Snowflake新AI関数: 日本語対応のAI_EXTRACTとAI_PARSE_DOCUMENTを使ってみた
背景
2025年8月20日のSnowflakeリリースノートで、待望の日本語対応が開始された新AI関数「AI_EXTRACT」と「AI_PARSE_DOCUMENT」についてご紹介します。本記事では、具体的なサンプルデータを用いて、これらの関数がいかに高精度で日本語の文字を抽出できるかを解説します。
TL;DR: 2つのAI関数の概要
-
AI_EXTRACT: 伝票や申込書のような定型フォーマットから、指定した項目(氏名、金額、日付など)を質問ベースで正確に抽出します。
-
AI_PARSE_DOCUMENT: 報告書や決算書のような非定型文書から、段落、表、見出しなどのレイアウトを保持したままテキストを解析し、構造化します。
前提
- Snowflakeアカウント(Snowsight または SnowSQL)
- サンプルでは簡便のため
ACCOUNTADMINを使用(本番は最小権限推奨) - 画像/文書は下記のサンプルデータを利用
-
[住民票データ]
-
[決算情報]
-
住民票画像をAI_EXTRACTで項目抽出
内部ステージに画像を置き、DIRECTORY(@files_stage) でファイルを列挙しつつ ai_extract に渡します。
USE ROLE ACCOUNTADMIN;
CREATE DATABASE IF NOT EXISTS ai_extract;
USE SCHEMA ai_extract.public;
CREATE OR REPLACE STAGE files_stage
ENCRYPTION = (TYPE = 'snowflake_sse')
DIRECTORY = ( ENABLE = TRUE);
PUT file://files/* @files_stage AUTO_COMPRESS=false OVERWRITE=true;
LS @files_stage;
SELECT
relative_path,
ai_extract(
file => TO_FILE('@files_stage', relative_path),
responseFormat => [
['氏名', '氏名はなんですか?'],
['個人番号', '個人番号はなんですか?'],
['世帯主', '世帯主はなんですか?'],
['住所', '住所はなんですか?'],
['本籍地', '本籍地はなんですか?'],
['生年月日', '生年月日はなんですか?'],
['性別', '性別はなんですか?'],
['住民となった日', '住民となった日はいつですか?'],
['備考', '備考欄に何かありますか?'],
['配偶者', '配偶者の名前はなんですか?'],
['発行日', '発行日はいつですか?'],
['発行者', '発行者は誰ですか?']
]
) AS result
FROM DIRECTORY (@files_stage);
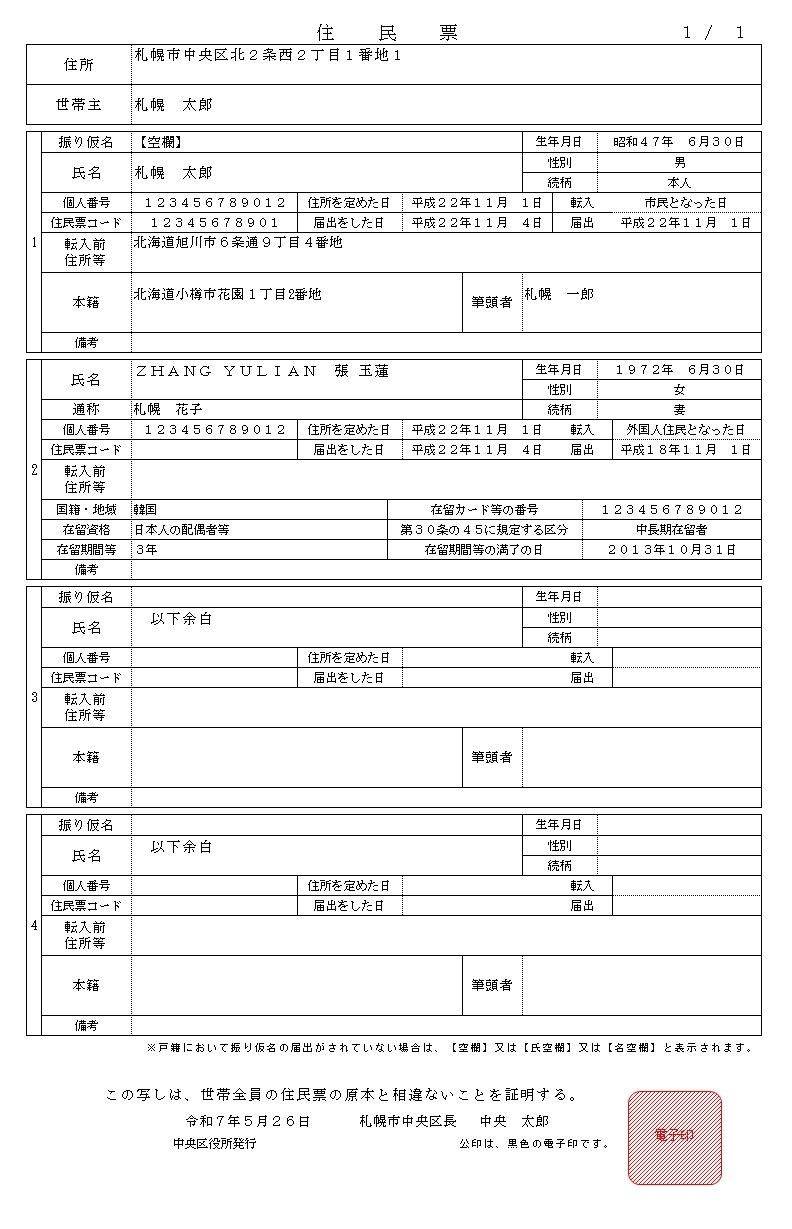
抽出結果(札幌市の住民票):
札幌市の住民票画像から、以下のように高精度で各項目が抽出されました。
{
"response": {
"世帯主": "札幌 太郎",
"住所": "札幌市中央区北2条西2丁目1番地1",
"住民となった日": "平成22年11月1日",
"個人番号": "123456789012",
"備考": "None",
"性別": "男",
"本籍地": "北海道小樽市花園1丁目2番地",
"氏名": "札幌太郎",
