🕊️
Twitter Recommendation Algorithmについて
はじめに
Twitterのレコメンドアルゴリズムが公開されました
公開されてから二日間ほどコードを追っていたので、一部にはなりますがまとめようと思います
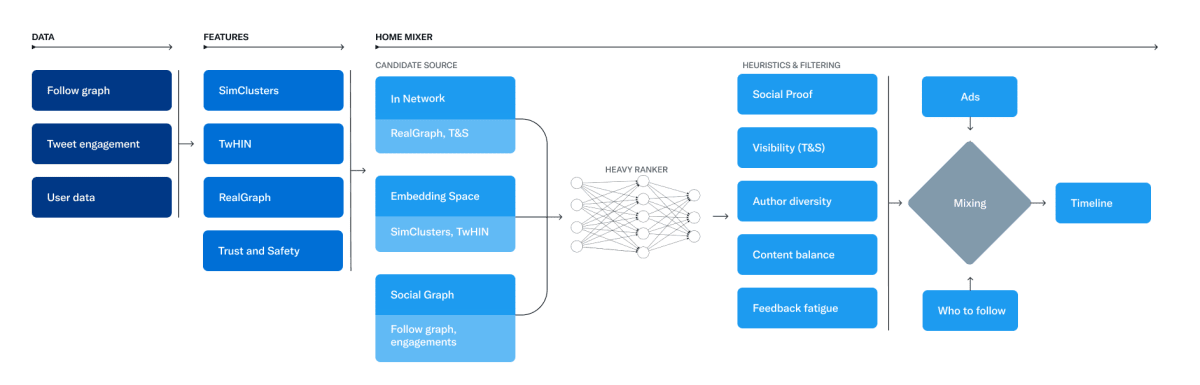
全体像
-
データ量
- 5億ツイート/日
-
レコメンドシステム構成
- Multi-stage
- Candidate Sources(=候補生成)
- Ranking(=ランク付け)
- Heuristics,Filters,and ProductFeatures(=フィルタリング)
- Multi-stage
補足) Multi-stageレコメンドシステム
ステージを複数用意し、効率的にレコメンドするアイテムを絞っていくシステムの構成のこと
以下のRecsys2022のスライド資料などがわかりやすいです
1. Candidate Sources
概要
- この層ではアイテムを大雑把に絞ることが目的なので、精度よりスピードが求められる
- 具体的には、数億あるアイテムの中から1500までに絞るそう
- ScalaとたまにPython
- In-Network-SourcesとOut-of-Network-Sourcesから50%ずつレコメンドする
- In-Network-Sources: フォローしているユーザ
- Out-of-Network-Sources: フォローしていないユーザ
Candidate Sourcesでのモデル
- In-Network-Sources
- Real Graph
- https://github.com/twitter/the-algorithm/tree/main/src/scala/com/twitter/interaction_graph
- ユーザ間のエンゲージメントの可能性を予測するモデル
- Real Graph
- Out-of-Network-Sources
- GraphJet
- https://github.com/twitter/GraphJet
- フォローしていないのに、あるツイートが自分に関連するかどうかを判断するのが難しい -> 2つのアプローチをとっている
- 自分がフォローしている人達がどんなツイートをしたか
- 自分と似たような'いいね'をしている人たちは他にどんなツイートに'いいね'しているか
- SimClusters
- https://github.com/twitter/the-algorithm/tree/main/src/scala/com/twitter/simclusters_v2
- 任意の2人のユーザ、ツイート、ユーザとツイートのペア間の類似度を計算しEmbeddingを得る
- 行列分解手法であるMatrix Factrizationをカスタムしたものを使っているそう
- 得られたEmbeddingを利用して影響力のあるユーザを中心にコミュニティを形成し、その数は145kもあるとのこと
- GraphJet
2. Ranking
概要
- この層では1500件に絞られたツイートをランク付けする
- モデルの精度が大事になってくる
- 48Mのニューラルネットワークが継続的に'いいね', RT, Replyから学習を行っている
Rankingでのモデル
- LIGHT RANKER
- https://github.com/twitter/the-algorithm/tree/main/src/python/twitter/deepbird/projects/timelines/scripts/models/earlybird
- ※ READMEを読むと現在リプレイス中とのことなのでスキップ
- HEAVY RANKER
- https://github.com/twitter/the-algorithm-ml/tree/main/projects/home/recap
- Python(torchrec)
- 下記に詳しく記載
HEAVY RANKER
Candidate Sourcesを経て1500件程度に絞られたツイートの中でRankingをつける
入力特徴量
モデル
-
MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask
-
https://arxiv.org/abs/2102.07619
- CTRの推定を行うには複雑な高次の特徴をモデルを用いて捉える必要がある
- DNN(=DeepNeuralNetwork)モデル(ex. FNN, DeepFM, xDeepFM)は高次の特徴を捉えるのに使われている
- しかし、一部共通の特徴量を捉えるためにfeed-forward層が非効率なことがわかっている
- そこで、instance-guided maskというembedding層とfeedforward層の両方で要素ごとの積を計算する処理を提案
- MaskNetではDNNモデルにMaskBlockというレイヤー正規化、instance-guided mask、feed-forward層を組みあわせた構造を導入してみた
- 結果、DeepFMやxDeepFMなどの性能を超えSOTA
- PyTorchでの再現実装
- TwitterでのMaskNetの実装部分
-
https://arxiv.org/abs/2102.07619
補足) torchrecとは
PyTorchが提供する大規模なDeepLearningレコメンドシステムを構築する際に必要な機能を提供するライブラリ
具体的に以下のことが簡単にできるようになる
- multi-device
- multi-node
- data-parallelism
- model-parallelism
3. Heuristics,Filters,and ProductFeatures(=フィルタリング)
- Visibility Filtering: ブロックやミュート中のアカウントのツイートを含めない
- Author Diversity: レコメンドするツイートのアカウントにバリエーションをもたせる
- Content Balance: In-Network-Sources, Out-of-Network-Sourcesでバランスをとる
- Feedback-based Fatigue: ネガティブなフィードバックがあった場合に特定のツイートのスコアを下げる
- Social Proof: 2次的なつながりのないツイートを除外。フォローしている誰かが、そのツイートに関与するorフォローしているアカウント
- Conversations: 会話をスレッドとして出す
- Edited Tweets: 編集済みのツイートなら更新
おわりに
- 情報量が多すぎてRanking部分しかろくに見れていないですが、他も見ていきたいです
- torchrecの存在は知っていたのですが、ネット上に情報がなさすぎたので、Twitterで使われていて驚きました
- Twitterレベルの大規模なシステムのレコメンドの実装が見られるのは貴重ですし、面白いので是非ご覧になってみてください
Discussion