

機械学習を中心に担当している川尻です。テラーノベルでは、Google AnalyticsのBigQuery Export機能を活用して、あらゆるデータ分析に取り組んでいます。7月にBigQueryの価格改定があり、クエリを効率的に投げる方法を検討し、運用を開始しました。その方法を紹介します。
背景
Google Analyticsはアプリの使用状況などを分析できるサービスで、従来はFirebase Analyticsという名称でしたがGoogle Analyticsに統合されました。BigQueryへのエクスポート機能があり、1日1回、1日分のデータが1つのテーブルとして出力されます。現在のテラーノベルのサービスでは、1日平均30GB程度のサイズになります。これらのデータは、定常的に処理されるタスク以外にも、アドホックに数日から数ヶ月分のデータを読み込んで解析することも頻繁にあります。その場合、試行錯誤するために何度もクエリを投げることがあり、気を付けてクエリを投げることになってしまいます。
一方、2023年7月にBigQueryの料金が改定され、オンデマンド料金の主な変更点は以下の通りです。
- 分析料金
- オンデマンド分析モデルの価格が25%値上げ
- BigQueryのオンデマンド料金は読み込んだデータ量で決まる。
- ストレージ料金
- 圧縮されたデータサイズをもとに計算されるように変更。
- 10倍以上の圧縮率で、圧縮したストレージに料金がかかる単価は通常の2倍に。
- 全体としては、約20%以下の料金単価に値下げになる。
つまり、ストレージのデータ量が増えても、解析で読み込むデータ量を減らしたいという状況が生じています。そこで、BigQueryのパーティショニングとクラスタリングの機能を使って、別のテーブルに出力し直すことを検討しました。
BigQueryのパーティショニングとクラスタリングについて
パーティショニングとクラスタリングを使用すると、分析時に読み込まれるデータをフィルターすることができ、クエリにかかる時間や料金面で効率が良くなります。パーティショニングは、テーブルをパーティションという単位で分割します。時間や日付での分割なども可能で、クエリを投げる前に読み取るデータ量の見積もりが可能です。クラスタリングは、指定した列で並べ替えを行います。複数の列を指定することができますが、指定する順番が重要となります。先に指定した列を使わずに後の列だけで指定しても効果がないため、よく使われる順番で列を指定する必要があります。詳しくは、以下の公式ドキュメントを参照してください。
Google Analyticsのデータの性質と分割の方法
パーティショニングには、今までのコードとの互換性も考慮して、日付を使うこととしました。クラスタリングには基本的にイベント名(event_name)を使用しますが、イベントの内訳を見ると、半数近くがインプレッションに関するものでした。
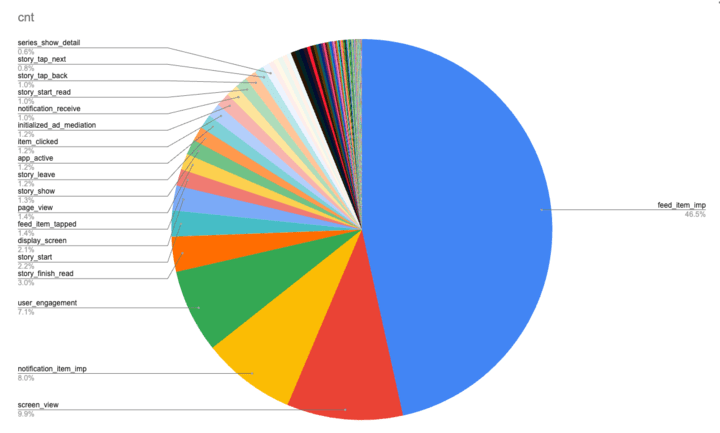
イベントの内訳
インプレッションは、おすすめや検索結果などのように作品のリストを表示したときに、リストの要素一つずつが表示されるたびに発行されるイベントで、非常に多量のデータが生成されます。また、クリックスルーレートなどのインプレッションを使用した解析も多く、その際には削減効果が低いままでした。そのため、インプレッションの内訳を詳しく調べると、表示されている場所に関する情報を使用することで、より絞り込むことができるため、それらに関する列を2つほどクラスタリングに追加しました。
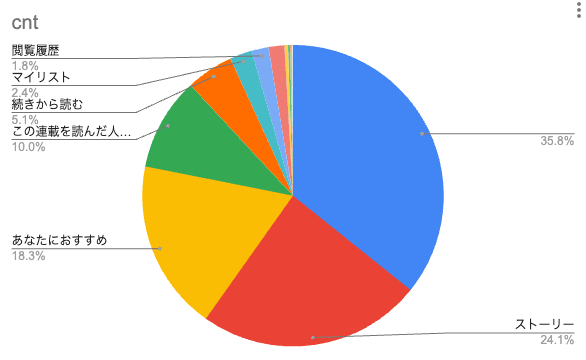
インプレッションの内訳例 (一番多いところは空になっています)
参考のために実際に使っているSQLを残しておきます。
insert into
`${DST_TABLE_ID}`
(
event_date,
event_name,
event_timestamp,
event_previous_timestamp,
event_params,
user_id,
user_pseudo_id,
user_first_touch_timestamp,
user_properties,
app_info,
platform,
section_title,
`from`
)
select
-- event
PARSE_DATE("%Y%m%d", event_date) as event_date,
event_name,
TIMESTAMP_MICROS(event_timestamp) as event_timestamp,
TIMESTAMP_MICROS(event_previous_timestamp) as event_previous_timestamp,
(
select
