ブラウザ上でリアルタイムに音声を処理するためのノウハウ
WebRTCプラットフォームSkyWayのR&Dを担当しているtetterです。
最近、Wasmを活用してブラウザ上でリアルタイムに音声を処理するアプリケーションを試作した際、さまざまな引っかかりポイントがあることを確認しました。
本記事では音声の取得〜変換にターゲットを絞り、備忘録的に一連の処理の実装方法と注意すべき点を書いておきます。なお、音声処理自体の実装についてはやりたいことによって全く異なるので、本記事では対象外とします。
処理の流れ
概ね必要な処理の流れは以下のとおりです。
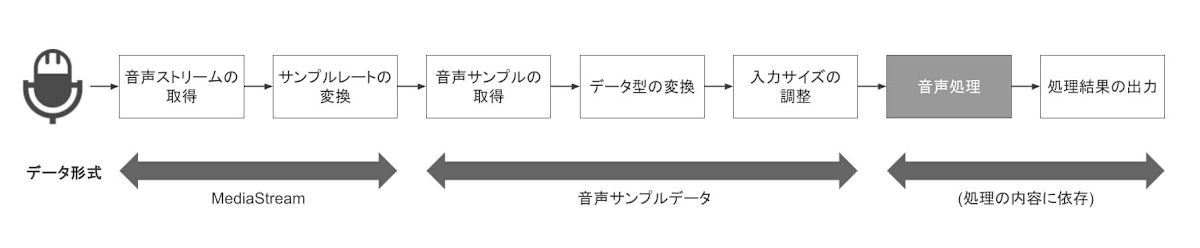
音声ストリームの取得
まず、リアルタイムに音声を処理するためには音声ストリームを取得する必要があります。
Media Capture and Streams APIのMediaDevices.getUserMedia()を使用することで、デバイスのマイクから簡単に音声ストリームを取得できます。
具体的には以下のようにaudio: trueを設定して取得します。
const constraints = {
audio: true,
};
// マイクデバイスからMediaStreamを取得
const mediaStream = await navigator.mediaDevices.getUserMedia(constraints);
サンプルレートの変換
音声処理の要件として、以下のような要素が指定されていることが想定されます。
- サンプルレート
- データ型
- 入力サイズ
つまり、先ほど取得した音声ストリームを処理の要件に合わせて変換していく必要があります。
サンプルレートの変換 (リサンプリング) 方法として、Web Audio APIのAudioContextの機能を活用するのが一番手っ取り早いと思います。
// 音声処理に必要なサンプルレート値を指定
const options = { sampleRate: 44100 };
const audioContext = new AudioContext(options);
// 先ほど取得したMediaStreamを元にsourceを作成
const source = this.audioContext.createMediaStreamSource(mediaStream);
なお、取得した音声のサンプルレートは使用するブラウザやそのとき接続しているマイクデバイスによって変動するため、特定の環境でリサンプリングが不要だったとしてもリサンプリング処理を入れておくことをおすすめします。
(筆者の環境では、同じバージョンのChromeでもMacのBuilt-inマイク使用時は48kHz、Polyのヘッドセット接続時は8kHzになることを確認しています)
音声サンプルの取得
ここまでは音声ストリームをMediaStream上で扱っていましたが、実際には音声処理の入力として用いるために個々の音声サンプルデータとして取得する必要があります。現在MediaStreamから音声サンプルデータを取得できる方法として以下の2つがあります。
-
AudioWorkletNodeを使用する (筆者推奨) -
MediaStreamTrackProcessorを使用する
後者はW3CのWebRTC WGで検討されているInsertable Streams for MediaStreamTrack APIの機能の1つで、MediaStreamのデータをStream APIで処理できるというものです。考案当初の仕様のIntroductionには音声処理に関する記載がありましたが、現在の仕様ではその記載が削除され、音声のユースケースをサポートすることにWGのコンセンサスが取られていないという注意事項が追加されています。
NOTE: There is no WG consensus on whether or not audio use cases should be supported.
