テラーノベルの typer (@tomoemon) です。
今回はDatastoreからSpannerへ移行するにあたっての大詰めの1ステップ、不要になったデータを削除する話です。
関連エントリ:【Cloud Spanner】無停止で安全に漸進的にDatastoreからSpannerへの移行を行う
データベースにおける「10億エンティティ(10億行)」のデータというのは、ペタバイトクラスを扱っている企業の人からすると大したことのないサイズですが、個人や小規模サービスを扱っている人からするとわりと大きいサイズです。
また、データベース製品の特性を理解した上で作業を行わないと、本番環境の別の処理に悪影響を与えてしまったり、思っても見ないほどの長時間の処理が続いてしまうといった問題も起こりうるサイズでもあります。
テラーノベルでは2022年の初頭まではDatastoreをメインのデータベースとしてきましたが、1年かけてSpannerへ移行を進め、ついにストレージ費用削減のためにDatastore側のデータを削除することになりました。ただ消すだけとはいえ、一部のデータに関してはまだ本番環境のサービスがDatastoreを参照していることもあり注意は必要です。
今回は特にサイズの大きい2種類のデータ削除を行いました。
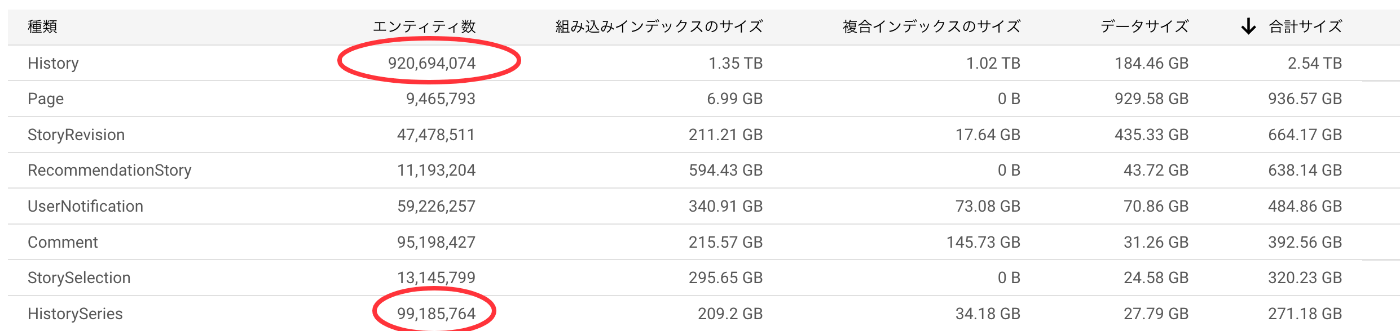
History と HistorySeries が今回削除対象となったKind[1]で、ユーザが読んだ小説の閲覧履歴を表していて両者合わせてちょうど10億エンティティほどあります。2017年のサービス開始以来蓄積されてきた履歴データなので感慨深いものがあります。
PostgresSQLやMySQL等のRDB製品との違い
DROP TABLE History;
このセクションは、「10億件と言っても上記のようなコマンド一発でデータを消せるんでしょ?」と思った方向けの解説です。
