Spoon - Javaの静的解析ライブラリ
Spoonとは
SpoonはINRIAが主導して開発しているJavaの静的解析ライブラリで、ソースコードの解析や変換ができます。
以下のリポジトリでOSSとして開発されています。
プログラマ自身が解析・変換の内容をJavaのコードとして簡単に手書きできるのが特徴です。
ある意味では、強力で使いやすいReflection APIのようなものだと思うこともできます。
以下では、spoonの解析手法や、具体的な使い方などについて解説していきます。
本記事中で示すサンプルコードの全体は、こちらのgithubリポジトリで閲覧できます。
Spoonの解析手法
spoonは、解析対象のJavaソースコードを抽象構文木(AST)に分解します。
抽象構文木とは、ざっくり言うとソースコードから本質的でない部分[1]を取り除いた上で木構造に変換したものです。
簡単な例を出すと、数式(a+b)*(c+d)は
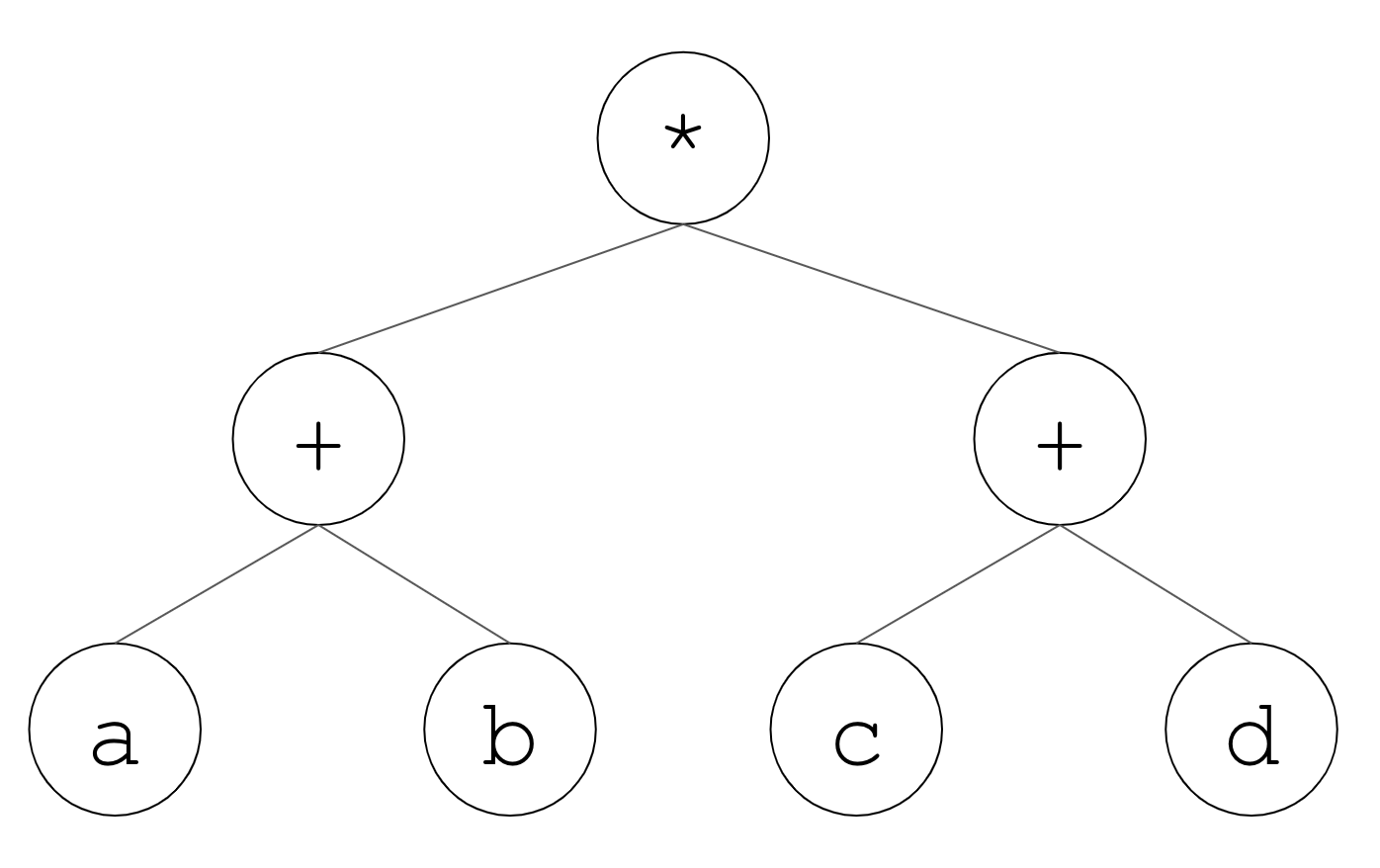
と木構造で表すことができます[2]。
数式について例を出しましたが、spoonの解析対象はJavaのコードなので、パッケージ、クラス、メソッド、フィールドといった対象を木構造で表現していきます。各対象はSpoonのクラス、たとえばCtPackage, CtClass, CtMethod, CtFieldなどで表現されます。
少し込み入った話をすると、これらのクラスは、spoonがJavaのソースコードを解釈する際のメタモデル[3]の要素になっています。
解析の例
ここからは、公式サイトの例に沿ってどのような解析ができるかを解説します。
解説には、執筆時点で最新のリリースである10.4.2を用います。
jarからAST
spoonのやっていることを視覚的に把握するには、とりあえずjarから実行してGUIを確認するのがよいでしょう。
まず、spoonの依存関係つきjarをMavenのcentralリポジトリなどからダウンロードしてきます。
解析対象のクラス(ここではMyClass.javaとします)とjarを同じフォルダ内に配置して、以下のコマンドを実行すると、ASTをGUI上で確認することができます[4]。
java -cp spoon-core-10.4.2-jar-with-dependencies.jar spoon.Launcher \
-i MyClass.java --gui
MyClass.javaが以下のようなファイルであるとします。
package myclass;
public class MyClass {
public String foo() {
return null;
}
}
この場合、コマンドの実行結果は以下の画像のようになります。

クラス、それに属するメソッド、さらにその戻り値、などが階層的に表示されているのが見て取れると思います。
ライブラリとして
まずGUIでの動かし方を解説しました。続いて以下では、Javaのコード上で解析を実施する方法を説明します。
先ほどと同じく、Mavenのセントラルリポジトリからspoonの依存関係を導入しましょう。
例として、Mavenでビルドをする場合[5]、以下の依存関係をpom.xmlに追加します。
<dependency>
<groupId>fr.inria.gforge.spoon</groupId>
<artifactId>spoon-core</artifactId>
<version>10.4.2</version>
</dependency>
そうすると、spoonのLauncherクラスをエントリーポイントとして、コードの解析を行うことができます。
単一クラスの解析
文字列化したクラスの読み込み
最も単純な「文字列化したクラスをパースしてspoonに解析させる」場合から試してみましょう。
解析したいクラスを以下のクラスAとします。クラスAはfooメソッドとbarメソッドを持ちます。
class A {
void foo() {
System.out.println("yeah");
}
String bar() {
return "yeah";
}
}
