テラーノベルで機械学習を中心に担当している川尻です。みなさんも大量のデータを特徴抽出してみたけど、どう使ったらいいかわからないなぁということありますよね。とりあえずどういうデータなのか雰囲気だけでもみるために、簡単な可視化から入るかと思います。以前にもグラフデータの可視化について記事を書きました。
テラーノベルでは小説投稿アプリを作っており、OpenAI Embedding APIを使って全作品の特徴量を出しているデータベースがあります。今回はこのデータを例にして、UMAPという可視化に便利な次元削減手法の使い方を紹介します。
UMAPとは
UMAPというのは非線形の次元削減手法で、特徴は次元数やデータ量に対してほとんど一定の計算時間で済むということです。LLMなどの事前学習モデルでよく扱うような1,000次元を超えるような特徴量でも全く問題なく動きます。さらに、Pythonでとても使いやすいパッケージが公開されています。
UMAPの仕組みなどの解説はこちらの記事が分かりやすくまとまっています。
実行環境とデータの内容
ここからは、google colabを使う前提で進めます。事前に以下のようにumapをインストールしておきます。
!pip install umap-learn
以下のように必要なパッケージをインポートしておきます。
import matplotlib.pyplot as plt
import umap
今回は、BigQueryからpandasのDataFrameの形式で取得して以下のように取得できているとします。
from google.colab import auth
auth.authenticate_user()
%%bigquery features --use_bqstorage_api
select
... 省略 ...

