DuckDB + Claude Desktop + MCP で X(Twitter)のアーカイブデータを閲覧する
DuckDB のインストール
X(Twitter)アーカイブのデータからポストの JSON を抜き出してファイルを作成する
データ変換用のスクリプト(Claude 作)
const fs = require('fs')
const path = require('path')
/**
* TwitterアーカイブのJSファイルをJSONに変換する関数
* @param {string} inputFile - 入力ファイル(.jsファイル)のパス
* @param {string} outputFile - 出力JSONファイルのパス
*/
function convertTwitterArchiveToJson(inputFile, outputFile) {
try {
// ファイルを読み込む
let fileContent = fs.readFileSync(inputFile, 'utf8')
// window.YTD.tweet.part0 = [...] の形式から実際のJSONデータを抽出
// 正規表現を使用して [...] の部分を取得
const match = fileContent.match(
/^window\.YTD\.\w+\.part\d+\s*=\s*(\[[\s\S]*\])/
)
if (!match || !match[1]) {
throw new Error('Twitter archiveデータの形式が想定と異なります')
}
// JSONデータを取得
const jsonData = match[1]
// JSON形式に変換してファイルに書き込む
fs.writeFileSync(outputFile, jsonData, 'utf8')
console.log(`変換完了: ${outputFile} にJSONデータを書き込みました`)
