in result:
print(f"Test node created with name: {record['name']}")
data = record.data()
関数全体がトランザクション境界になっており、関数の終了とともに自動コミットされます。例外で抜ければロールバックされます。
全体のコードはこちらになります。
全体のコード
from neo4j import GraphDatabase
from dotenv import load_dotenv
import os
# Load environment variables
load_dotenv("neo4j.txt")
URI = os.getenv("NEO4J_URI")
AUTH = (os.getenv("NEO4J_USERNAME"), os.getenv("NEO4J_PASSWORD"))
# Establish connection and run test query
try:
with GraphDatabase.driver(URI, auth=AUTH) as driver:
driver.verify_connectivity()
print("Connection established successfully!")
# Create a test node and return it
def test_query(tx):
result = tx.run("MERGE (t:Test {name1: 'Ping1'}) RETURN t.name AS name")
for record in result:
print(f"Test node created with name: {record['name']}")
with driver.session() as session:
session.execute_write(test_query)
except Exception as e:
print(f"Connection failed: {e}")
実行すると、testノードが作成されます。

スキーマ
バスケット分析
バスケット分析(Market Basket Analysis)とは、顧客が一度の購買でどの商品を一緒に購入したかという履歴データから、よく一緒に買われる商品群を見つけ出す手法です。スーパーマーケットやECサイトなど、小売業を中心に広く活用されています。
例:奥さんのお使いで、赤ちゃんのオムツを買いに来たお父さんが、そのついでにビールも買う
→ オムツとビールが一緒に買われる傾向があるなら、陳列場所を近づけることでビールの売上増が期待できる
ここでは、イオンのようなスーパーの顧客の購買データを想定して解説していきたいと思います。
1枚のレシートをイメージしてください。レシートにニンジン、牛肉などの商品名が記載してあるイメージです。それぞれ、Order(受注)とItem(商品)としてエンティティ定義します。one-manyの関係になります。
購買データの準備
まずは仕込み作業のテスト・データを作成する必要があります。この手の作業は生成AIで一発で出来てしまいます。素晴らしい時代になりました。
購買データ
// Orders
CREATE (o1:Order {order_id: "201", date: "2025-07-01"})
CREATE (o2:Order {order_id: "202", date: "2025-07-02"})
CREATE (o3:Order {order_id: "203", date: "2025-07-03"})
CREATE (o4:Order {order_id: "204", date: "2025-07-04"})
CREATE (o5:Order {order_id: "205", date: "2025-07-05"})
CREATE (o6:Order {order_id: "206", date: "2025-07-06"})
CREATE (o7:Order {order_id: "207", date: "2025-07-07"})
// Items
CREATE (i1:Item {name: "Popcorn", price: 3.0})
CREATE (i2:Item {name: "Soda", price: 1.5})
CREATE (i3:Item {name: "Nachos", price: 4.0})
CREATE (i4:Item {name: "Coffee", price: 2.5})
CREATE (i5:Item {name: "Croissant", price: 2.0})
CREATE (i6:Item {name: "Avocado", price: 1.8})
CREATE (i7:Item {name: "Chocolate", price: 1.2})
CREATE (i8:Item {name: "Tofu", price: 2.2}) // outlier
// Popcorn + Soda appear together 4 times
CREATE (o1)-[:ORDERS]->(i1)
CREATE (o1)-[:ORDERS]->(i2)
CREATE (o2)-[:ORDERS]->(i1)
CREATE (o2)-[:ORDERS]->(i2)
CREATE (o3)-[:ORDERS]->(i1)
CREATE (o3)-[:ORDERS]->(i2)
CREATE (o3)-[:ORDERS]->(i3) // Nachos added
CREATE (o4)-[:ORDERS]->(i1)
CREATE (o4)-[:ORDERS]->(i2)
CREATE (o4)-[:ORDERS]->(i7) // Chocolate added
// Coffee + Croissant appear together 2 times
CREATE (o5)-[:ORDERS]->(i4)
CREATE (o5)-[:ORDERS]->(i5)
CREATE (o6)-[:ORDERS]->(i4)
CREATE (o6)-[:ORDERS]->(i5)
CREATE (o6)-[:ORDERS]->(i6) // Avocado added
// Tofu only appears once
CREATE (o7)-[:ORDERS]->(i8)
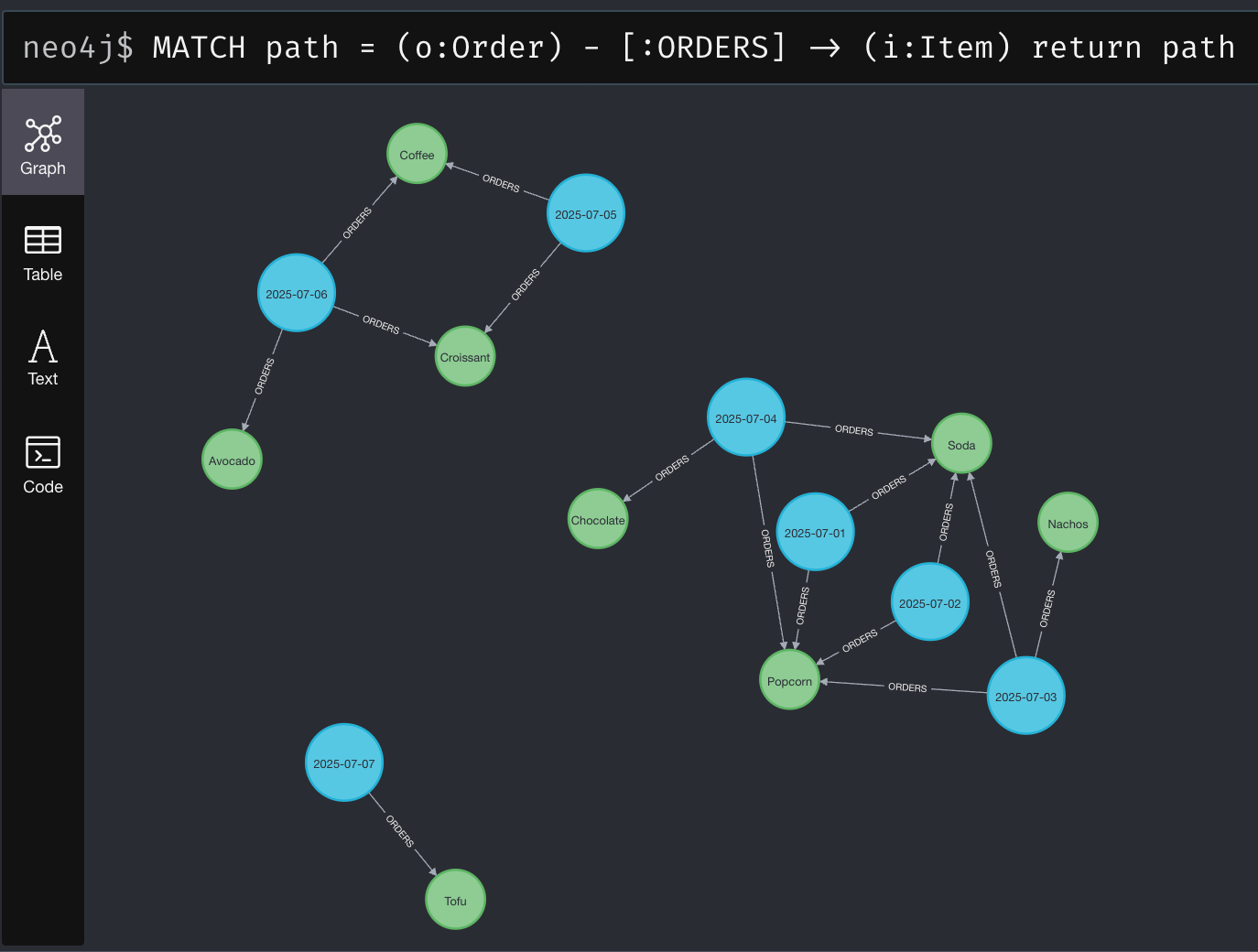
購買データ
青色がOrder、緑色がItemエンティティになります。
一緒に購入された商品ペア(共起頻度)をカウントするCypherは次のようになります。
MATCH (o:Order)-[:ORDERS]->(i1:Item), (o)-[:ORDERS]->(i2:Item)
WHERE i1.name < i2.name // Avoid self-pair and duplicates
RETURN i1.name AS item1, i2.name AS item2, COUNT(*) AS support
ORDER BY support DESC;