このクラスを文字列にしたもの[6]を直接Launcher.parseClassメソッドの引数として与えることで、文字列をspoonのCtClassに変換することができます。
CtClass<?> classA = Launcher.parseClass("class A { void foo() { System.out.println(\"yeah\");} String bar() { return \"yeah\" }");
子要素の取得
spoonが構築するASTに属する各クラスからは、自らの子要素を容易に取得することができます。
上のコードで得たクラスAを表すCtClassから、Aのすべてのメソッドとその戻り値の型を取得するには、以下のようなコードを書きます。
// CtClassに属するメソッドを取得
Set<CtMethod<?>> methods = ctClass.getMethods();
for (CtMethod<?> method : methods) {
System.out.println(method.getSimpleName());
System.out.println(method.getType());
}
実行結果は以下のようになり、クラスAに属するメソッドの名前と戻り値の型を取得できていることがわかります。
bar
void
foo
void
ここでは、CtClassからCtMethodを取得し、CtMethodからメソッド名(を表すString)や戻り値の型(を表すCtTypeReference)を取得しました。
同様に、AST上のあらゆる要素を辿っていくことができます。
プロジェクト全体の解析
前節ではひとつのクラスを解析しました。
しかし、実用上は、あるプロジェクトに含まれる複数のソースコードを解析したい場合が多いと思います。
以下のように、myclassパッケージにあるふたつのクラスを同時に解析する場合を考えてみましょう。
myclass
├── AnotherClass.java
└── MyClass.java
この場合は、以下のようなコードを書きます。
SpoonAPI spoon = new Launcher();
// myclassパッケージ配下のコードを一括で解析対象に追加
spoon.addInputResource("src/main/java/myclass");
CtModel model = spoon.buildModel();
CtModelには解析対象のディレクトリに含まれるすべてのクラスの情報が含まれており、model.getAllTypes()として取得することができます。
// myclassパッケージ配下のクラス・インタフェースがCtTypeとして格納されたコレクション
Collection<CtType<?>> types = model.getAllTypes();
クラスの情報から所望する内容だけを取り出すには、Filterを使用します。
たとえば、このtypesに含まれるクラスから、メソッドの情報のみを抜き出してみましょう。
t.getElementsの引数となるFilterの条件にCtMethod.classを指定することで、各CtTypeにおいて定義されているメソッドを抽出することができます。
for(CtType<?> t : types) {
System.out.println(t.getSimpleName() + ": ");
System.out.println(t.getElements(new TypeFilter<>(CtMethod.class)));
}
実行結果は以下のようになります。
MyClassにおいて定義されているfooメソッドとdoNothingメソッド、AnotherClassにおいて定義されているbarメソッドの内容がprintされています。
AnotherClass:
[public java.lang.String bar() {
myclass.MyClass myClass = new myclass.MyClass();
return myClass.foo();
}]
MyClass:
[public java.lang.String foo() {
return null;
}, public void doNothing() {
// do nothing