特徴抽出には、Open AI Embedding APIを使っていて次元数は1536です。UMAPの計算時間は、体感的にはデータサイズに比例します(理論的には計算量は線形よりも若干大きいオーダーです)。今回は試行錯誤もするために1回の次元削減の計算が30秒位で終わるようにレコード数を間引いてあります。もし計算時間を待つことができればメモリーサイズの限界まで増やすことができて、今回使った標準のgoogle colab(RAM=12.7GB)では、10万件では3,4分で計算が完了しましたが、20万件ではRAM不足でできませんでした。また、可視化で一緒に表示するためにジャンル情報(Genre)と公式/インディーズ情報(IsOfficial)のカラムを一緒に取得しています。ジャンル情報について、公式作品については人手である程度チェックして精度が高いですが、インディーズ作品はほとんどが自動判定であるため精度が低いです。それぞれの内訳は以下のようになっています。
features["IsOfficial"].value_counts()
False 20366
True 7113
Name: IsOfficial, dtype: Int64
features["Genre"].value_counts()
horror_thriller 9227
romance 5845
bl 5684
fantasy 2513
comedy 1523
drama 1366
unspecified 882
romance_fantasy 439
Name: Genre, dtype: int64
とりあえずUMAPで可視化
次元削減するコードは以下のようになります。
%%time
u = umap.UMAP(metric="cosine").fit_transform(features["Feature"].to_list())
CPU times: user 51.8 s, sys: 1 s, total: 52.8 s
Wall time: 38.5 s
u は二次元に変化されたデータが入っています。OpenAIのドキュメント [1] によるとコサイン距離が推奨されているので、メトリックを指定しています。
以下のようにジャンルごとに色を分けて可視化してみます。
for i, genre in enumerate(genres):
idx = features["Genre"] == genre
plt.scatter(u[idx, 0], u[idx, 1], label=genre, s=0.5, alpha=0.5)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
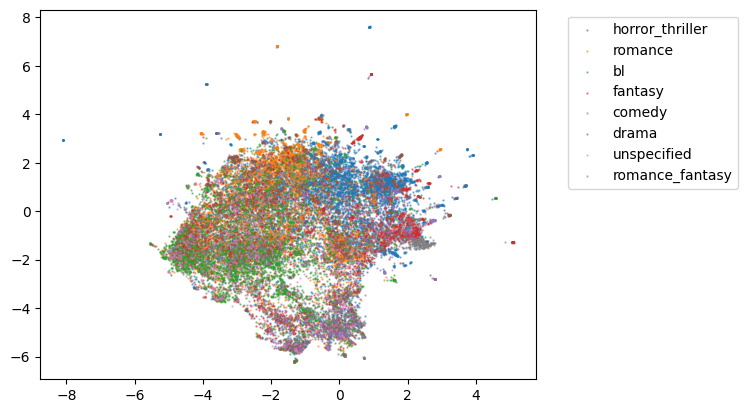
ジャンルごとに大まかには固まっていそうですが、ジャンルが入り乱れているところや、外れている値も結構ありそうですね。
続いて、公式/インディーズで色を付けてみます。
idx = (features["IsOfficial"] == False).to_list()
plt.scatter(u[idx, 0], u[idx, 1], label="Indies", s=0.5, alpha=0.5)
idx = (features["IsOfficial"] == True).to_list()
plt.scatter(u[idx, 0], u[idx, 1], label="Official", s=0.5, alpha=0.5)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
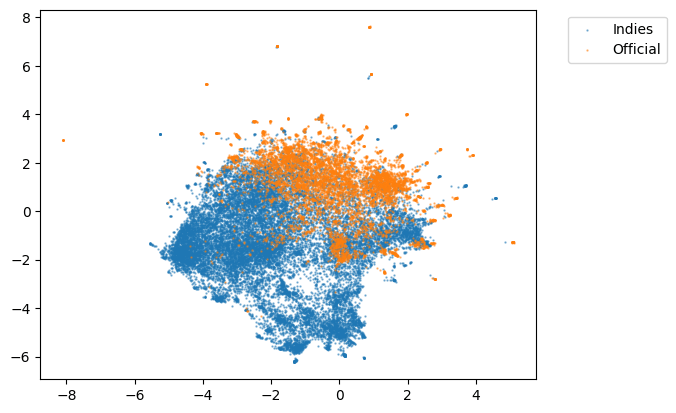
こちらのほうがよりはっきりと分かれそうで、公式作品のようなインディーズ作品を判定する事もできそうです。
教師ありUMAP
UMAPは教師ありUMAPも対応していて、同じラベルが付いたものは近くになるように次元削減します。以下のようにラベルを整数に変換して渡します。
%%time
s = umap.UMAP(metric="cosine").fit_transform(features["Feature"].to_list(), features["Genre"].map(lambda x: genres.index(x)).to_list())
CPU times: user 49.8 s, sys: 2.43 s, total: 52.3 s
Wall time: 34.7 s
for i, genre in enumerate(genres):
idx = features["Genre"] == genre
plt.scatter(s[idx, 0], s[idx, 1], label=genre, s=0.5, alpha=0.5)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
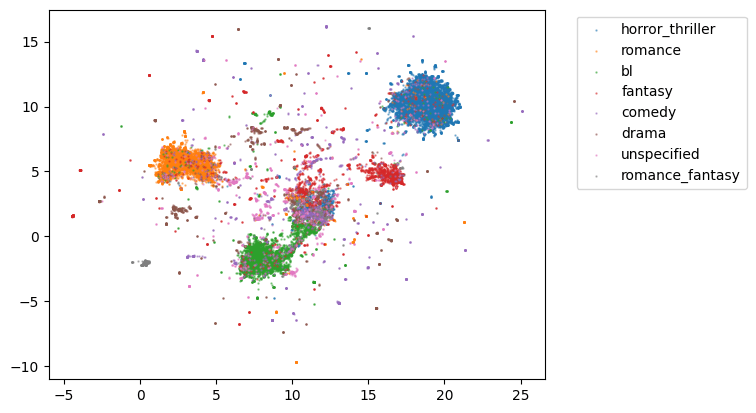
先程と比べると、はっきりとジャンルごとに分かれるようになりました。特にデータ量が多いジャンルではしっかり集まっていて判定しやすそうですが、データが少ないジャンルでは他のジャンルと混ざっていて推定するのが難しそうです。
準教師ありUMAP
実際のデータでは全部のデータについて欲しい情報がついていることはあまりなく、しっかりと判定モデルを作成する前にどれくらい判定できそうかのあたりを付けたいことが多いかと思います。つづいては、準教師ありUMAPでこれをやってみます。
すでに説明したように、インディーズ作品のジャンルは作成した判定モデルで自動分類したものです。判定モデルを作成する際には、公式作品についてだけ人手でつけたジャンルを教師データとして使いました。そのため以下のように、公式作品のデータだけラベル情報として与えて、インディーズ作品はラベルなしとして処理される、-1をつけます。
%%time
features["Label"] = -1 # ラベルなしは -1
official_idx = (features["IsOfficial"] == True).to_list()
features["Label"][official_idx] = features["Genre"][official_idx].map(lambda x: -1 if x == "unspecified" else genres.index(x)) # unspecifiedも判定できなかったものなのでラベルなしに
ss = umap.UMAP(metric="cosine").fit_transform(features["Feature"].to_list(), features["Label"].to_list())
CPU times: user 1min, sys: 1.58 s, total: 1min 2s
Wall time: 39 s
ラベルなしデータはグレーにして、可視化してみます。
unlabeled_idx = (features["Label"] == -1).to_list()
plt.scatter(ss[unlabeled_idx, 0], ss[unlabeled_idx, 1], label="unknown", s=0.5, c="gray", alpha=0.1)
labeled_idx = (features["Label"] != -1).to_list()
for genre in genres:
idx = features[labeled_idx]["Genre"] == genre
plt.scatter(ss[labeled_idx][idx, 0], ss[labeled_idx][idx, 1], label=genre, s=0.5, alpha=0.5)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')

こちらをみてもやはり、データが多いジャンルではうまく分離できそうなことが見て取れますね。一方で、ラベルなしのインディーズ作品だけがまとまっているところもあるので、インディーズ特有のジャンルがあったりしそうです。必要に応じて、クラスタリングなどして作品を抜き出して、定性的に確認していくといいかもしれないです。
まとめ
可視化のための次元削減の手法としてUMAPを紹介して、実際にざっくりした分析をしてみました。ここまでの説明でお気づきの方もいるかと思いますが、UMAPの次元削減は可視化だけではなくて、メトリック学習やクラスタリング、異常値検知などにも応用できます。UMAPの公式ドキュメントにも分かりやすく説明が書いてあるのでぜひ見てみてください。
-
embedding APIの説明: https://platform.openai.com/docs/guides/embeddings/limitations-risks ↩︎

Discussion