SeamlessM4Tでほんやくコンニャクを実現できた...のか?
はじめに
去年の11月にMetaからSeamlessM4Tのv2がリリースされました。
少し前の話ですが、SeamlessM4Tを使った音声認識、翻訳機能をWEB上に実装したデモを作ってみたのでその時の話をしたいと思います。
モチベーション
普段はWEBのバックエンドをメインで開発していますが、社内で本業外でラボ的な活動があり、その発表に何かインパクトのある成果物を発表できないか?と考えたのがきっかけです。
業務ではLLMとの接点は薄いのですが、これを機に触ってみようかと思いました。
またどうせなら文字起こし、からの翻訳までできたら面白そうと思い色々探してみましたが、Metaが出しているLLMが良さそうと考えました。
※OpenAIにもWhisperという音声認識モデルがありますが、テキスト出力が英語しか対応していないとのことで、
- Whisper -> 英文で出力 -> ChatGPT -> 翻訳し日本語出力
だとレスポンスが返るまでにそれ相応の時間がかかると漫然に考えていました。
(SeamlessM4Tでもレスポンス返ってくるまでにそこそこ時間がかかりますが...)
ほんやくコンニャクを謳っている通り、ニアリアルタイムで音声認識、翻訳、テキスト出力を行いたいのでマルチモーダルモデルのSeamlessM4Tなら可能なのか?と思いとりあえずデモを作ってみました。
使用した環境
Google Colab
Pythonのブラウザ実行環境です。
説明不要かと思いますが、無料でGPU使えます。
※90分、12時間ルールがあるので注意。
ngrok & flask
-
ngrok
- こちらも説明不要かと思いますが、localネットワークをトンネリングして外部公開できるサービスです。
-
flask
- こちらも説明不要。PythonのWeb FWです。
Render
次世代のHerokuと言われているPaaSです。
フロントをデプロイするために使用しました。Github連携でのデプロイが秀逸です。
WEBサーバー立てる
Google colabo上のflaskアプリケーションをngrokを使って外部公開します。
note bookはこんな感じ。
必要ライブラリのインストール、事前準備
import os
from google.colab import userdata
# シークレットにngrokのtokenを保存しているので、シークレットを環境変数にマッピングします。
os.environ['NGROK_TOKEN'] = userdata.get('NGROK_TOKEN')
# ngrokの取得
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.tgz
# ngrokの展開
!tar -xvf /content/ngrok-stable-linux-amd64.tgz
# flaskインストール
!pip install flask -q
# ngrokとflaskの連携用ライブラリインストール
!pip install flask-ngrok -q
# ngrokの認証通す
!./ngrok authtoken $NGROK_TOKEN
# cors用ライブラリ(FEとBEでドメインが異なるため、Preflightリクエストの対応)
!pip install -q flask-cors
# リポジトリのcloneと依存関係のinstall
!pip install git+https://github.com/huggingface/transformers.git
ngrokは事前にDL並びにアカウントの作成など行なっておいてください。
flaskでエンドポイントを実装する
import os
from flask_ngrok import run_with_ngrok
from flask import Flask, request
from flask_cors import CORS
import torchaudio
import torch
from transformers import AutoProcessor, SeamlessM4Tv2Model
ALLOWED_EXTENSIONS = 'wav'
FILE_NAME = 'request-translation-audio.wav'
RESAMPLE_RATE = 16_000
app = Flask(__name__)
# 以下のパスのみ無条件でCORSを通す
cors = CORS(app, resources={r"/": {"methods": ["GET"]}, r"/trans": {"methods": ["POST"]}}) # cors
app.config['JSON_AS_ASCII'] = False # JSONでの日本語文字化け対策
run_with_ngrok(app)
# ここでDLが発生する。モデルが10gほどあるので少々時間がかかる。
processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large")
@app.route("/")
def home():
return 'home.'
