KoboldCppとRunPodでHuggingFaceのモデルをホストする
免責事項:この記事は、モデルをホストしたり、ファインチューニングしたりする人ではなく、一般的な言語モデルユーザーを対象としています。AIやモデルに関する専門的な記事ではありません。また、この記事は個人的な経験に基づいており、主観的な意見を含んでいます。
免責事項:この記事はアカツキゲームスのアドベントカレンダー2024の12日目の記事です。
ChatGPTの人気のおかげで、GPT-4oは現在最も広く使われているAIモデルの1つです。AIの界隈には、AnthropicのClaudeモデルシリーズ、GoogleのGeminiモデルシリーズ、MetaのLlamaモデルシリーズ、CohereのCommand Rモデルシリーズ、MistralのMistralモデルシリーズ、xAIのGrokモデルシリーズ、そして最近ではAmazonのNovaモデルシリーズなど、様々なモデルも存在します。
問題
しかし、これらの商用の大規模言語モデルの他にも、HuggingFaceには多くのオープンソースおよびオープンウェイトモデルがあります。その中には十分なパラメータ数を持ち、より小規模ながらもキュレーションされたデータセットでファインチューニングされたため、特定の分野(ロールプレイングや創作など)で特に優れているものもあります。
問題は、HuggingFaceのInference APIを通じて一部のモデルとチャットすることは可能ですが、モデルがInference APIにデプロイされるためには十分なアクティビティが必要です。つまり、あまり人気のない、またはニッチなモデルとチャットしたり使用したりするには、次のいずれかを行う必要があります。
- 自分のGPUを使用してローカルマシンでモデルをホストする
- Arli AI、Featherless、Infermaticなどのホスティングサービスの料金プランに加入
- Novita AIやGroqなどのホスト、またはOpenRouterなどのプロキシサービスを通じてトークンごとに支払う
- GPUクラウドを使用してGPU時間をレンタルし、モデルをホストする
しかし、これらの方法にはそれぞれ制限があります。
ローカルでホストする
ローカルホスティングは、自分のコンピューターやサーバー上で直接モデルを動作させる方式です。この方法では、モデルのファイルを自分のマシンにダウンロードし、必要なソフトウェアをインストールして実行します。一度セットアップが完了すれば、インターネット接続なしでもモデルを使用でき、レイテンシーも最小限に抑えられるというメリットがあります。さらに、モデルの設定やパラメータを完全にコントロールできるため、自分の用途に合わせて細かく調整することも可能です。
しかし、この方式の最大の制限は必要なハードウェア要件です。比較的まともなGPUであっても、量子化された12Bモデルが限界で、それ以上の大きさのモデルを実行するには、より高性能なGPUや複数のGPUが必要になります。また、モデルのセットアップやメンテナンス、更新などの技術的な管理も自分で行う必要があります。
このため、ローカルホスティングは、必要なハードウェアを既に所有しているユーザーにとって理想的な選択肢となります。また、特定の小規模モデルを頻繁に使用する場合や、技術的な管理を自分で行える知識と時間がある場合には、特に効果を発揮するでしょう。
サブスクリプション型