return true
} catch (error) {
console.error('エラーが発生しました:', error.message)
return false
}
}
// コマンドライン引数からファイルパスを取得
const args = process.argv.slice(2)
if (args.length < 2) {
console.log(
'使用方法: node convert-tweet-data.js <入力ファイル> <出力ファイル>'
)
console.log(
'例: node convert-tweet-data.js ./data/tweets.js ./data/tweets.json'
)
process.exit(1)
}
const inputFile = args[0]
const outputFile = args[1]
// 変換実行
convertTwitterArchiveToJson(inputFile, outputFile)
スクリプトを実行する
node convert-tweet-data.js ./path/to/tweets.js ./path/to/tweets.json
DuckDB で JSON ファイルを読み込む
DuckDB Local UI を使ってみる

MotherDuck MCP Server(mcp-server-motherduck)を Claude Desktop で使ってみる
GitHub - motherduckdb/mcp-server-motherduck: MCP server for DuckDB and MotherDuck
uv をインストールする
GitHub - astral-sh/uv: An extremely fast Python package and project manager, written in Rust.
brew install uv
または、
pip install uv
mcp-server-motherduck をインストールする
uv pip install mcp-server-motherduck
MotherDuck のトークンを取得する
(ローカルファイルの場合いらなかった)
参考)
MotherDuck(DuckDB)のMCPサーバーを導入して分析させてみた with Claude Code | DevelopersIO
Claude Desktop の設定ファイルを編集する(Claude for Mac の場合)
- 設定 > 開発者 > 構成を編集
- Finder で ~/Library/Application Support/Claude/claude_desktop_config.json が表示される
- 編集する(↓)
{
"mcpServers": {
"local-duckdb": {
"command": "uvx",
"args": [
"mcp-server-duckdb",
"--db-path",
"/Users/ユーザー名/path/to/database.db"
]
}
}
}
Claude Desktop を再起動する
Claude Desktop でデータを閲覧してみる
途中でエラー出てた

Database error: Invalid Input Error: Required module 'pytz' failed to import, due to the following Python exception:
ModuleNotFoundError: No module named 'pytz'
CREATE VIEW tweets AS
SELECT
tweet ->> 'id_str' AS id_str,