@app.route('/trans', methods=['POST'])
def trans_wav_fail():
lang = request.form['lang'] # 翻訳する言語
file = request.files['wav'] # 送信された翻訳元音声ファイル
ext = file.filename.rsplit('.', 1)[1].lower()
if ext == ALLOWED_EXTENSIONS:
file.save(os.path.join(file.filename))
waveform, sample_rate = torchaudio.load(FILE_NAME)
audio = torchaudio.functional.resample(waveform, orig_freq=sample_rate, new_freq=RESAMPLE_RATE) # SeamlessM4Tを利用するためにはWAVファイルを160000Hzに変換する必要あり(パラメータのデフォルト値)
audio_inputs = processor(audios=audio, return_tensors="pt")
output_tokens = model.generate(**audio_inputs, tgt_lang=lang, generate_speech=False)
translated_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
return str(translated_text)
app.run()
以下を参考にしました。
また今回はlargeモデルを使用しています。
フロントの準備
フロントはサクッと使い慣れているvueでプロジェクトを準備します。
$ yarn create vite [project name] --template vue
以下はメインとなるApp.vueのソース
<script setup lang="ts">
import { onMounted, ref, computed } from 'vue';
import SiriWave from 'siriwave';
// 音声区間検知用のライブラリ
import { MicVAD, utils } from '@ricky0123/vad-web'
const selectedOption = ref<string>('');
const isChecked = ref<boolean>(false);
// textでoutputできる言語は以下を参照。
// @see https://huggingface.co/facebook/hf-seamless-m4t-large/blob/main/generation_config.json#L48-L145
const LANGS = ['afr','amh','arb','ary','arz','asm','azj','bel','ben','bos','bul','cat','ceb','ces','ckb','cmn','cmn_Hant','cym','dan','deu','ell','eng','est','eus','fin','fra','fuv','gaz','gle','glg','guj','heb','hin','hrv','hun','hye','ibo','ind','isl','ita','jav','jpn','kan','kat','kaz','khk','khm','kir','kor','lao','lit','lug','luo','lvs','mai','mal','mar','mkd','mlt','mni','mya','nld','nno','nob','npi','nya','ory','pan','pbt','pes','pol','por','ron','rus','sat','slk','slv','sna','snd','som','spa','srp','swe','swh','tam','tel','tgk','tgl','tha','tur','ukr','urd','uzn','vie','yor','yue','zlm','zul'];
// 翻訳した一文字あたりの表示時間
const READ_TIME_MS = 200;
// レスポンスの翻訳テキストを表示する累計時間
const readTimeAll = ref<number>(0);
const siri = ref<any>();
const myvad = ref<any>();
// レスポンスとして返される翻訳されたテキスト
const responseTextArr = ref<string[]>([]);
// スタックされたテキストの一番最初を表示する
const translated = computed(() => {
return responseTextArr.value[0] || '';
});
const toggleWave = async (amplitude: number) => {
await siri.value.setAmplitude(amplitude);
}
const translation = async (file: any) => {
let formData = new FormData();
formData.append('lang', selectedOption.value);
formData.append('wav', file, 'request-translation-audio.wav');
const url = `${import.meta.env.VITE_BASE_URL}/trans`;
const resp = await fetch(url, {
method: "POST",