サブスクリプション型は、月額固定料金で特定のモデルを無制限に利用できる方式です。この方法では、サービスプロバイダーがモデルのホスティングとメンテナンスを担当するため、技術的な管理の手間がかかりません。また、定額制であるため、使用量を気にすることなく利用できます。多くの場合、複数のモデルにアクセスできるプランも用意されており、用途に応じて異なるモデルを使い分けることができます。
ただし、サービスプロバイダーはコストを抑えるため、モデルが本来対応可能なコンテキストウィンドウよりも小さく設定することが一般的です。また、カスタマイズ可能な設定項目が限られており、モデルのパラメータを細かく調整することは難しい場合があります。
なので、サブスクリプション型は、定期的に多くのリクエストを送信する必要があるユーザーや、技術的な管理の手間を最小限に抑えたいユーザーにとって最適な選択となるでしょう。特に、長いコンテキストウィンドウが不要な一般的な用途では、その利便性を最大限に活かすことができます。
トークンごとに支払う
トークンごとの支払い方式は、実際の使用量に応じて料金が発生する従量制のモデル利用方法です。OpenRouterのようなプロキシサービスを利用することで、複数のプロバイダーが提供する様々なモデルに単一のインターフェースからアクセスできます。また、使用していない時間帯の固定費用が発生しないため、使用頻度が低い場合はコストを抑えることができます。
ですが、この方式では使用量が増えるほど費用も比例して増加します。特にOpenAI o1-Preview(2024/12の時点)のような高性能なモデルを頻繁に使用する場合、コストが予想以上に高額になる可能性があります。また、プロキシサービスはプロバイダーがホストしているモデルにのみアクセスを提供するため、需要の低いニッチなモデルや、ライセンスの制限があるモデルは利用できない場合があります。
その理由で、トークンごとの支払い方式は、使用頻度が不定期で変動が大きい場合や、複数のプロバイダーのモデルを使い分けたい場合、また、コストを厳密に使用量に紐付けて管理したい場合に適しています。
クラウドでホストする(GPUクラウド)
クラウドホスティングは、GPUクラウドサービスを利用して必要な時だけGPUリソースをレンタルする方式です。この方法では、強力なGPUを時間単位でレンタルできるため、長期的な契約やハードウェアへの投資なしに、任意のモデルを柔軟に使用できます。また、必要に応じてリソースを拡張したり縮小したりすることができ、使用していない時間帯のコストも発生しません。
当然、この方式では時間単位での課金となるため、長時間の継続的な使用では他の方式と比べてコストが高くなる可能性があります。また、クラウド環境のセットアップやモデルの導入、設定などの技術的な知識が必要です。
したがって、もし:
- 任意のサイズのモデルをホストするための自分のGPUがない
- より長いコンテキストウィンドウが必要
- 使いたいモデルがどのプロバイダーでもホストされていない、またはライセンスの問題で商用ホストができない
- トークンごとの支払いはしたくない
のなら、GPUクラウドを通じてGPU時間をレンタルし、必要な時に起動し、不要な時にシャットダウンする方が単純だと考えています。
RunPodでクラウド上にモデルをホストする
RunPodは、オンデマンドでGPU時間をレンタルできる人気のサービスです。RunPodより良いオプションもあるかもしれませんし、この記事に言及するプラン以外に他のプランもありますが、それらはこの記事の範囲外です。この記事では、モデルの選択からLibreChatを使って自分のポッドにリクエストを送信するまで、クラウドでモデルをホストする方法についてを共有しようと思います。
