テラーノベルで機械学習を中心に担当している川尻です。最近、グラフニューラルネットワーク(GNN)に注目してサーベイしています。今回は、実際のテラーノベルのデータを簡単なモデルに適用してみたので報告します。
グラフニューラルネットワーク (GNN)
グラフニューラルネットワーク(GNN)とは、グラフ理論において対象を「ノード」と「エッジ」からなる「グラフ」として扱うためのニューラルネットワークの一種です。例えば、テラーノベルにおいては、ノードがユーザーや作品の一つ一つを表し、エッジが「読んだ」「いいね」「フォロー」などを表します。ディープラーニングの発展に伴い、GNNの研究も盛んになっており、大規模なデータや様々なタスクに適用されるようになっています[1]。

テラーノベルでのグラフの例
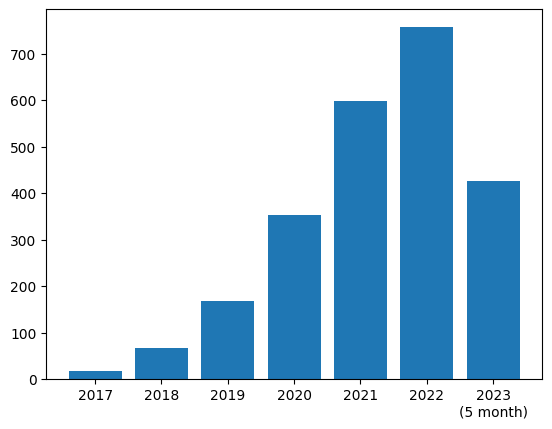
arxivで投稿された年ごとの「Graph Neural Network」がタイトルに含まれている件数
GNNのメリットの一つは、様々な関係や情報を自然な形で埋め込みやすいことです。例えば、汎用的な推薦アルゴリズムでは、通常、ユーザーからのフィードバックは1種類しか使えません。しかし、グラフアルゴリズムでは、エッジの種類を増やすことで、ユーザーとコンテンツの関係で言えば「読んだ」、「いいね」、「フォロー」など、さまざまな種類のフィードバックを利用できます。また、作品へのタグ付けでは、タグの種類が日々増えるため、カテゴリ数や辞書のような形式で表現すると更新が大変ですが、グラフであれば自然な形でノードを追加できます。
問題設定:タグ分類
今回の問題設定は、作品についたタグのクラス分類としました。タグは作品の検索に使えて、さらにタグをフォローするとそのタグの新着や人気の作品を見つけたりしやすくなります。
分類するクラスは「ジャンル」、「二次創作」、「その他」の3つです。「ジャンル」は「恋愛」「ファンタジー」など、「二次創作」は「鬼滅」「ストプリ」などの作品名や関連するワード、「その他」は「雑談」「自己紹介」などの作品としてのタグではないことを表すものです。この分類はサービス上では明示的に出していませんが、一次創作を好むユーザーと二次創作を好むユーザーは傾向が大きく別れていることが分かっているため、データ分析や作品推薦に活用しています。
この問題の難しいところは、タグはユーザーが自由に入力できるため、日々新しいものが生み出されるということがあります。特に二次創作ファン同士だけで通じるような、wrx2、2434、ci、knkz、zmなど、イニシャルで省略されたものも多いです。このような短い文字列からだけで直接推定するのは難しいため、タグをよく使うユーザーや作品との関係性もヒントにグラフとして解くことができるのではないかと思いました。
| クラス | タグの例 |
|---|---|
| ジャンル | BL、ファンタジー、恋愛 |
| 二次創作 | 鬼滅、ストプリ、wrx2、2434 |
| その他 | 雑談、お知らせ、自己紹介 |
実験環境
今回は、DGL というGNNのライブラリを使用しました。DGLはDeep Graph Libraryの略称で、ディープラーニングのフレームワークとして、PyTorchだけでなく、TensorflowやMXNetなども選択できます。また、大規模なネットワークでも比較的高速に処理できるのが特徴です。
開発に使用したマシンのGPUは、NVIDIA GeForce RTX 3090で、メモリサイズはだいたい24GBです。
適用したデータセット
データのノードとエッジの種類と合計の数は以下の通りです。今回は、ノードやエッジには特徴量が含まれておらず、グラフ情報だけになっています。すべてのノードを扱うとデータがあまりにも多く、またどこにもエッジが繋がっていないノードなども含まれるため、過去1ヶ月のデータからアクティブなユーザーや作品、タグに絞り込んでいます。それでもGPUのメモリには収まりきらないので、グラフを分割してミニバッチで学習する必要があります。