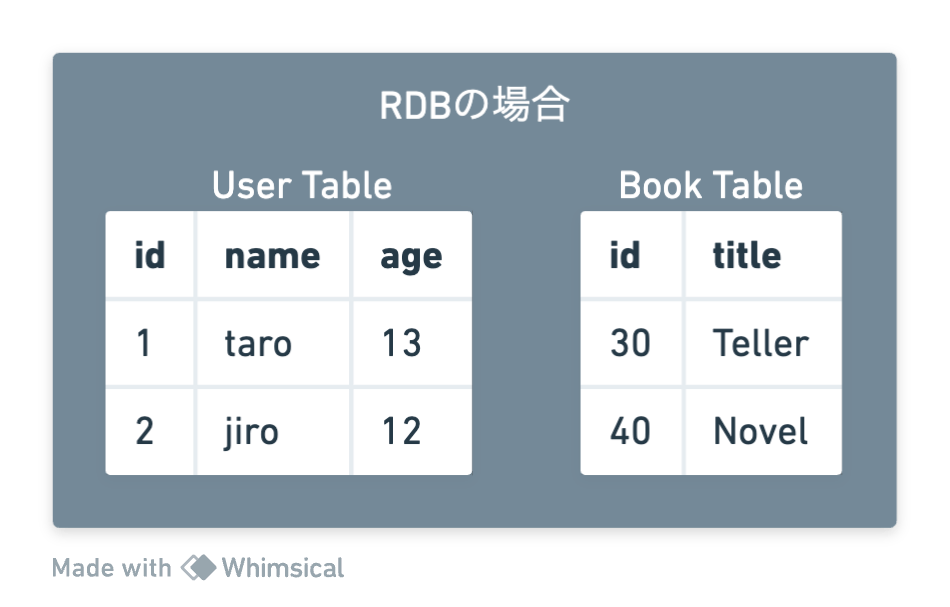
下図のように、RDB製品はテーブル単位で論理的に分かれており、ファイルシステム上でも一般的に異なるファイルとして保存されています。そのため、特定のテーブルを削除したいという要求は、基本的にはファイルを削除することで完了します。
一方で、Datastoreには「テーブル」という概念はありません。すべてのデータが等しくエンティティ(Entity)で、Kindという特別なプロパティに名前を保存することで、その種類を管理しています。特定のKindを指定してエンティティを取得することはできるものの、削除しようとする場合は、対象となるエンティティのKeyを指定する必要があります。
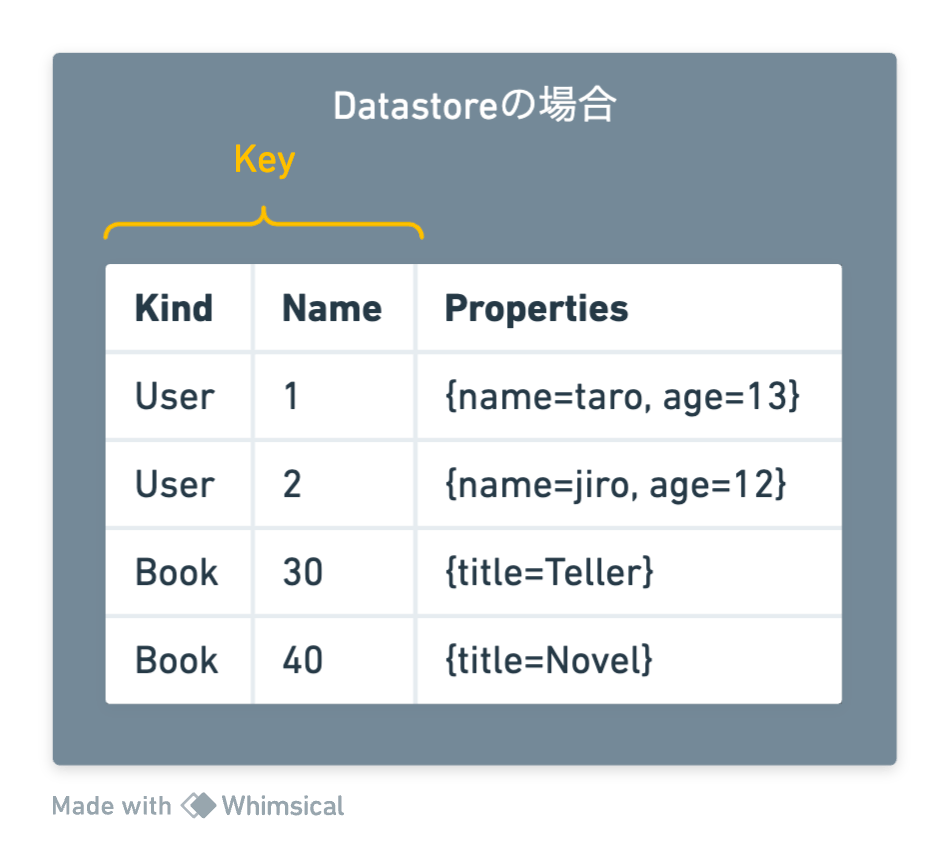
大量のデータを消す場合でも、少量のデータを消す場合でも同じです。
- 削除対象のエンティティのKeyを取得して
- Keyを指定してDelete APIを呼び出す
これだけです。シンプルなスクリプトを作れば直列にじわじわと消していくことができますが、10億エンティティとなると毎秒1000件消しても280時間近くかかるため、短時間で終わらせるためには別の方法を考える必要があります。
Dataflow による並列削除
Datastoreそのものに一括削除のための便利機能は用意されていませんが、Dataflowを活用して「エンティティの取得処理」「エンティティの削除処理」を並列化して短時間で終わらせることは可能です。
Dataflowは「Apache Beam等の並列処理フレームワークを用いて作られたプログラムの実行環境」で、2023年8月現在、最大で1000台のワーカーインスタンスを自動的に立ち上げて並列処理を動かすことができます。[2]