モデルの選択
HuggingFaceには膨大な数のモデルが利用可能です。そのため、最初のステップは、ホストするモデルを選ぶことです。これにより、必要なVRAMとディスク容量も決まります。
モデルが大きいほどいいとは限りませんが、一般的にモデルが大きいほど、より賢くなります。個人的には、70Bは知性とコストのバランスが取れたちょうどいい大きさだと考えています。
最近Chronos-Platinum-72Bというモデルを見つけ、試してみたいと思っていたので、この記事ではこのモデルを例として取り上げます。
HuggingFaceのドキュメントによると、GGUFはモデルの高速なロードと保存に最適化されたバイナリフォーマットで、推論目的に非常に効率的であるため、このモデルのGGUFバージョンを選びます。
Chronos-Platinum-72BのGGUFバージョンページを見ると、以下の量子化が確認できます。
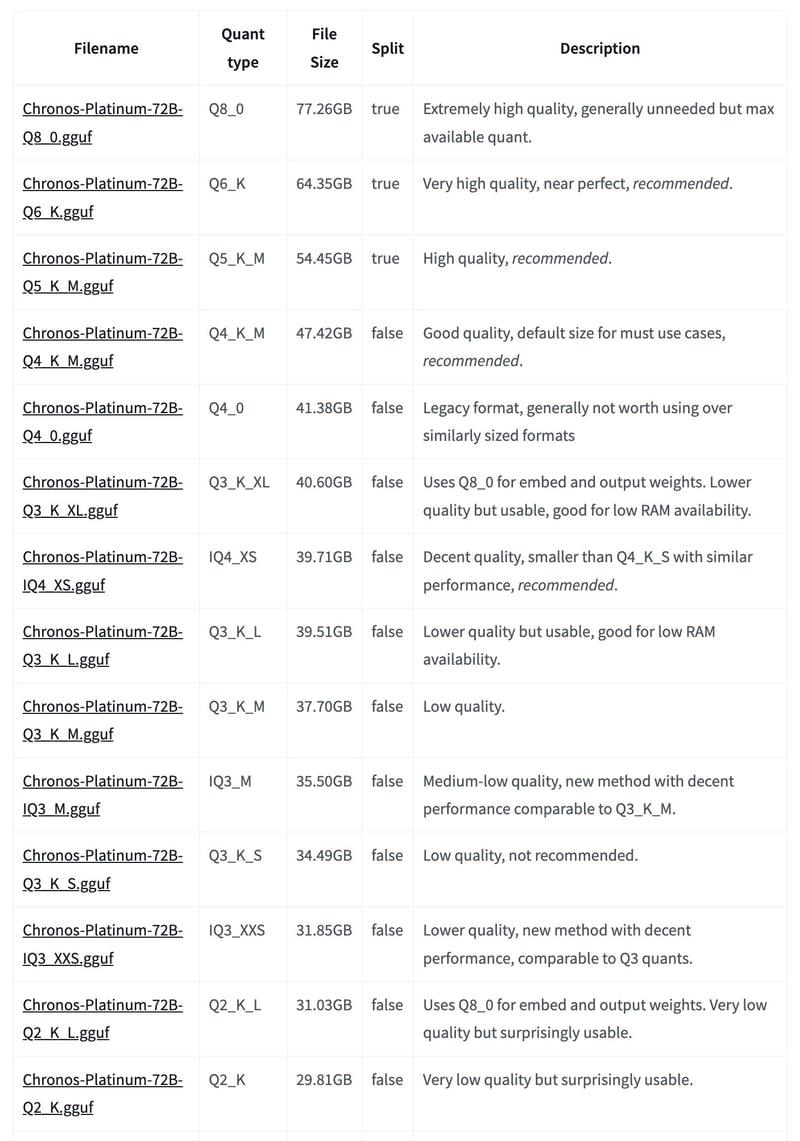
量子化とは何でしょうか、その仕組みについての詳細はこの記事では説明しませんが、一般的に、品質が大きく低下するため、低すぎる量子化は望ましくありません。 この例では、Q6_Kを選択します。
同じページのBartowskiさんのノートによると(翻訳):
どのファイルを選択すればよいですか?
様々なパフォーマンスを示すチャートを含む素晴らしい解説がArtefact2によってここで提供されています。
まず、どの程度の大きさのモデルを実行できるかを把握する必要があります。これを知るには、どれだけのRAMやVRAMが利用可能かを確認する必要があります。
モデルを可能な限り高速に実行したい場合は、GPUのVRAMにモデル全体を収める必要があります。GPUの総VRAMより1〜2GB小さいファイルサイズの量子化を目指してください。
絶対的な最高品質が必要な場合は、システムRAMとGPUのVRAMを合わせた総容量より1〜2GB小さいファイルサイズの量子化を選択してください。
次に、「I-quant」または「K-quant」のどちらを使用するかを決める必要があります。
あまり考えたくない場合は、K-quantのいずれかを選択してください。これらはQ5_K_Mのような「QX_K_X」という形式です。
表からQ6_K量子化のサイズは64.35GBであることがわかります。モデル全体をGPUのVRAMに収めたい場合、ポッドのVRAMは64.35GBより大きくなければなりません。また、コンテキストサイズが大きいほど、より多くのメモリも必要になります。HuggingFaceのドキュメントによると:
| モデルサイズ | 1kトークン | 16kトークン | 128kトークン |
|---|---|---|---|
| 8B | 0.125 GB | 1.95 GB | 15.62 GB |
| 70B | 0.313 GB | 4.88 GB | 39.06 GB |
| 405B | 0.984 GB | 15.38 GB | 123.05 GB |
つまり、128Kコンテキストでこのモデルをホストするには:
必要なVRAM合計 = モデルサイズ(64.35GB)+ コンテキストウィンドウのメモリ要件(128kトークンで39.06GB)= 103.41GB
まとめると、ポッドのハードウェア要件は次のようになります。
- ディスク容量: 64.35GB
- VRAM: 103.41GB
LLM-Model-VRAM-Calculatorを使用して計算することもできます。

