データモデリングによって何を解決したいのか
これはdbt Advent Calendar 2023の16日目の記事です。
夏頃に「なぜデータモデリングに取り組むことが重要なのか」を文章化したものになります。
何を解決したいのかシリーズの第二弾です。
第一弾は「sqlfmtによって何を解決したいのか」になります’。
dbtとデータモデリングにどのような関係があるのか
私はdbtが提供する革新的な価値は次の4つに集約できると考えています
- 処理の依存関係を簡単に記述できる
- マテリアライズ(テーブルやview)を簡単に作成できる
- データ基盤の中でSCD type2を簡単に導入できる
- 自動テストを導入できる
もちろんdocsを生み出せたり、それをホストできたり、いろんな機能がありますが、コアな価値は上記4つに集約されていると考えています。
3と4はぱっと見で価値が伝わりやすいと思いますが、1と2は単独では価値が伝わりにくいと感じます。
今回の記事は1と2の価値を合わせたその先にデータモデリングがあるので、以下補足します。
集計SQLで辛いことあるある
ちょうど昨日前職の同僚であるゲンシュンさんがとても共感できる記事を書いてくれています。
プロダクト側の課題にあるように処理の依存関係を簡単に記述できないと「600行ぐらいのSQLが頑張ってデータを引っ張る」というようなケースは多発してしまうのです。
そして、同様のロジックを別のSQLにも適用する必要が出た際、それをコピペしたり、似たようなロジックがあるとも知らず0からSQLを作成したりといったことが起きてしまいます。
ではビジネスの要請でそのロジックに一部修正が必要になったとしましょう。同じロジックがどのSQLに書かれているかをどうやって調査して修正するかを考えるととても簡単に絶望できますね。
1, 2は上記の問題をどう解決するか
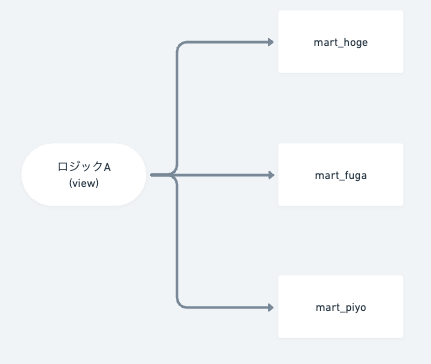
簡素に書くと以下の図のようなことができるのが1, 2の大きな価値だと考えています。
1, 2を用いるとロジックを別のレイヤーに持たせて、インターフェイスを定義しておけば後段のSQLでも扱うことができます。
ロジックの修正が必要になったとしてもインターフェイスを保ったまま中のロジックを修正すれば後段のSQLの修正も最小限に抑えられます。
4の「自動テストを導入できる」と合わせて使うと、リグレッションテストを行いながら修正することも捗りますね。
「dbtを使えば万事解決じゃん!」とはもちろんならない
dbtは魔法のツールではないので、考えて使わないとどのようなことが起きるかもしっかり提示しておきます。
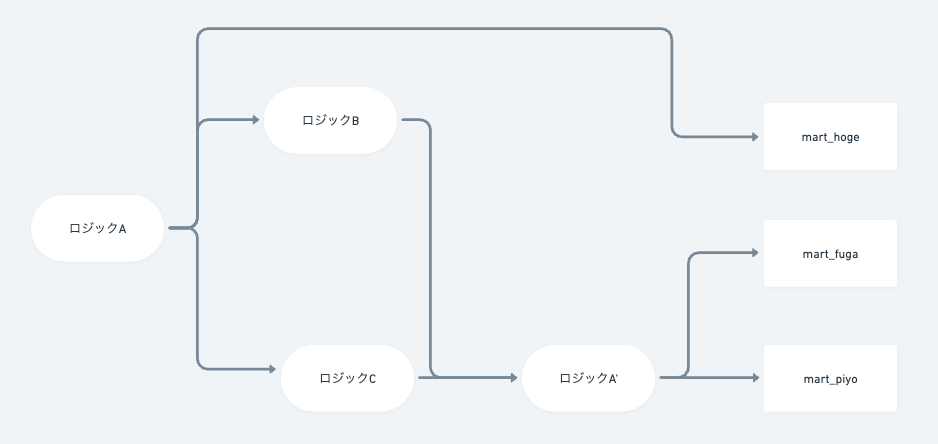
それが以下の図です。私はこれを「リネージの迷宮」と呼んでいます。
ロジックを参照したロジックが生まれ、実はmart_hogeだけが「ロジックA」を使っているが、他のマートは「ロジックA'」を使うようになっていて、mart_hogeは何かしらの考慮漏れが起きている、といった状況です。
改めまして
この秩序をどのような設計でどう保っていくのかをデータモデリングとして位置付け、それがなぜ大切なのかを説明するのが、この記事の目的です。
dbtを使ったその先にどのようなことを考える必要があるのか、その一端に触れてもらえたらなと思います。
技術的なことにはこの記事では触れていませんが、次回のイベントではこれについてもう少し詳しくお話しする予定です。
なぜデータモデリングに注力するか
理想のデータ基盤と、現在のデータ基盤が抱える課題をまず洗い出し、それらの問題を解決するのがデータモデリングの役割である、という構成になっています。
データ基盤の理想の姿