Apache Beamを使ってデータ操作を並列実行できるようなプログラムを自前で用意することもさほど難しくはありませんが、削除に関してはGoogle Cloudがあらかじめ用意してくれているので、これを使うと手っ取り早いです。
Firestore Bulk Delete テンプレート
Firestore Bulk Deleteテンプレートは、指定のGQLクエリを使用してFirestoreからエンティティを読み込み、選択したターゲットプロジェクト内のすべての一致エンティティを削除するパイプラインです。
gcloud コマンドを使って次のように実行します。firestoreReadGqlQuery にGQLという専用クエリを記述してデータを絞り込みます。今回はHistory Kind全体を指定していますが、WHEREでより詳細な絞り込みを行なうこともできます。
gcloud --project $PROJECT_ID dataflow jobs run delete_datastore_History \
--gcs-location gs://dataflow-templates/latest/Firestore_to_Firestore_Delete \
--region asia-northeast1 \
--parameters \
firestoreReadGqlQuery="SELECT __key__ FROM History",\
firestoreReadNamespace="",\
firestoreReadProjectId="$PROJECT_ID",\
firestoreDeleteProjectId="$PROJECT_ID"
実行開始するとDataflowのジョブ一覧からパイプラインの状態を見ることができます。

インスタンス数は30分程度で1000台に到達し、
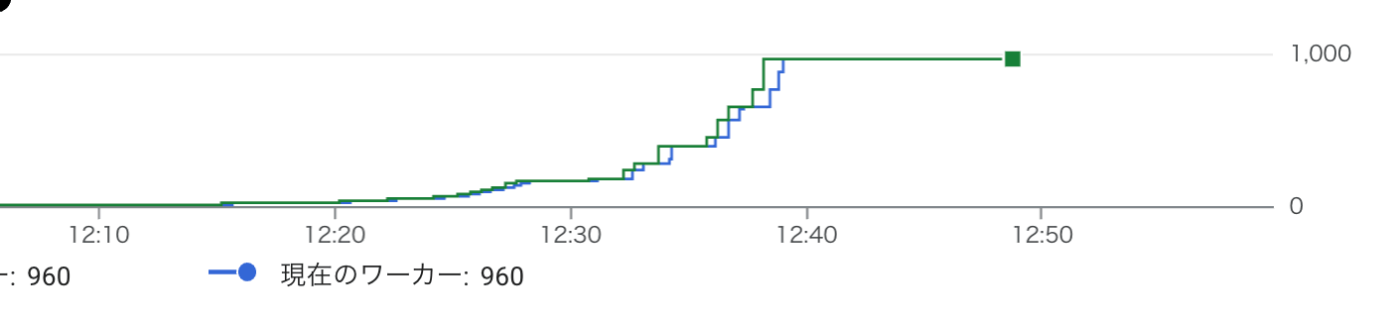