これで要件がわかったので、これからポッドをデプロイします。
RunPodでのKoboldCppテンプレートを使用する
KoboldCppは、GGMLおよびGGUFモデル用の人気のあるテキスト生成ソフトウェアです。モデルを提供する際にOpenAI互換のAPIエンドポイントもついているため、LibreChatやOpenAI互換エンドポイントに接続できる他のソフトウェアを使うときかなり便利です。
RunPodには既に公式のKoboldCppテンプレートが用意されています。
-
RunPodにアクセスして登録します。
-
左ペインの「Pods」をクリックし、「+Deploy」をクリックします。

選択可能なGPUの種類はたくさんあります。少なくとも110.58GBのVRAMが必要なため、3x A40が適切だと言えるんでしょう。 -
A40を選択します。
-
下にスクロールし、GPU Countバーを3までドラッグします。

-
テンプレートをまだ選択していない場合は、「Change Template」ボタンをクリックし、「KoboldCpp - Official Template - Text and Image」を検索して選びましょう。

ここで重要なのは、公式のKoboldCppテンプレートを選択した後、「Edit Template」ボタンをクリックし、選択したモデルをホストするためにパラメータを変更する必要があることです。 -
「Edit Template」ボタンをクリックします。
-
「Pod Template Overrides」パネルで、以下のパラメータを変更する必要があります。

- Container Disk: 約64.35GBしか必要ないため、100 GBにします。
- KCPP_MODEL: すべてを次のように置き換えます。
https://huggingface.co/bartowski/Chronos-Platinum-72B-GGUF/resolve/main/Chronos-Platinum-72B-Q6_K/Chronos-Platinum-72B-Q6_K-00001-of-00002.gguf,https://huggingface.co/bartowski/Chronos-Platinum-72B-GGUF/resolve/main/Chronos-Platinum-72B-Q6_K/Chronos-Platinum-72B-Q6_K-00002-of-00002.ggufこのモデルのQ6_K量子化は2つの分割ファイルがあるため、リンクをコンマで区切ってすべての分割ファイルをKoboldCppに渡す必要があります。
GGUFファイルのリンクは、ファイル名の横にある小さなアイコンを右クリックしてアドレスをコピーすることで取得できます。