以上から、WGのコンセンサスが得られるまではMediaStreamTrackProcessorは映像処理のユースケースにのみ活用し、音声処理の場合は前者を使用することをおすすめします。
前者のAudioWorkletNodeは、DeprecatedとなったScriptProcessorNodeの後継として登場した機能であり、Web Audio APIの処理パイプラインの中にユーザ定義の処理を挿入できるという機能です。詳しい解説はこちらの記事がわかりやすいです。
AudioWorkletNodeを定義して先ほど作成したsourceを接続することで、メインスレッドとは別スレッド上にて音声サンプルデータを取得できるようになります。
const worklet = audioContext.audioWorklet;
await worklet.addModule('./path/to/worklet.js').then(() => {
const processNode = new AudioWorkletNode(audioContext, 'processor');
// 生成したAudioWorkletNodeにMediaStreamを接続する
source.connect(processNode);
});
接続が完了すると、オーディオスレッド上でAudioWorkletProcessor.process()が等間隔で実行され、inputsから音声サンプルデータを取得できます。このとき、一度の実行で取得されるのは128サンプルとなります。
class MyWorkletProcessor extends AudioWorkletProcessor {
constructor() {
super();
}
process(inputs, outputs, parameters) {
// サイズ128の音声サンプルデータが取得できる
const inputSamples = inputs[0][0];
}
}
registerProcessor('processor', MyWorkletProcessor);
この後の処理はAudioWorkletProcessor.process()内に実装していきます。
データ型の変換
AudioWorkletNode上で取得される音声サンプルデータは値の範囲が[-1.0, 1.0]のFloat32Array形式になっています。音声処理側で型を合わせることができればそれに越したことはないですが、そうしない場合は音声処理の要件に合わせて音声サンプルデータを変換する必要があります。
もしも別の型に対して線形に対応させれば良い場合、例えばInt16なら以下のように変換します。
const inputSamplesS16 = Int16Array.from(inputSamples, (n) => {
const res = n * 32768;
// Int16の範囲内の [-32768, 32767] へclampする
res = Math.max(-32768, Math.min(32767, res));
// 四捨五入して返却する
return Math.round(res);
});
入力サイズの調整
AudioWorkletNode.processを一度実行することで取得されるのは128サンプルのため、音声処理に必要な入力サイズへと達するまでデータを蓄える必要があります。ここで留意すべきは、リアルタイムにデータを取得しているため、処理が間に合わずにデータを蓄えすぎてしまった場合に古いデータを捨てる機能が必要となります。
私のおすすめはRingBufferです。指定したバッファ領域以上のデータが蓄えられた場合、最も古いデータを最新のデータで上書きしてくれます。以下のように実装できます。
必要な入力サイズ分のデータが溜まったら、あとは任意の音声処理へと入力するだけです。
処理結果の出力
任意の音声処理が完了した後は結果を出力しましょう。
出力形式は音声処理の種別によって異なると思いますが、今回は音声を出力する場合と音声以外を出力する場合の2種類に分けて説明します。
音声として出力
音声を出力したい場合、これまでの流れを逆順で行っていきます。具体的には以下のとおりです。
- データ型を
Float32Arrayへ変換する -
AudioWorkletNode.processのoutputsへ128サンプルずつ渡す - (必要であれば) サンプルレートを元に戻す
ここで留意すべきなのは、データ変換の際に必ず[-1.0, 1.0]の範囲へclampすることです。これを忘れてしまうとクリッピングが発生して非常に耳障りな音声になる可能性があります。
const outputSamplesF32 = Float16Array.from(outputSamples, (n) => {
const res = n / 32768;
// [-1.0, 1.0] の範囲内へclampする
return Math.max(-1.0, Math.min(1.0, res));
});
変換後の音声はAudioWorkletNode.processのoutputsへ渡す際に128サンプルずつにする必要がありますので、ここでも入力時と同様にRingBufferを設けておくと良いでしょう。
outputsへ渡した音声はメインスレッドでMediaStreamとして扱うことができるため、そのまま元のサンプルレートへ戻したり、HTMLAudioElementやHTMLVideoElementから再生したり、WebRTC APIで送信したりできます。
class MyWorkletProcessor extends AudioWorkletProcessor {
...
process(inputs, outputs, parameters) {
...
const channelNum = outputs[0].length;
// 出力チャンネル毎に出力データをセット
for (let i = 0; i < channelNum; i++) {
outputs[0][i].set(outputSamplesF32, 0);
}
}
}
...
...
const destination = audioContext.createMediaStreamDestination();
// AudioWorkletNodeの出力先へ接続
processNode.connect(destination);
// 処理結果はMediaStreamとして取得される
const processedStream = destination.stream;
音声以外として出力
音声以外の場合はoutputsからは渡せないので、postMessageを使用して渡します。こちらは音声とは違い出力サイズの調整は不要です。
// 音声処理結果のoutputDataをメインスレッドへ送信
this.port.postMessage(outputData);
// postMessageを受け取った際の処理を定義
processNode.port.onmessage = (e) => {
// メインスレッド側でoutputDataを取得
const outputData = e.data;
};
Discussion