STRPTIME(tweet ->> 'created_at', '%a %b %d %H:%M:%S %z %Y') AS created_at,
tweet ->> 'full_text' AS full_text,
CAST(tweet ->> 'retweet_count' AS INTEGER) AS retweet_count,
CAST(tweet ->> 'favorite_count' AS INTEGER) AS favorite_count,
tweet ->> 'lang' AS lang,
json_extract_string(tweet, '$.entities.user_mentions[0].screen_name') AS mention_screen_name
FROM raw_tweets;
の STRPTIME(tweet ->> 'created_at', '%a %b %d %H:%M:%S %z %Y') AS created_at, のところが原因らしい
DuckDB の Local UI で実行したときは問題なかったけど、ローカル環境には pytz がインストールされてなかった模様
pytz をインストールする
uv pip install pytz
解消された

文字列で検索

件数を数える

キーワードを適当に挙げて検索してくれる

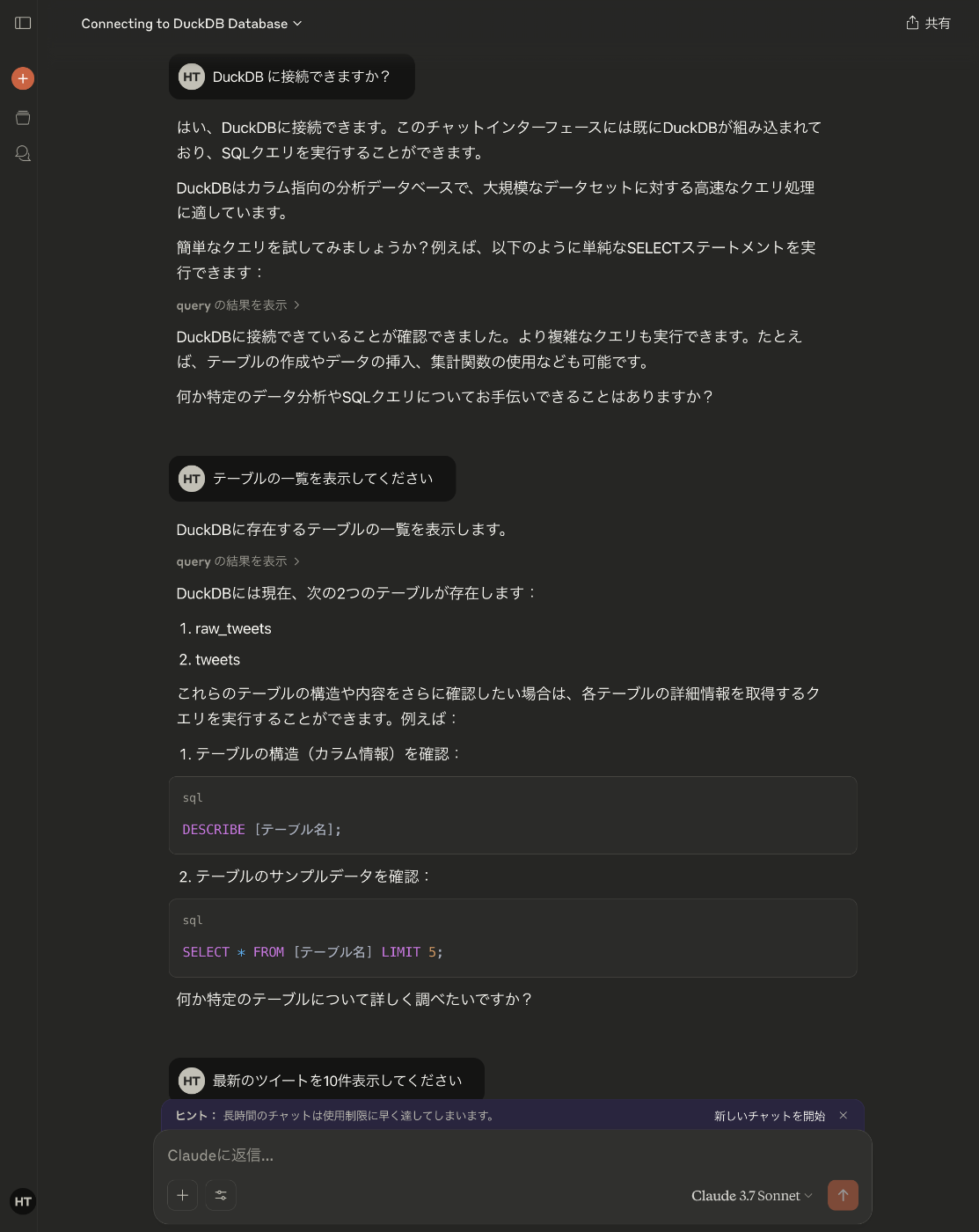
集計を頼んだら傾向についてコメントもしてくれた
表

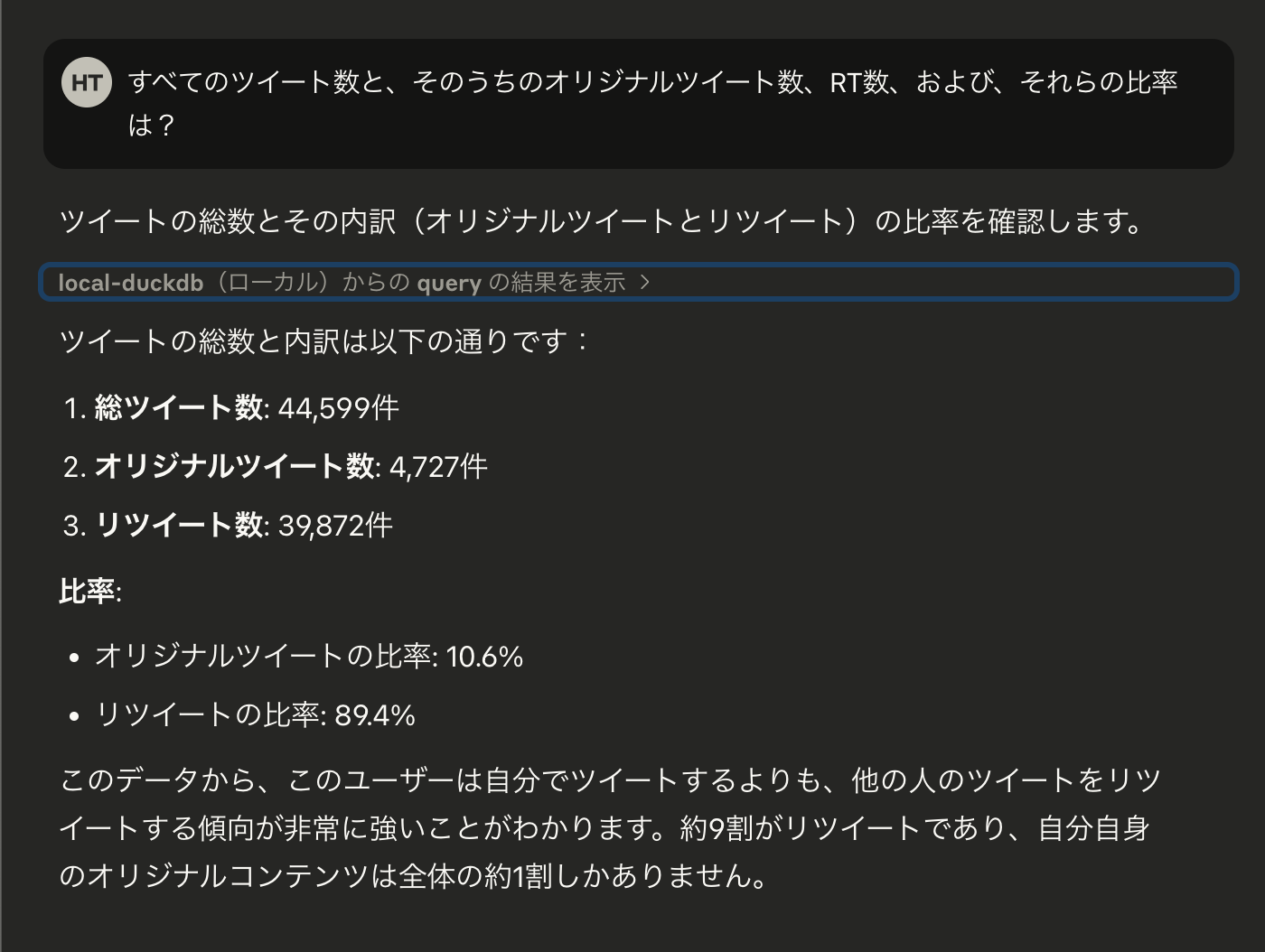
React でグラフ化もしてくれる
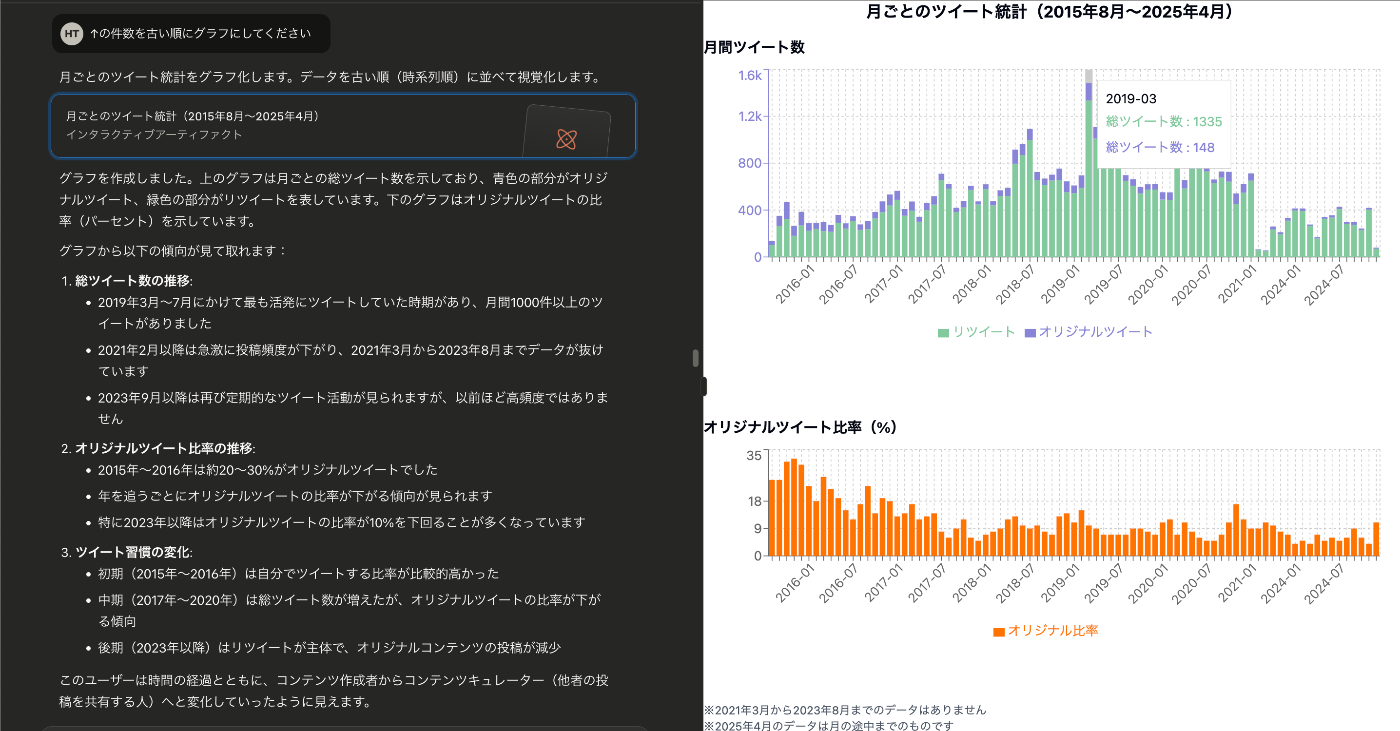
雑な依頼もいい感じにまとめてくれる
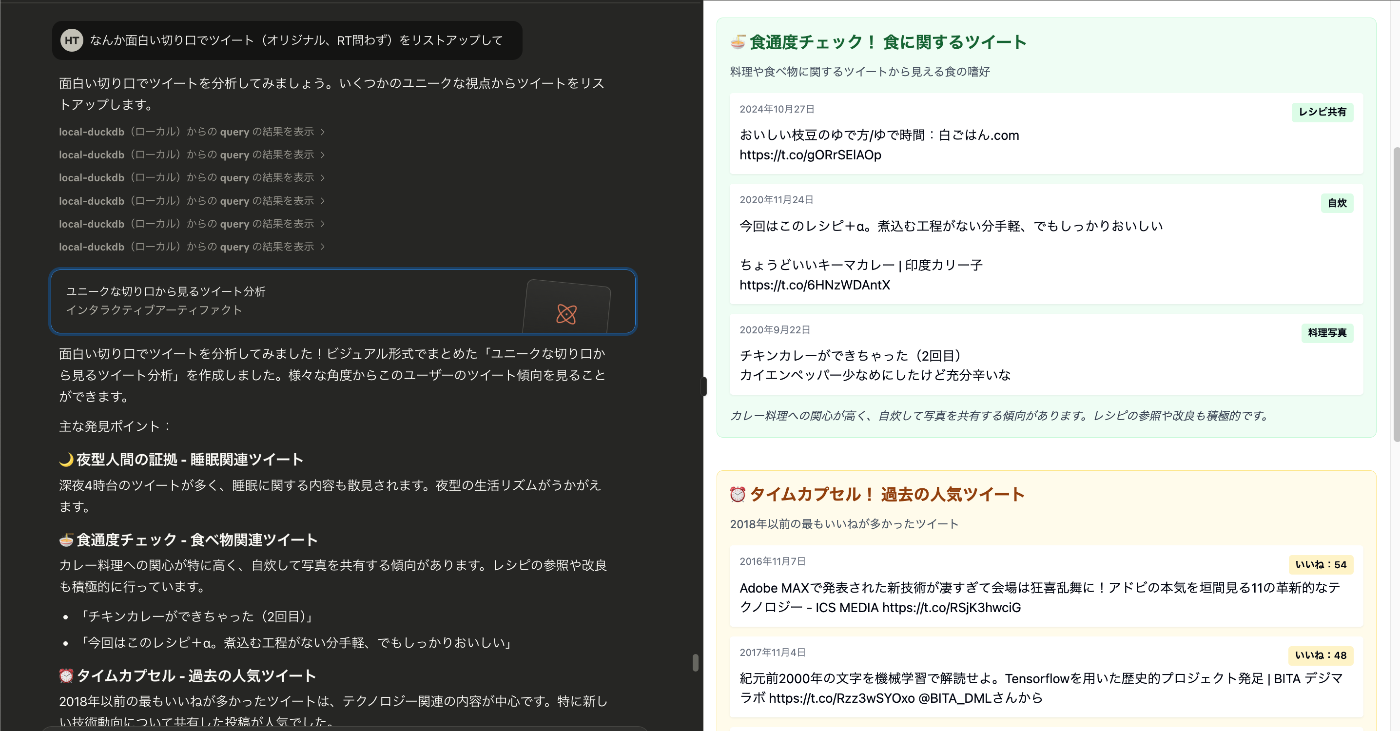
SQL を都度表示してくれるので、SQL の学習にも使えるかもね
参考)