スループットはピーク時に秒間60万件まで達しています。
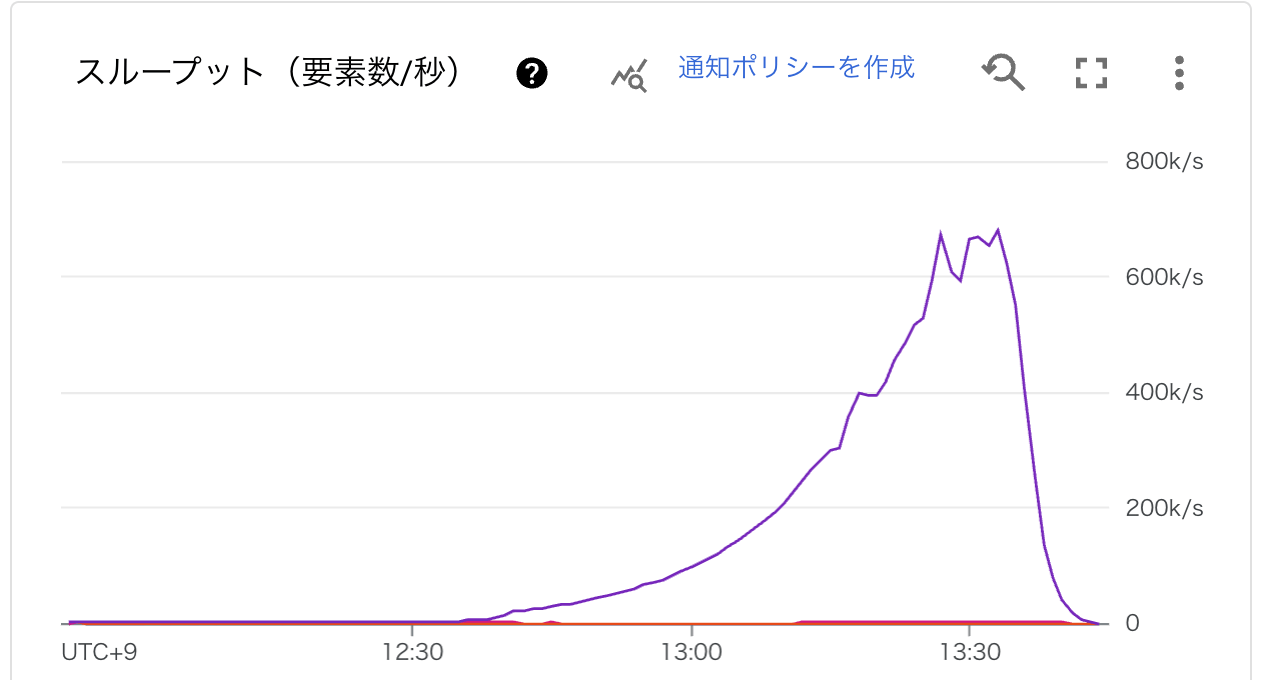
Dataflowはスケールアウトし始めるまでに20〜30分程度時間がかかるのですが、それも込みで1時間50分程で削除が完了しました。
他のサービスによるDatastoreアクセスへの影響
データ取得と削除する処理がスケールしても、DB側がスケールしなくてはあっという間にパンクしてしまいます。実際、Spannerのように処理できる容量を事前に指定しておくタイプのものだと、Dataflowのスケールアウトに耐えきれずにDB側がボトルネックになることがあります。
その点、Datastoreに関してはアクセス数の増加に応じて自動的にスケールしてくれるため、次のようなベストプラクティスを守る限りにおいては、Dataflowと組み合わせても心配すべきことが少なくて済みます。
(Datastoreベストプラクティス トラフィックを徐々に増やす)[https://cloud.google.com/datastore/docs/best-practices?hl=ja#ramping_up_traffic]
オペレーションは毎秒500回を上限とし、その後5分に50%ずつトラフィックを増やしていくことをおすすめします。理論上は、(略)90分後に毎秒740,000回までオペレーションを増やすことができます。(略)GoogleのSRE は、これを「500/50/5」ルールと呼んでいます。
実際、Dataflowを使った削除処理を実行している最中に、関連サービスのAPIのレイテンシやエラーレートを確認していましたが、どちらもまったく増加することなく、何事もなく処理を終えることができました。
まとめ
- Dataflowを使って1時間50分でDatastoreから10億エンティティを削除した
