Stable Diffusion による image-to-painting
はじめに
この記事は、生成AI Advent Calendar 2024 の20日目の記事です。
この記事では、image-to-painting について調査したことをまとめてみました。
image-to-painting とは、一枚絵から絵の描画プロセスを生成するタスクのことです。
-
入力 (image)

-
出力 (painting)

調査したモチベーションとしては、Stable Diffusion ではノイズ除去を通して画像生成をしており、実際に絵を描くときのプロセスとは大きく異なります。そこで、実際の描画プロセスを Stable Diffusion を用いて生成するとしたらどのような技術が必要になってくるのかに興味を持ちました。また、この描画プロセスの生成技術を用いて、制作途中の絵を入力として完成までの過程を step 単位で生成することもできるのではないかとも思い、調べるに至りました。
前提
これまで、image-to-painting というタスクに対し、ストロークを予測する Stroke-Based Rendering (=SBR) 手法として様々なアプローチでの提案がなされてきました。
- stepwise greedy search
- RNN
- RL
- parameter searching
- (変わり種) semantic segmentation + 階層的レンダリング
例えば、parameter searching の Stylized Neural Painting[1] という手法では、従来まで pixel 単位の予測として定式化していたものをストロークパラメータの探索として定式化するようにしています。
各 step でストロークの形状、色、透明度を含むパラメータを最適化して、参照画像に近づけるようにしています。
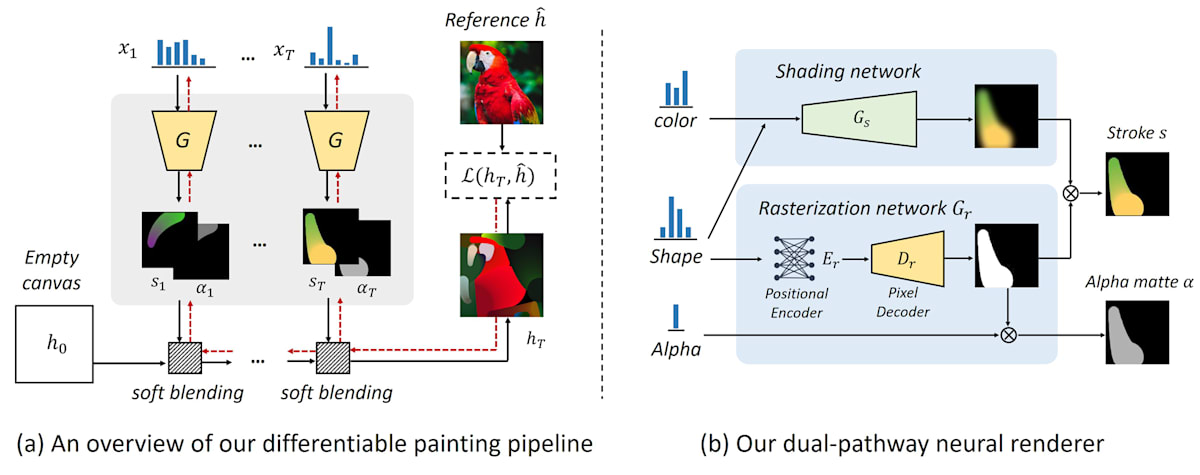
出力結果 (Demo動画)
また、Paint Transformer[2] という手法では、ストローク予測ではなく、ストロークセット予測として定式化しています。
ストロークセットとは、現在のキャンバスと完成画像の間の差分を埋めるストロークを一括で予測するということです。
Transformer とあるように、並列でストロークを予測できるので、高速な生成ができるようになったそうです。
loss も pixel loss と stroke loss の2つをとるようにしていたりと工夫がなされていて面白いです。
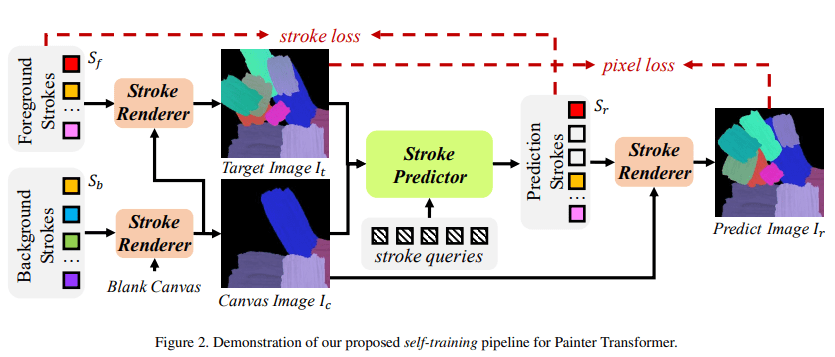
出力結果

Stable Diffusion による image-to-painting
以下の2つについて調べました。
- ProcessPainter
- Paints-UNDO
ProcessPainter[3]
- 会議: CVPR2024
- code: https://github.com/nicolaus-huang/ProcessPainter
概要
- DiffusionModel を用いて描画プロセスを生成する text-to-video モデル
- 以下のような生成が可能
- text-to-painting
- image-to-painting
- semi-to-complete