- KCPP_ARGS: すべてを以下のように置き換えます:
--multiplayer --usecublas mmq --gpulayers 999 --contextsize 128000 --multiuser 20 --flashattention --ignoremissing --chatcompletionsadapter ChatML.json --hordemodelname Chronos-Platinum-72BKoboldCppのドキュメントには、これらのパラメーターの機能が記載されているため、ここでは重要なパラメータのみを説明します。
- --contextsize 128000: コンテキストサイズを128000トークンに設定します。
- --chatcompletionsadapter ChatML.json: 多くのモデルは、モデルと共に使用する推奨のチャットテンプレートを指定しています。Chronos-Platinum-72Bのモデルカードによると、このモデルはChatMLテンプレートを使用しています。公式にバンドルされているチャットテンプレートファイルはこちらで一覧できます。
-
--hordemodelname Chronos-Platinum-72B: 多くのモデルにはカスタム名が付いていないようで、デフォルトでは、KoboldCppによって提供されるモデルはすべて
koboldcpp/modelという名前になります。こういう名前はあまり意味がないし、識別も難しいです。なので、このパラメータを通じてモデル名を適切に設定すれば、APIにアクセスして利用可能なモデルを一覧表示する際に、モデルは適切な名前で表示されます。
-
「Set Overrides」をクリックしてオーバーライドを保存します。
これでポッドのデプロイ準備が整いました。「Deploy On-Demand」をクリックしてポッドをデプロイしましょう。
ポッドのステータス確認
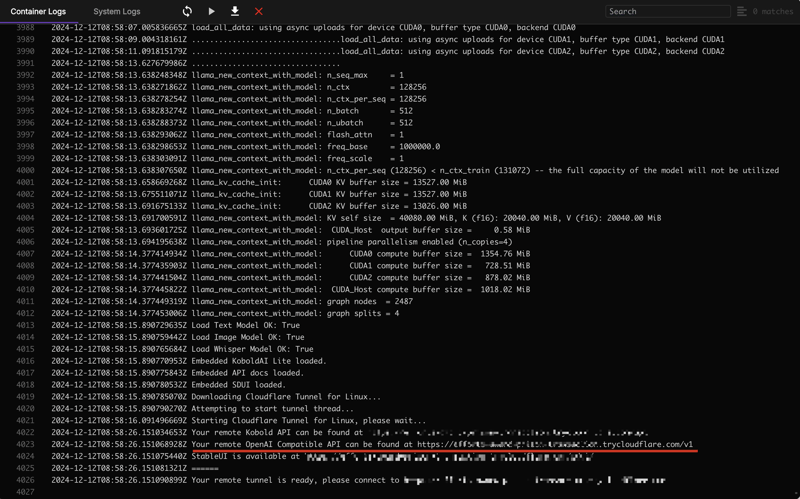
RunPodはポッドのデプロイを開始します。「Pods」ページで、新しく作成されたポッドの「Logs」ボタンをクリックすると、モデルの準備ができているかどうかを確認できます。

ログにこの行が表示されたら、モデルとOpenAI互換エンドポイントの準備が完了しました。このエンドポイント(/v1で終わる)をコピーして、後で使用します。
次に、モデルにアクセスするためのRunPod APIキーを作成します。
RunPod APIキーの作成
RunPod APIキーの作成は簡単です。RunPodコンソールの「Settings」ページに移動し、「API Keys」パネルを展開します。「+ Create API Key」をクリックしてAPIキーを作成します。モデルにアクセスするには、Read Only APIキーで十分です。
APIキーを作成したら、キーをコピーしてどこかに貼り付けて、後で使用できるようにします。
LibreChatでRunPodモデルとチャットする
ポッドが起動され、モデルも使用可能になったので、LibreChatをローカルにセットアップしてモデルにアクセスします。
-
LibreChatリポジトリをクローンします。
-
docker-compose.override.yml.exampleをコピーし、同じフォルダに置き、ファイルの名前をdocker-compose.override.ymlに変更します。 -
# USE LIBRECHAT CONFIG FILEの下の部分のコメントを外して、カスタム設定ファイルで設定をオーバーライドできるようにします。 -
同じ部分に
environmentセクションを追加し、簡単にアクセスできるようにRunPod APIキーをここに配置します。重要: セキュリティ上の理由で、以下の場合は絶対設定ファイルにAPIキーを直接保存しないでください。- 他のユーザーがアクセスできる公開環境にLibreChatをホストする場合
- LibreChatの設定を共有または公開する場合
- GitHubなどのバージョン管理システムに設定をプッシュする場合
代わりに、本番環境でのデプロイでは、以下のやり方がおすすめです。
- ユーザーにインターフェースを通じて自分のAPIキーを提供させる
- セキュアな環境変数またはシークレット管理システムを使う
- 認証情報管理のセキュリティベストプラクティスに従う
この記事の目的は自分自身の使用のためにモデルをホストすることですので、RunPodのAPIキーをローカルの
docker-compose.override.ymlに保存するだけで十分です。 -
これで、ファイルはスクリーンショットのようになります。