| 種類 | 合計 | |
|---|---|---|
| ノード | 3種類(ユーザー、作品、タグ) | 281K |
| エッジ | 5種類(書いた、読んだ、ダグ付、タグフォロー、ユーザーフォロー) | 31M |
学習と評価のための正解クラス情報については、よく使われているタグ上位1,000件に対して、定期的に人力でチェックして分類しているデータを使用しました。分割方法は上位500件を訓練用、次の250件を検証用、次の250件をテスト用としました。機械学習としては難しい設定になりますが、実際の活用場面を考えると上位のタグほど重要であり、コストをかけて人力で割り振ることが多いため、それに即した方法を選びました。
グラフデータを作成するために、DGLのCSVDataset モジュールを活用しています。このモジュールは、ライブラリで規定されている形式でyamlのメタファイルとCSVファイルを作成し、グラフデータとして読み込むことができます。自動でノードのインデックスなどが割り振られるため、簡単に試すことができます。また、一度読み込むとバイナリのキャッシュファイルが保存されるため、2回目以降は高速に読み込むことができます。
実験結果
今回は、DGLのサンプル実装を参考にしました。モデル部分の実装はそのまま使用し、学習部分は上記のテラーノベルのデータセットが使用できるように修正しました。この実装では、R-GCN[2]という多くの種類のエッジを扱う代表的な手法を利用しています。また、グラフ全体がメモリに収まらないような場合に、分割したミニバッチで処理する例にもなっており、今回のデータセットの規模でも簡単に扱えるようになっています。サンプル実装にある他の公開データセットに比べると、まだまだ小さい方です。
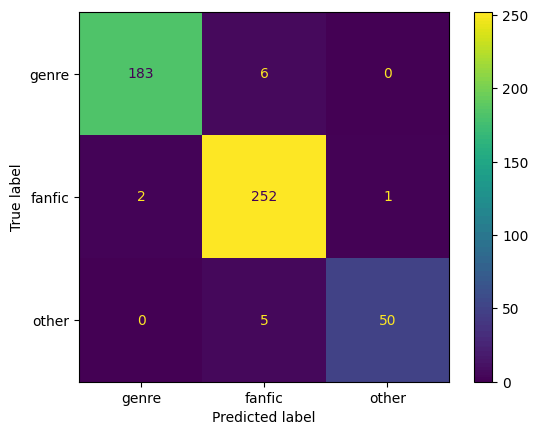
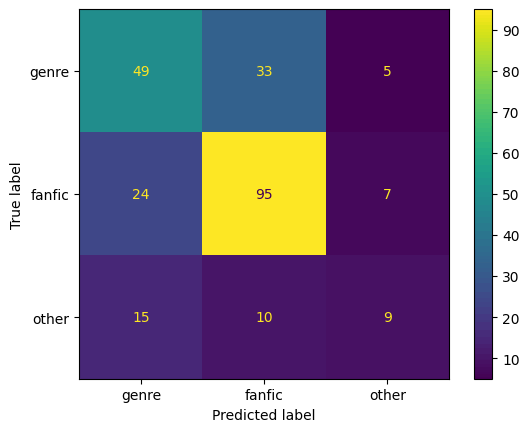
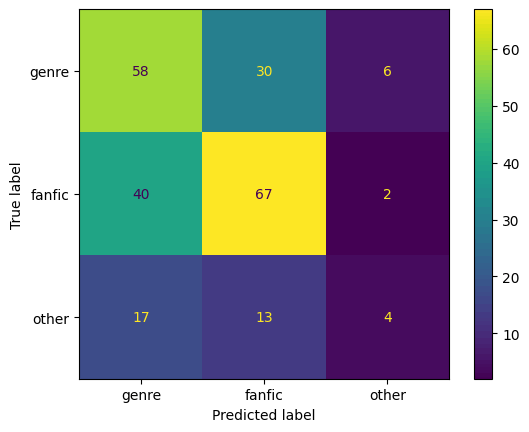
学習とテスト用の推定にかかった時間は約2分で、GPUのメモリの使用量は最大で約14GBでした。精度とConfusion Matrixは以下の通りです。テスト用データでの精度は0.544とまだまだですが、「ジャンル」と「二次創作」のクラスではある程度予想できているようです。一方、「その他」クラスには、いろいろな種類が入っているため、他の2つに比べると推定が難しそうです。
| 訓練データ | 検証データ | テストデータ |
|---|---|---|
| 精度:0.972 | 精度:0.619 | 精度:0.544 |
 |
 |
 |
最後に
オープンなデータセットではなく、実際に自分たちのサービスからデータセットを作成し、学習・評価することで、GNNの手法やライブラリの使い方の理解を深めることができました。まだ実用には十分な精度には至っていませんが、限られたグラフの情報だけでもある程度の傾向は掴めているようです。今後、エッジの種類を増やしたり、作品の情報を特徴量として組み込むことで精度向上の余地があることを期待しています。また、GNNを利用した作品推薦やユーザー推薦など、他の問題設定にも適用してみたいと考えています。
今回はGNNの手法やフレームワークの説明をさらっと流しましたが、このあたりも面白いところなので、今後記事にしていきたいと思っています。

Discussion
素晴らしい記事をありがとうございます。
「実験結果」の精度は accuracy でしょうか? 👀
そうです、accuracyです。