headers: {
'ngrok-skip-browser-warning': '1',
// 'Content-Type': 'multipart/form-data' // fetchではContent-Typeの指定はできない、boundayをよしなに設定してくれなくなる
},
body: formData,
})
const response = resp.status;
const text = response === 200 ? await resp.text() : 'SOME ERROR';
responseTextArr.value.push(text);
readTimeAll.value += text.length * READ_TIME_MS;
// 文字の長さから表示時間を設定し、setTimeoutでスタック配列から削除する。
setTimeout(() => {
responseTextArr.value = responseTextArr.value.filter((item: string) => {
return item != text;
});
readTimeAll.value -= text.length * READ_TIME_MS;
}, readTimeAll.value);
// ====================================================
// debug用(生成したwavファイルをDLして内容を確認したい時用)
// ====================================================
// // FileオブジェクトからBlobオブジェクトを作成
// const blob = new Blob([file], { type: file.type });
// // Blobオブジェクトを含むURLを作成
// const blobURL = URL.createObjectURL(blob);
// // ダウンロードリンクを作成
// const downloadLink = document.createElement("a");
// downloadLink.href = blobURL;
// downloadLink.download = file.name; // ファイル名を指定
// // ダウンロードリンクをクリックしてダウンロードを開始
// downloadLink.click();
// // 使用後にURLを解放する
// URL.revokeObjectURL(blobURL);
};
const makeVADInstance = async (onTranslate: (file: any) => void, onToggleWave: (amplitude: number) => void) => {
return await MicVAD.new({
onSpeechStart: () => {
onToggleWave(1);
},
onSpeechEnd: (arr) => {
onToggleWave(0);
const wavBuffer = utils.encodeWAV(arr)
const file = new File([wavBuffer], `audio.wav`);
try {
onTranslate(file);
} catch (err) {
console.log(err);
}
},
});
}
const handelClick = async (e:any) => {
try {
// マイクがブロックされているか判定するためにstreamを取得する
const stream = await navigator.mediaDevices.getUserMedia({ audio: true});
// 取得したstreamは使用しないので停止する
stream.getTracks().forEach(function(track) {
track.stop();
});
if (!selectedOption.value) {
e.preventDefault();
alert('言語が選択されていません。');
} else {
isChecked.value = !isChecked.value;
if (isChecked.value) {
myvad.value.start();
} else {
siri.value.setAmplitude(0);
myvad.value.pause();
}
}
} catch (err: any) {
console.error(err);
e.preventDefault();
alert('マイクの使用が許可されていません。');
}
};
onMounted(async () => {
// amplitudeを1にして開始しないとreavtiveにならないので1 -> 0に変更している
siri.value = new SiriWave({
container: <HTMLElement>document.getElementById("siri-container"),
width: 1020,
height: 400,
style: 'ios9',
amplitude: 1
});
await siri.value.setAmplitude(0);
myvad.value = await makeVADInstance(translation, toggleWave)
});
</script>
<template>
<div>
<select v-model="selectedOption" class="custom-select">
<option value="" disabled selected hidden>言語を選択</option>