背景
- SBR 手法は画像をブラシストロークの系列に分解するが、基本的なブラシストロークに限定されるので、描画プロセスを再現するには不十分
- 拡散プロセスを利用した text-to-image モデルはノイズ除去を通して画像生成しており、これも実際の描画プロセスからは大きく乖離している
提案手法
ProcessPainter という text-to-video モデルを提案
- モデルアーキテクチャ
- Temporal-Attention を用いた事前学習済み Stable Diffusion
- Temporal-Attention は U-Net の各レイヤーに追加されていて、(今回では描画プロセスにおける) キーフレーム間の関係性を捉えることができるようになる
- Artwork Replication Network
- 画像 Context からの入力を受け付けることが可能になる。すなわち、任意のフレームからの描画プロセスを生成できるようになる。
- Temporal-Attention を用いた事前学習済み Stable Diffusion
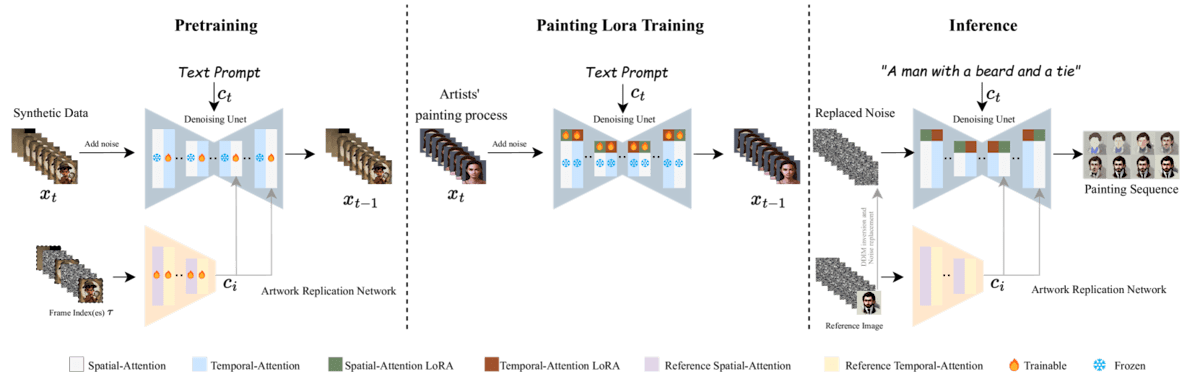
- 学習方法
- 合成データセットを用いて Temporal-Attention を用いた Stable Diffusion に対し事前学習
- SBR 手法 (Learn-to-Paint, Stylized Neural Painting, Paint Transformer) を用いて、一枚絵から描画プロセスへと変換し、大規模な合成データセットを作成した
- 一般的な映像生成と異なり、描画プロセスは最初から最後にかけてかなりの変化が起きるので、大規模学習が必要
- 描画プロセスデータセットによる LoRA
- 10~50 の描画プロセスデータを用いる
- 合成データセットを用いて Temporal-Attention を用いた Stable Diffusion に対し事前学習
感想
従来の SBR 手法に比べ、描画スタイルを柔軟に LoRA によって学習・生成できるようになり、image-to-painting の活用範囲が広がったと思いました。(特に、イラストの描画プロセスの生成において)

また、任意のキーフレームから完成まで持っていけるという技術が需要がありそうに思いました。
合成データセットを作って事前学習からやる必要があるので、上手いことモデルを学習させるのが難しそうな印象を受けました。
推論を動かしてみようとしたところ VRAM が 30GB も必要とのこと。悲しい。。。
MINIMAL 30GB GPU memory is REQUIRED for SINGLE inferencing!!!
あとでクラウドの GPU で動かしてみたいです。
Paints-UNDO
概要
- Illyasviel-san の一枚絵からの描画プロセス生成ツール
- イラスト特化 (?)
Demoページ
提案手法
以下の記事で詳しく解説されている。
かいつまんで書くと、
single-frame model と multi-frame model の2種類で構成されている。
- single-frame model: 一枚絵からキーフレームを生成
- Stable Diffusion ベース
- TimeStepEmbedding で現在どのステップかの情報を持たせている
- multi-frame model: 生成したキーフレームから描画プロセスを生成
- Video Crafter ベース
感想
single-frame model は、ProcessPainter の改良版? TimeStepEmbedding でキーフレームの時系列 step 情報を持たせていて、Attention は使われてなさそうでした。
実際に動かしてみた所感として、モデルの latent 次第な感じがありました。
具体的には、学習データがたくさんある Prompt を入れると精度の良い出力となりますが、そうでない Prompt だと微妙な出力となりがちでした。
ベースモデルが SD1.5 なので、今だったら SDXL に置き換えてみたら出力精度が上がるかもしれないです。
おわりに
image-to-painting について調査したことをまとめてみました。
調査する前は、大量の描画プロセスデータセットをどう用意するのかが最大の疑問だったのですが、合成データセットとして作成していることがわかり、腑に落ちました。
Paints-UNDO から追えてないので、最近ではもっと進化しているかもしれません。
参考
- SBR 手法についてのサーベイ (?) 論文: https://arxiv.org/abs/2302.00595
Discussion