WSL2 での TensorFlow + NVIDIA 環境構築
経緯
畳み込みニューラルによるスプラトゥーンのシーン分類モデルを、スプラトゥーン3向けに作り直すことにした。スプラトゥーン2の時代に作ったのでスプラトゥーン3では認識精度が良くない。
スプラトゥーン2時代の分類モデル作成の様子
当時は Google の AutoML を使っていたが、以下の理由からローカル環境で分類モデルを作成したい。
- AutoML の費用がかかる
- 対戦ステージがまだ増える可能性が高く何度か分類モデルを作り直したいが、そうなるとさらに費用がかかる
- 手元にゲーム用に購入した NVIDIA RTX 3080 搭載の Windows PC がある
TensorFlow + NVIDIA CUDA の環境構築は2017年から2019年にかけてよくやった内容だが、久しぶりに公式の説明通りに環境構築したらエラーになってしまったので手順を記録する。
ゴール
WSL2 環境で NVIDIA の GPU パワーをフル活用して手書き数字認識 MNISTデータベースの分類モデルを学習し推論を行う。
TensorFlow バージョンに対応する CUDA と cuDNN のバージョンが存在する
TensorFlow バージョンと CUDA、cuDNN バージョンの対応表
このスクラップ作成時点の TensorFlow の最新バージョンは 2.14.0
それに対応する CUDA のバージョンは 11.8。cuDNN のバージョンは 8.7。
CUDA Toolkit Archive から選んでインストールする。
CUDA 11.8 をインストールする
こちらの操作でインストールコマンドを得る。
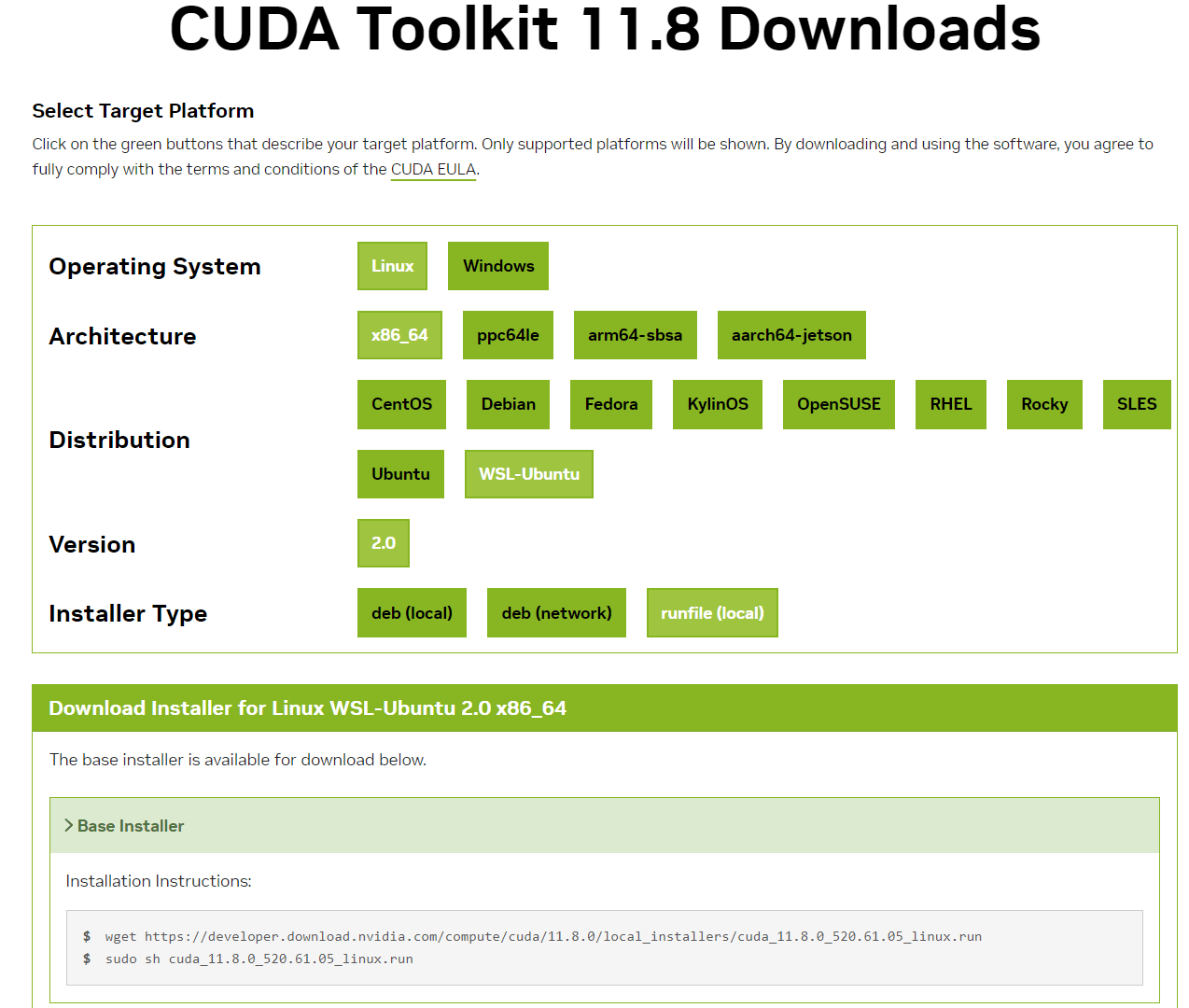
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
インストールが完了したら、指示に従い環境変数を設定する。
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-11.8/
Please make sure that
- PATH includes /usr/local/cuda-11.8/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-11.8/lib64, or, add /usr/local/cuda-11.8/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-11.8/bin
export PATH=/usr/local/cuda-11.8/bin:$PATH
# すでに /etc/ld.so.conf.d/cuda-11-8.conf があったため
sudo ldconfig
インストールの確認
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
cuDNN 8.7 をインストールする
インストールファイルをダウンロード
NVIDIA Developer のユーザアカウントを作り、ログインする必要がある。
- ログイン状態で https://developer.nvidia.com/cudnn にアクセスし
Download CuDNNボタンを押す。 -
I Agree To the Terms of the cuDNN Software License Agreementにチェックをつける -
Archived cuDNN Releasesをクリック -
Download cuDNN v8.7.0 (November 28th, 2022), for CUDA 11.xをクリック -
Local Installer for Linux x86_64 (Tar)をクリック
ライブラリの設置