"生年月日": "昭和47年6月30日",
"発行日": "令和7年5月26日",
"発行者": "札幌市中央区役所",
"配偶者": "ZHANG YULIAN 張玉蓮"
}
}
下記が元の画像と比較して、複数の「名前」が存在するにもかかわらず、質問ベースで正確に識別できている点が大きな強みです。また、AI_EXTRACTはフォーマットが異なるドキュメントにも対応できるため、多様なデータソースの処理が容易になります。
文書をAI_PARSE_DOCUMENTでレイアウト保持解析
文書(PDF/画像)をPUTし、ALTER STAGE … REFRESH 後に AI_PARSE_DOCUMENT を実行します。
USE ROLE ACCOUNTADMIN;
CREATE DATABASE IF NOT EXISTS ai_parse_document;
USE SCHEMA ai_parse_document.public;
CREATE OR REPLACE STAGE files_stage
ENCRYPTION = (TYPE = 'snowflake_sse')
DIRECTORY = ( ENABLE = TRUE);
PUT file://earning_report/* @files_stage AUTO_COMPRESS=false OVERWRITE=true;
LS @files_stage;
ALTER STAGE files_stage REFRESH;
SELECT
relative_path,
AI_PARSE_DOCUMENT(
TO_FILE('@files_stage', relative_path),
{'mode': 'LAYOUT' , 'page_split': true}
) AS result
FROM DIRECTORY (@files_stage);
-
mode: 'LAYOUT': 段落・表・見出しなど文書構造を保持しやすい -
page_split: true: ページ単位で分割出力(ページ別要約・比較に便利)
抽出結果:
NTTグループの決算書1ページ目から、以下のように表形式のデータを含めてレイアウトを保持したまま抽出できました。
短信〔IFRS〕(連結) 2025年8月6日\n
\n
上場会社名 NTT株式会社 コード番号 9432 代表者 (役職名) 代表取締役社長 (氏名) 島田 明 問合せ先責任者 (役職名) 財務部門IR室長 (氏名) 島田 明 (TEL) 03 (6838) 5481
配当支払開始予定日 決算補足説明資料作成の有無:有 決算説明会開催の有無 :有 (機関投資家・アナリスト向け)\n
\n
(百万円未満四捨五入) 1. 2025年度第1四半期の連結業績(2025年4月1日~2025年6月30日) (1)連結経営成績(累計) (%表示は、対前年同四半期増減率) (2)連結財政状態\n
\n|
| | 営業収益 | | 営業利益 | | | 税引前四半期利益 | | 当社に帰属する 四半期利益 | |\n
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |\n
| | 百万円 | % | 百万円 | % | 百万円 | % | 百万円 | % | |\n
| 2025年度第1四半期 | 3,262,039 | 0.7 | 405,193 | △7.0 | 391,769 | △8.8 | 259,714 | △5.3 | |\n
| 2024年度第1四半期 | 3,240,023 | 4.1 | 435,817 | △8.2 | 429,392 | △25.7 | 274,136 | △27.0 | |\n