- データユーザー(データ基盤のデータを利用して分析や意思決定を行う人)にとっては、必要な情報にシンプルかつ迅速にアクセスできる
- 基盤開発者にとっては、メンテナンスすべき部分が1箇所に集約されており、ビジネス・プロダクトの変更を迅速に反映できる
- データユーザーと基盤開発者との間には品質についての共通の認識が存在し、品質不足・過剰品質な開発が起きにくい
現在のデータ基盤が抱える課題
基盤開発者視点とデータユーザー視点の課題を分けると、以下のように分類できます。

課題の構造化
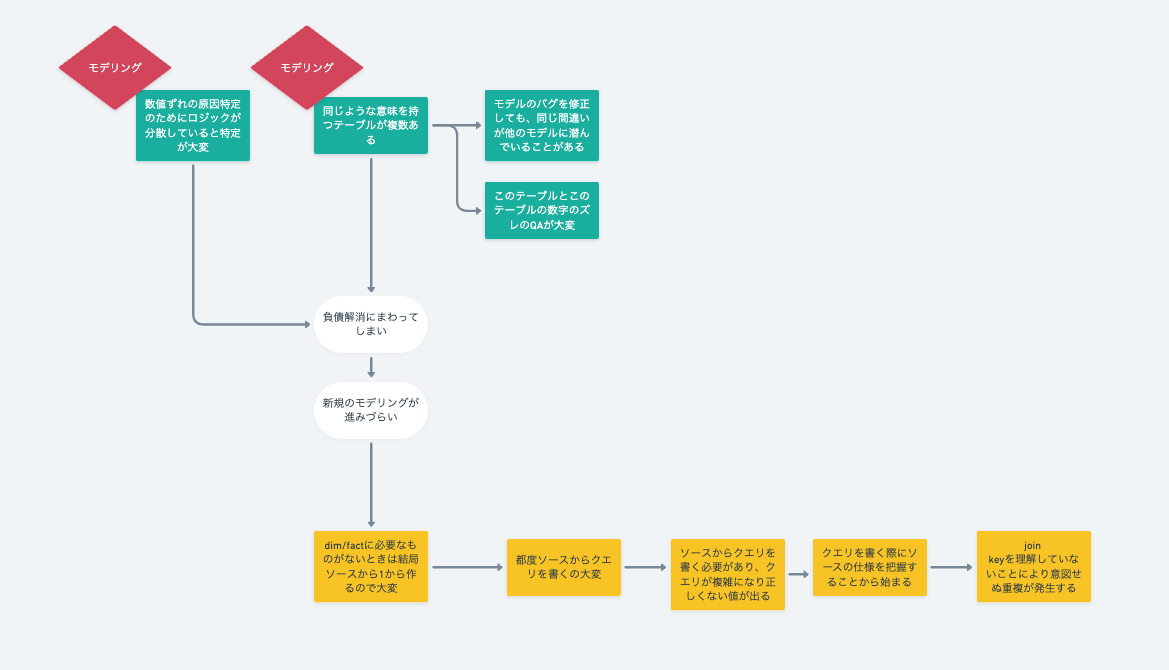
これらは並列な問題ではないと思い、課題を構造化してみました。その結果以下の課題が根本原因となっているのではと考えました。
- 数値ズレの原因特定のためにロジックが分散していると特定が大変
- 同じような意味を持つテーブルが複数ある
根本原因を解決する手段
構造化された課題と根本原因に対する解決策は以下のように考えています。
(data vaultに関する用語が出てきますが、補足をつけているのでご了承ください。)
数値ズレの原因特定のためにロジックが分散していると特定が大変
- レイヤードアーキテクチャーの責務設計の見直し
- business vault層の拡充
- ロジックを記述するモデルが不足しているため、各モデルでロジックを個別に記述することが多々ある。これを集約できるようにする
- 履歴を考慮したsatelliteのjoinを行いやすくする
- データのロードを含めたsatelliteの設計を見直すことで、satelliteを追加しやすくし、データモデリングにアジリティと柔軟性を持たせたい
- つまりデータモデリング
同じような意味を持つテーブルが複数ある
- 「意味」がロジックだったらbusiness vaultへの集約を考慮する
- 「hoge率」という言葉でも、実は分母の集計の仕方が部署によって異なる、などを防ぐために意味合いとしてのロジックを集約していく
モデルの命名規則の統一 - ロジックは同じなのに名前が違うから存在に気づかないなどを防ぎたい
- 「hoge率」という言葉でも、実は分母の集計の仕方が部署によって異なる、などを防ぐために意味合いとしてのロジックを集約していく
- つまりデータモデリング
data vaultのアジリティのポテンシャルを引き出せていない
- 過去のデータを取り込むことがネックになるのでこのタイミングでビジネスプロセスを洗い出して、必要なものがあれば過去の分も取り込む
- 基本的にdata vaultは(その中で履歴管理を行なっているため)full-refreshをしないが、モデリングしきれていない部分があるのであれば洗い出してここからでも取り込めるようにする
- 過去のデータを取り込む必要があったときのスタンスを明確にする
- こういうときはv0.2をfull refreshする、こういうときは対象のモデルのみをfull refreshする等
- つまりデータモデリング
まとめ
つまりデータモデリング
少し真面目に
はじめの方で「dbtを導入すると、ロジックのコピペを防いで管理しやすくなる!」ということを謳っていた割には現実はそう甘くもないことが少しは伝わるかなと思います。
最近はロジックのSSOTを考える日々を送っています。
ビジネスの中では、これらの問題もほんの一部で、実際にはアプリケーションの仕様の変更、ビジネスロジックの変更、法的な対応などいろんな要請をデータ基盤は受けます。
それらをいかに早くキャッチアップするか、データ基盤に反映させるか、どのくらいのデータの品質が必要でどのように保証するか、考えることはたくさんあります。
その中でいかに効率的かつ正確にデータ基盤を開発・運用していくかは大切なテーマの一つだと考えます。
Discussion