注意: 埋め込みAPIキーを使用したこの設定は、システムの唯一のユーザーである個人のローカル開発でのみ使用してください。 -
.env.exampleをコピーして同じフォルダに配置し、名前を.envに変更します。 -
librechat.example.yamlをコピーして同じフォルダに配置し、名前をlibrechat.yamlに変更します。 -
custom部分まで下にスクロールし、PortKey設定(またはカスタムエンドポイント部分の最後にあるもの)の下に、以下の設定を追加します。- name: "Chronos-Platinum-72B" apiKey: '${RUNPOD_API_KEY}' baseURL: 'https://<あなたのRunPodエンドポイント>/v1' models: default: ['koboldcpp/Chronos-Platinum-72B'] fetch: true titleConvo: true titleModel: 'current_model' modelDisplayLabel: 'Chronos-Platinum-72B'これらのオプションは:
- name: LibreChatのドロップダウンリストに表示されるプロバイダー名
- apiKey: 前の手順で作成したRunPod APIキー
-
baseURL: 前の手順でポッドのログを表示してコピーしたOpenAI互換のベースURL。このリンクは
/v1で終わる必要があります。 -
models:
- default: デフォルトで使用するモデル
-
fetch: 利用可能なすべてのモデルをフェッチして、ドロップダウンメニューに表示するかどうか。通常このオプションは、ポッドに一つのモデルしかない場合でも
trueに設定します。
- titleConvo: Google AI Studio、ChatGPT、Claudeのように、チャットの内容を要約して会話のタイトルを変換するかどうか。
- titleModel: 会話にタイトルを付けるために会話を要約する際に使用するモデル。
- modelDisplayLabel: 会話内で、ユーザーに表示するモデルのラベル/名前(エンドポイントのアイコンの横)。
RunPodエンドポイントを設定したら、LibreChatを起動します。LibreChatフォルダでdocker compose up -dを実行し、エラーがなければ、http://localhost:3080/にアクセスすると、LibreChatのログインページが表示されます。アカウントを作成してLibreChatにログインしましょう。

注意: LibreChatはChatGPTの馴染みのあるインターフェースを複製することを目指しているため、LibreChatにログインするには登録が必要ですが、ローカルで実行している限り、アカウントとメールアドレスはローカルのMongoDB(およびローカルディスク)にのみ保存されます。
アカウントを作成したら、LibreChatにログインしてLibreChatのインターフェースを確認できます。

左上のドロップダウンメニューから、新しく追加したエンドポイントが既に利用可能なことが確認できます。

エンドポイントとモデルを選択し、右側のペインでモデルにシステムプロンプトを与え、RunPodでホストされているモデルに挨拶するメッセージを送りましょう!

LibreChatのシャットダウン
docker compose downを実行するか、Rancher Desktop、Docker Desktop、OrbStackなどのGUIを使用してコンテナをシャットダウンします。
ポッドのシャットダウン
RunPodの「Pods」ページでゴミ箱アイコンをクリックし、ポッドを終了し、それ以上のコストが発生しないようにします。

おめでとうございます!これで、使用したいHuggingFaceモデルと(モデル自体がサポートしている限り)サポートしたいコンテキストウィンドウが選べるようになりました。調整や詳細の設定の可能な部分がまだたくさんあり、様々な面白いモデルもありますので、興味があるならぜひ他の設定をいじったり、他のモデルを試してみてください。この記事は、自分用でモデルをホストすることに興味のある方々の出発点となることを願っています。ハッピープロンプティング!
Discussion