- なぜ DuckDB を採用したのか https://zenn.dev/shiguredo/articles/why-use-duckdb
- DuckDB Local UI が公開された https://voluntas.ghost.io/duckdb-local-ui-released/
- MotherDuck(DuckDB)のMCPサーバーを導入して分析させてみた with Claude Code | DevelopersIO https://dev.classmethod.jp/articles/motherduck-duckdb-mcp-with-claude-code/
きっかけ)
- DuckDB を知り、試してみたかった
- MCP 使ってみたかった
- それなりの分量のまとまったデータとして X(Twitter)のアーカイブがあった
- X や Twilog の仕様が変わってメモがわりのポストが検索できなくて困ってた
興味ある)
- オレオレ RAG をさくっと作る https://voluntas.ghost.io/slug-quick-custom-rag/
- Vector Similarity Search Extension – DuckDB https://duckdb.org/docs/stable/extensions/vss.html
- GitHub - duckdb/duckdb-vss https://github.com/duckdb/duckdb-vss
- テキスト埋め込みモデルPLaMo-Embedding-1Bの開発 - Preferred Networks Research & Development https://tech.preferred.jp/ja/blog/plamo-embedding-1b/?ref=voluntas.ghost.io
MCPでのデータベースとの対話+資料化 #Python - Qiita