\n
(注)当社に帰属する四半期包括利益 2025年度第1四半期 308,159百万円 (△12.4%) 2024年度第1四半期 351,706百万円 (△41.2%)\n
\n
AI_PARSE_DOCUMENTは、特に表形式のデータが崩れやすいという課題を解決します。このレイアウト保持は、後続のRAG(Retrieval-Augmented Generation)や検索システムが情報を正確に抽出する基盤となり、全体的な精度向上に貢献します。

AI_EXTRACTのAI_PARSE_DOCUMENTと使い分け
類似機能を持つ両関数ですが、目的と入出力の観点から使い分けることが重要です。
- 目的・ユースケース・考え方
| 項目 | AI_EXTRACT | AI_PARSE_DOCUMENT |
|---|---|---|
| 目的 | 特定のフィールドを抽出する | 文書全体の構造を保持する |
| ユースケース | 請求書から金額や日付を抽出する | 技術論文や決算書を取り込み、RAGや検索の基盤を構築する |
| 考え方 | 抽出したい項目が明確なときに最適 | ドキュメントをまず「読める形にする」ときに最適 |
- 入出力とフォーマット
| 項目 | AI_EXTRACT | AI_PARSE_DOCUMENT |
|---|---|---|
| 入力 | 文字列 or ステージ上のファイル(PDF, DOC/DOCX, PPTX, 画像, HTML/TXT など) | ステージ上のファイル(PDF, PPTX, DOCX, 画像, HTML, TXT) |
| 指定方法 |
responseFormat に抽出スキーマ/質問を与える(オブジェクト/配列など複数形式) |
{'mode': 'LAYOUT' or 'OCR'} |
| 出力 | 抽出結果の JSON(キー=項目名、値=回答) |
JSON(pages[]内のcontentsフィールドにテキスト/OCRモードはプレーンテキスト) |
| 主目的 | 特定フィールドの値取り | 全文+構造の高忠実取り込み |
| 代表ユースケース | 伝票から金額・日付だけ抽出、メールから件名/差出人抽出 等 | 技術論文/決算書/スライドを構造保持で取り込み → RAG/検索基盤化 等 |
よくあるハマりどころ
-
PUT失敗: 実行環境からローカルパス到達性、日本語ファイル名/拡張子/大小文字を確認 -
DIRECTORY(@stage)が空:DIRECTORY = ENABLEとALTER STAGE … REFRESHを確認 - 抽出が不安定: 画像品質と質問文の見直し
よくある質問
Q)AI_EXTRACTはDocument AIの違いとは?
A)とは類似してますが、異なるサービスです。AI_EXTRACTはSQLでの操作を対応している一方で、Document AIはSnowsightUI/ファインチューニング/Table Extractionまでもサポートしております。
まとめ
- AI_EXTRACTは項目抽出に特化しており、定型文書の処理に最適です。
- AI_PARSE_DOCUMENTは文書構造の理解に強みがあり、非定型文書の全文解析に適しています。
どちらの関数も、内部ステージとDIRECTORY(@stage)を活用することで、大量のファイルをスケーラブルに一括処理できる点が大きなメリットです。今回の日本語対応により、これらの強力なAI機能が日本のビジネスシーンでさらに幅広く活用されることが期待されます。
Discussion