<option v-for="(lang, index) in LANGS" :value="lang" :key="index">{{ lang }}</option>
</select>
</div>
<div class="container">
<div id="siri-container"></div>
<span class="responce-text">{{ translated }}</span>
</div>
<div
class="switch-checkbox"
:class="{ 'switch-checkbox-checked' : isChecked }"
@click="handelClick"
>
<input
type="checkbox"
:value="isChecked"
/>
</div>
</template>
<style scoped>
.custom-select {
position: fixed;
width: 200px;
padding: 10px;
font-size: 16px;
border: 1px solid #ccc;
border-radius: 5px;
background-color: #242424; /* 背景色に合わせる */
color: #fff; /* テキスト色を白に設定 */
appearance: none;
-webkit-appearance: none;
-moz-appearance: none;
background-image: url('data:image/svg+xml;utf8,<svg fill="%23fff" xmlns="http://www.w3.org/2000/svg" viewBox="0 0 24 24"><path d="M7 10l5 5 5-5z"/></svg>'); /* アイコンの色を白に設定 */
background-repeat: no-repeat;
background-position: right 10px top 50%;
margin-top: 1rem;
margin-right: 1rem;
right: 0;
}
.responce-text {
font-size: 2rem;
height: 2rem;;
}
.container {
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
box-sizing: border-box;
background-color: #242424;
height: 100%;
}
.switch-checkbox {
position: relative;
z-index: 0;
bottom: 15vh;
float: right;
margin-right: 5vh;
}
.switch-checkbox input[type=checkbox] {
position: relative;
cursor: pointer;
width: 10vh;
height: 10vh;
border-radius: 50%;
background: linear-gradient(145deg, #424242, #181818);
box-shadow: 0 0px 8px #666;
-webkit-appearance: none;
-moz-appearance: none;
appearance: none;
vertical-align: middle;
transition: .2s;
}
.switch-checkbox input[type=checkbox]::before {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
color: #efefef;
font-family: "Font Awesome 5 Free";
font-size: 4vh;
font-weight: 900;
content: "\f130";
transition: .2s;
}
.switch-checkbox input[type=checkbox]::after {
position: absolute;
top: -8px;
right: -8px;
bottom: -8px;
left: -8px;
border-radius: inherit;
background: linear-gradient(#efefef, #cecece);
z-index: -1;
content: "";
transition: .1s;
}
.switch-checkbox-checked input[type=checkbox] {
background: linear-gradient(145deg, #181818, #424242);
}
.switch-checkbox-checked input[type=checkbox]::before {
color: #19FF97;
text-shadow: 0 0px 3px #1CD892;
}
.switch-checkbox-checked input[type=checkbox]::after {
background-image: linear-gradient(135deg, #69FF97 10%, #00E4FF 100%);
box-shadow: 0 0px 10px #69FF97;
}
</style>
詳細説明
VAD用のライブラリ
import { MicVAD, utils } from '@ricky0123/vad-web'
VAD(Voice Activity Detection)は音声の区間を検知するための技術です。
音声の途切れを検知してwavファイルにして都度リクエストするようにしています。
const makeVADInstance