共起頻度
ポップコーンとソーダの組み合わせが一番多いことが分かりました。
ジャッカード係数 (Jaccard similarity)
先ほどの例では、単純にペアをカウントしただけ(共起頻度)ですので、当然ながらよく売れる商品のペアが多く出現してしまいます。例えば、ビールと卵はともに定番の人気商品ですので、共起頻度も多くなります。だからといって、ビールと卵が一緒に購入される確率は高いとは言えないでしょう。
そこで、ビールと卵のどちらか一方だけ購入された回数(和集合)で割り算し、正規化したものが、ジャッカード係数になります。
ジャッカード係数を計算するCypherは次のようになります。
// Step 1: Co-occurrence (intersection)
MATCH (i1:Item)<-[:ORDERS]-(o:Order)-[:ORDERS]->(i2:Item)
WHERE id(i1) < id(i2) // avoid self and duplicate pairs
WITH i1, i2, COUNT(DISTINCT o) AS intersection
// Step 2: Union: orders with i1 or i2
MATCH (i1)<-[:ORDERS]-(o1:Order)
MATCH (i2)<-[:ORDERS]-(o2:Order)
WITH i1, i2, intersection,
COLLECT(DISTINCT id(o1)) + COLLECT(DISTINCT id(o2)) AS all_orders
WITH i1, i2, intersection,
SIZE(apoc.coll.toSet(all_orders)) AS union
// Step 3: Compute Jaccard index
RETURN i1.name AS item1, i2.name AS item2,
intersection, union,
ROUND(1.0 * intersection / union, 3) AS jaccard
ORDER BY jaccard DESC
LIMIT 20;
APOCプラグインをインストールする必要があります。
APOCプラグイン
インストール対象のデータベースを選択し、右側のPluginsタブからAPOCをインストールします。

WITHの読み方が少しコツが要ります。やっていることは、p1とp2でGROUP BYし、集約計算しています。
こちらの箇所は
WITH p1, p2, intersection,
COLLECT(DISTINCT id(o1)) + COLLECT(DISTINCT id(o2)) AS all_orders
次のように読み替えてみてください。
select COLLECT(o1, o2) from o1, o2 group by p1, p2
COLLECTはリスト(スカラではなく)を返します。つまり、各商品ペアでGROUP BYし、それに紐づく全てのOrderのリストを返しています。DISTINCTで重複を除いています。これにより、和集合が取得できます。
実行してみましょう。このように、コーヒーとクロワッサンも一緒に購入されることが分かりました。

ジャッカード係数
少し長くなりましたので、次回に続きます。
次回は、ジャッカード係数をもとに、コラボレーション・フィルターを用いた、商品レコメンデーション・システムを作成したいと思います。
Discussion