tar -xvf cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz
展開したフォルダを /usr/local/cudnn-8.7 に設置
cp -r cudnn-linux-x86_64-8.7.0.84_cuda11-archive/ /usr/local/cudnn-8.7
/etc/ld.so.conf.d//cudnn-8.7.conf を作成
/usr/local/cudnn-8.7/lib/
ldconfig コマンド実行
sudo ldconfig
TensorFlow から GPU が使えるか確認する
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
略
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
手書き数字認識 MNISTデータベースの分類モデルを学習できるか確認する
初心者のための TensorFlow 2.0 入門 から Python コードをコピペして動かす
import tensorflow as tf
mnist = tf.keras.datasets.mnist
# データセットを読み込む
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 機械学習モデルを構築する
model = tf.keras.models.Sequential(
[
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10),
]
)
# モデルのコンパイル
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer="adam", loss=loss_fn, metrics=["accuracy"])
# モデルのトレーニング
model.fit(x_train, y_train, epochs=5)
# モデルの評価
model.evaluate(x_test, y_test, verbose=2)
実行結果
略
2023-10-03 23:05:15.443668: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1886] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 7365 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3080, pci bus id: 0000:01:00.0, compute capability: 8.6
略
1875/1875 [==============================] - 6s 2ms/step - loss: 0.2971 - accuracy: 0.9122
Epoch 2/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1455 - accuracy: 0.9568
Epoch 3/5
1875/1875 [==============================] - 4s 2ms/step - loss: 0.1107 - accuracy: 0.9663
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0910 - accuracy: 0.9724
Epoch 5/5
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0766 - accuracy: 0.9760
313/313 - 1s - loss: 0.0850 - accuracy: 0.9748 - 1s/epoch - 4ms/step
NVIDIA の GPU を使って分類モデルの作成と推論ができた。