= async (onTranslate: (file: any) => void, onToggleWave: (amplitude: number) => void) => {
return await MicVAD.new({
onSpeechStart: () => {
onToggleWave(1);
},
onSpeechEnd: (arr) => {
onToggleWave(0);
const wavBuffer = utils.encodeWAV(arr)
const file = new File([wavBuffer], `audio.wav`);
try {
onTranslate(file);
} catch (err) {
console.log(err);
}
},
});
}
上記の関数が音声が途切れたタイミングで発火して音声をwavファイルに変換してサーバー側に送信しています。
音声に反応して波形描画
import SiriWave from 'siriwave';
今回はsiri風の波形描画を表示してみました。
こちらのライブラリを利用させてもらってます。
サーバー側
@app.route('/trans', methods=['POST'])
def trans_wav_fail():
lang = request.form['lang'] # 翻訳する言語
file = request.files['wav'] # 送信された翻訳元音声ファイル
ext = file.filename.rsplit('.', 1)[1].lower()
if ext == ALLOWED_EXTENSIONS:
file.save(os.path.join(file.filename))
waveform, sample_rate = torchaudio.load(FILE_NAME)
audio = torchaudio.functional.resample(waveform, orig_freq=sample_rate, new_freq=RESAMPLE_RATE) # SeamlessM4Tを利用するためにはWAVファイルを160000Hzに変換する必要あり(パラメータのデフォルト値)
audio_inputs = processor(audios=audio, return_tensors="pt")
output_tokens = model.generate(**audio_inputs, tgt_lang=lang, generate_speech=False)
translated_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
return str(translated_text)
transというpathにwavファイルをPOSTしてモデルに渡します。
結果
日本語:「今日はいい天気ですね」
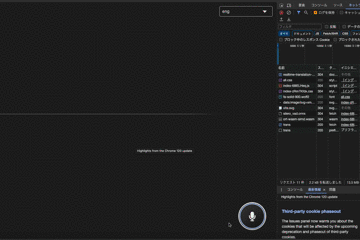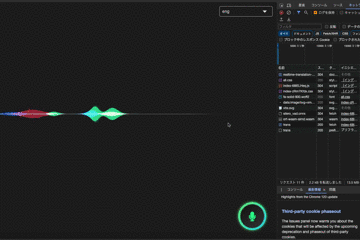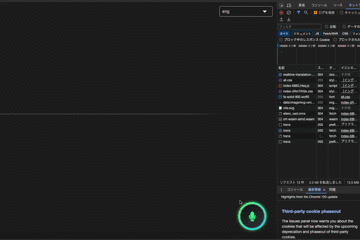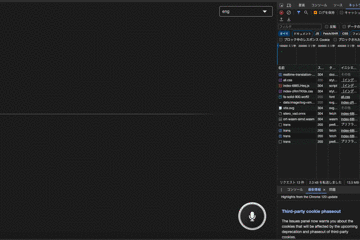
transへのリクエストが発生しているタイミングでVADで区間検知してwavファイルを送信しています。
ちゃんと翻訳できていそう。(若干怪しいですが。。。)
日本語:「最近キーボード買ったんですよ」
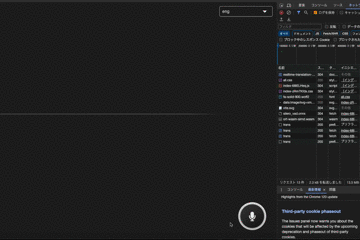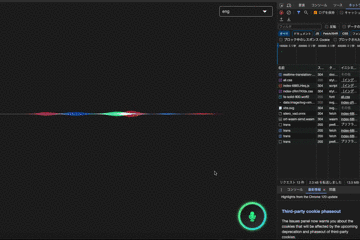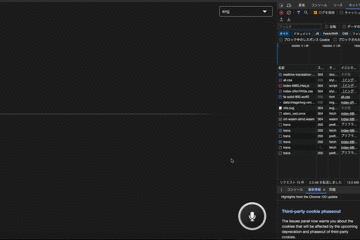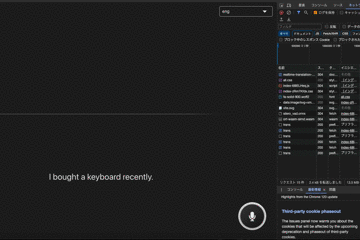
まあ大丈夫そう。。
日本語:「上位モジュールはいかなるものも下位モジュールから持ち込んではならない。双方とも抽象に依存するべきである。」
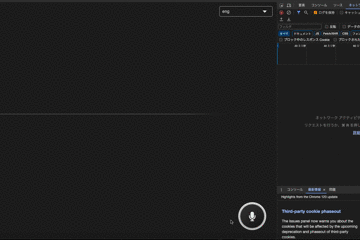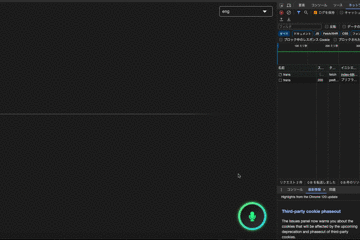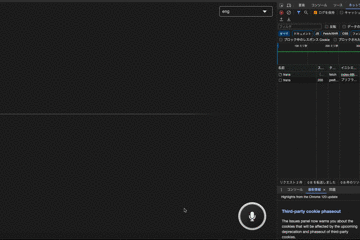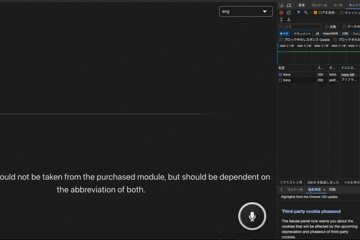
ちょっと見切れてしまっていますが。。
うーん、、なんとも、、単語単語では正しいところはありつつ文としてはよくわからない結果に。。
ちなみに上記は依存性逆転の原則の一文ですが、正しい一文は以下です。
High-level modules should not import anything from low-level modules. Both should depend on abstractions.[1]
入力された音声にもよるところがありますが、そのほかの文でも少しおかしなところが見受けられました。
そのほかのLLMでもあることですがやはり日本語の学習量の少なさによる誤認識の部分もあるのかも知れません。
総括
音声認識による翻訳とテキスト出力をニアリアルタイムで表示することでほんやくコンニャクの如き機能をWEB上に実現できるかと思っていましたがレスポンスの遅さ、翻訳精度の問題で若干厳しそうな印象でした。
レスポンスの遅さはマシンスペックをお金の力でなんとかすれば解消できるかもですが、翻訳精度に関してはなんともできないため思っていたようにはできませんでした。
音声認識、自動翻訳をビデオ通話上に拡張として提供など妄想していましたが現時点では難しそうですね。。
(そもそもSeamlessM4Tのライセンスが商用利用不可なので注意が必要)
思った結果とはなりませんでしたが、デモで作ったものにとしては面白いものができたと思っています。
次は何試そうかな〜😄
Discussion