}]
プロセッサ
ここまではspoonの各クラスのメソッドを呼び出し、ASTをたどって情報を取得する方法を主に見てきました。
spoonにおいてはもうひとつ、主要かつ便利な解析方法があります。それがプロセッサです。
たとえば「解析対象のソースコードの中に、実装が空のメソッドが定義されているか」をチェックしたい場合を考えてみましょう。
その場合、以下のようなプロセッサを定義します[7][8]。
/**
* 空のメソッド用のprocessor.
*/
public class EmptyMethodProcessor extends AbstractProcessor<CtMethod<?>> {
public void process(CtMethod<?> method) {
if (method.getBody().getStatements().isEmpty());
System.out.println("Empty method body: " + method.getSimpleName());
}
}
}
このプロセッサを以下のコードのように Launcherに与えることで、インプットのコード全体にプロセッサを適用してくれます。先ほどの例と同様、myclassパッケージ配下のコードに対して実行してみましょう。
public class ProcessEmptyMethods {
public static void main(String[] args) {
Launcher l = new Launcher();
l.addInputResource("src/main/java/myclass");
// プロセッサをLauncherに追加
l.addProcessor(new EmptyMethodProcessor());
l.run();
}
}
実行結果は以下のようになり、実装が空のメソッドが検知できていることがわかります[9]。
Empty method body: doNothing
おわりに
ここまで、spoonの基本的な使い方について説明しました。
ここで紹介した以外にも様々なできること・活用法があり、Javaのコードに対しておよそあらゆる情報の取得や解析を行うことができます。
Javaのソースコード変換や解析を検討している方は、ぜひ利用するライブラリの候補に加えてみてください。
-
たとえば、かっこや空行など。 ↩︎
-
演算の結合は木構造から自明にわかるので、かっこは不要と考えられます。 ↩︎
-
このあたりは私もあまり自信がないのですが、メタモデルの「メタ」の意味合いについて補足しておきます。Javaの解析においては、一次的な対象はテキストとして書かれたソースコードであり、それに対してASTなどの表現はその「モデル」にあたります。さらにspoonは、「どのようなモデルを作るか」を規定する構造を持っています。それのことを「メタモデル」と呼んでいます。 ↩︎
-
Javaの環境構築ができている(javaコマンドが使える)ことは前提としました。 ↩︎
-
もちろんgradleでもビルドできますが、spoon本体がMavenでビルドされていることもあり、本記事のサンプルコード用のリポジトリでもMavenでビルドしています。 ↩︎
-
コードの見た目が煩雑になるので、改行は省略しました。 ↩︎
-
ここでは、spoonが用意している
AbstractProcessorクラスを継承することで自前のプロセッサを作成しました。AbstractProcessorはspoonのProcessorインタフェースの(abstractな)デフォルト実装という立ち位置なので、基本これを使っておけば大丈夫だと思います。 ↩︎ -
本家のサンプルコードを見ると、
Environmentクラスのreportメソッドを使うのが本筋のようです。しかしこちらはロガーを用いて出力するので、その設定が必要でサンプルプロジェクトが煩雑になるため、今回は標準出力で代用しました。 ↩︎ -
実際には、このプロセッサ定義はあまりよくありません。メソッド定義の中に
// do nothingのようなコメントがあると「空ではない」という判定になってしまうからです。サンプルコードなので許してください。 ↩︎
Discussion