- Datastore側のスケールは気にすることもなく本番環境に影響が出ることはなかった
おまけ:ダッシュボードは壊れた
本番環境の関連サービスに影響を与えることはなかったものの、10億件のデータ削除が完了する時刻の前後くらいから、本番環境のDatastoreダッシュボードの表示がおかしくなりました。
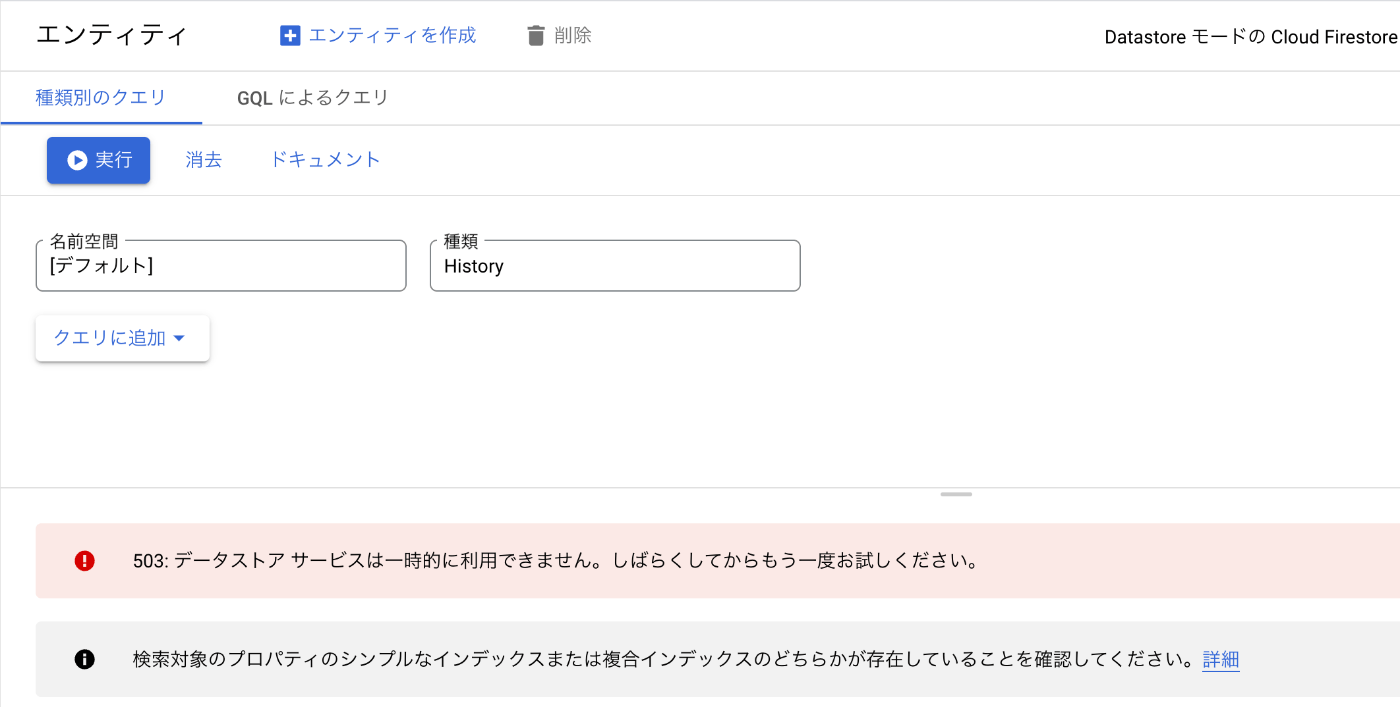
データストアサービスが一時的に利用できません。という極めて心臓に悪いメッセージなのですが、実際のところはプログラム経由で呼び出すDatastore APIが死んでいたこともなく、ダッシュボードを表示するときにだけこのエラーメッセージが表示されていました。
通常であれば、History以外のKind一覧が候補に現れて選択できるはずのフォームにも何も表示されなくなり、「すべてのデータが消えてしまったのか?」 という不安を煽りまくります。

おそらくですが、Datastoreのダッシュボード画面に表示する統計情報を管理するためのサービスがパンクしていたのではないかと思います。Datastoreのダッシュボードは常に最新の情報を表示しているわけではなく、Kindの一覧やKindごとのエンティティ数等は定期的に実行される統計処理によって「24時間程度遅れた内容」が表示されています。
大量のデータを一気に消したことで統計処理を司るサービスの負荷が高まりダッシュボードの表示だけがエラーになったのではないかと推察していますが、とにかく心臓に悪いのでどうにかして欲しいですね。
-
RDB製品におけるテーブルに近い概念だが、実体は大きく異なり、各エンティティに付けられたラベル名のようなもの ↩︎
-
Dataflowの割当と上限: https://cloud.google.com/dataflow/quotas?hl=ja ↩︎

Discussion