array_agg(
(
select as struct
ep.key as key,
(
select as struct
ep.value.string_value,
ep.value.int_value,
ep.value.double_value,
) as value
)
)
from unnest(event_params) ep
) as event_params,
-- user
user_id,
user_pseudo_id,
TIMESTAMP_MICROS(user_first_touch_timestamp) as user_first_touch_timestamp,
(
select
array_agg(
(select as struct
up.key as key,
(select as struct
up.value.string_value,
up.value.int_value,
up.value.double_value,
TIMESTAMP_MICROS(up.value.set_timestamp_micros) as set_timestamp,
) as value
)
)
from unnest(user_properties) up
) as user_properties,
-- other
(
select as struct
app_info.id,
app_info.version,
app_info.firebase_app_id,
app_info.install_source,
) as app_info,
platform,
-- クラスタリングのために追加した列。アプリのデータによって変えてください。
(select any_value(ep.value.string_value) from unnest(event_params) ep where ep.key = "section_title") as section_title,
(select any_value(ep.value.string_value) from unnest(event_params) ep where ep.key = "from") as `from`,
from `${PROJECT}.${ANALYTICS_DATASET}.events_*`
where _TABLE_SUFFIX BETWEEN '${START_DATE}' AND '${END_DATE}'
実行方法と移行作業
Cloud Composerを使用して定期的に実行し、event_YYYYMMDDテーブルが作成されるのを待ち、1日に1回実行します。過去の日付範囲を指定して、1年ごとに分けて実行しました。このとき、standard editionにした場合の料金を比較するために試しましたが、計算量が予想外に多く、オンデマンドより高くなってしまったため、結局オンデマンド料金で実行しました。
効率化したクエリの例
クエリは、読み込むテーブルを変更する以外にも、若干の修正が必要です。具体的には、日付リテラルで書くように変える必要があり、できるだけevent_nameなどで絞り込む必要があります。その他の部分については、修正する必要はありません。
select
*
from `${GCP_PROJECT}.${ANALYTICS}.events_YYYYMMDD` between "20230701" and "20230714"
select
*
from `${GCP_PROJECT}.${DATASET}.partitioned_events`
where event_date between "2023-07-01" and "2023-07-14" -- event_dateが日付型になるので日付リテラルで書く
and event_name = "story_start" and `from` = "home" -- 欲しいイベント名だけを指定
インプレッションを使わない解析を行うクエリでは、読み込むデータの90%以上を削減することができました。インプレッションを計算するようなクエリであっても、クラスタリングを活用して更に絞り込むことで、70%以上の削減ができました。
最後に
今まで使っていたクエリをほとんど変えずに効率化し、料金も大幅に下げることができました。この施策を実行するきっかけとなったのは、Looker Studioを使用していたところ、予想外にクエリを何度も実行してしまい、その日の請求額が大幅に増加していたからです。それを受けて、BigQueryのパーティショニングやクラスタリングについて調べ、理解する機会となりました。また、パーティショニングとクラスタリングに関する推奨事項を表示する機能もあるようなので、こちらも試してみたいと思っています。

Discussion