はじめに
こんにちは! テラーノベルでサーバーサイドを担当している@yuhasです。
Cloud Spannerの特定テーブルに対するデータ更新を継続的に監視したいことがあると思います。そのときにSpanner Change Streamsを経由してBigQueryから扱うことをしました。これについてまとめたいと思います。
モチベーション
検索サービス(マイクロサービス的な観点からいうサービス)を開発しており、Cloud Spannerのテーブルに対して行われた更新を定期的に検索サービスに反映させる必要がありました。これを行うためにSpanner Change Streamsを検討していました。Spanner Change Streamsは、一言でいえば、Spanner上のデータの更新・挿入・削除をStreamとして流してくれるサービスです。それをSubscribeしたりBigQueryに流したりして使おうというわけです。
検討
Change Streams以外の方法
Cloud Spannerの特定テーブルに対するデータ更新を検知して扱いたいとき、Change Streamsを使う以外の方法もあるでしょう。たとえば、そのテーブルの更新日時UpdatedAtカラムがあれば、それが特定日時以降であるレコードを抽出するクエリを定期的に実行することで、どういう更新が行われたのか確認することができます。
その方法をとると
- Spannerに対して直接クエリを叩くので、データ更新を利用したいサービスが増えれば増えるほどSpannerに対する負荷が高まってしまう
- UpdatedAtカラムにインデックスが必要
- クエリの定期的な実行の1インターバルで複数の更新があった場合にそれを別々の更新として処理することはできない
- レコードの物理削除を検知することができない
といったことを考慮することになります。
今回、検索サービス以外でも使うという事情もありまして、Change Streamsを使うことにしました。
Change Streamsをどう扱うか
上記の公式ドキュメントにもありますが、おもに
- 公式のdataflowテンプレートを利用する
- BigQueryに保存する
- Cloud Pub/Subから利用する
- Cloud Storageに保存する
- 直接APIを叩く
といった方法でChange Streamsを扱うことができます。今回、あまりここに対して開発工数をかけたくなかったので、公式のdataflowテンプレートを利用することにしました。
また、BigQueryに保存することで、
- どんなデータがChange Streamsから来たのかについてブラックボックス感がない
- 今までBigQueryに保存してきたデータと結合してデータ分析やデータ加工がしやすい
といったメリットがあり、BigQueryに保存することにしました。
実際にやってみる
Change Streamsを作成する
公式に書いてありますが、以下ようなDDLを実行することで作成できます。
CREATE CHANGE STREAM HogeStream
FOR FugaTable, PiyoTable;
dataflowを起動する
公式にgcloudコマンドの使い方が書いてありますので、利用します。上で作成したChange Streamsと、BigQueryの保存先を指定する感じになります。
BigQueryのテーブルは、元になるSpannerのテーブル定義をもとに、自動で作成されます。FugaTable_changelog、PiyoTable_changelogのような名前になります。
dataflowによって、指定したテーブルに対する変更クエリが検知されてBigQueryのテーブルに保存されるようになります。
データを利用する
どういうデータが取れるのか
Spannerの当該テーブル(FugaTable)に以下のカラムを追加したテーブル(FugaTable_changelog)がBigQueryに作られます。
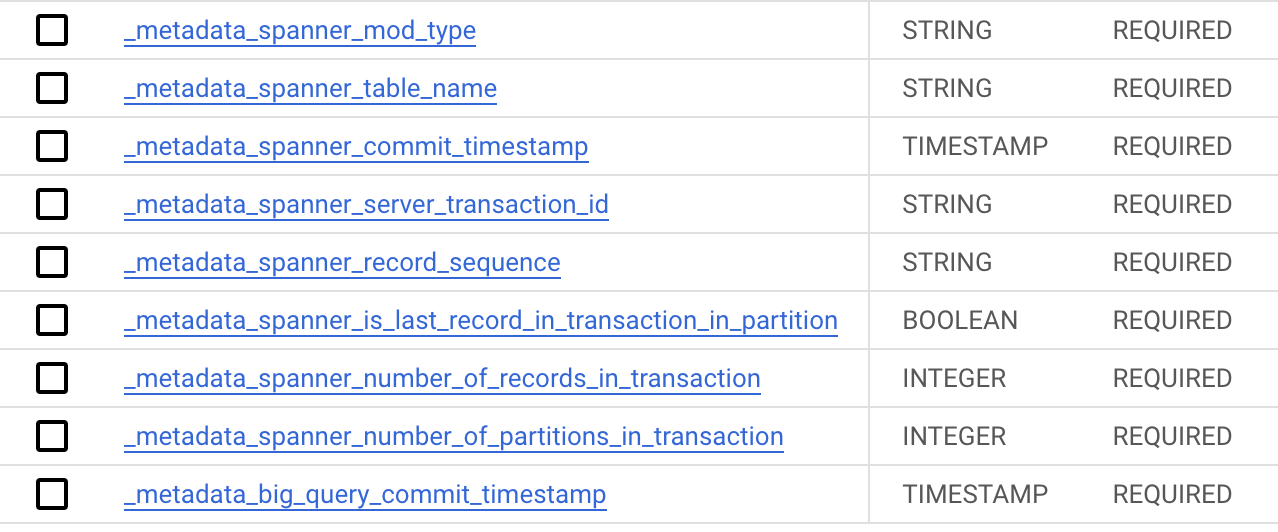
元々のカラムの他に、特にこの辺りのカラムが使われそうです。
-
_metadata_spanner_mod_type- INSERT, UPDATE, DELETE
-
_metadata_big_query_commit_timestamp- BigQueryにレコードを挿入するときのコミットタイムスタンプ
これらを利用して、Spannerでのデータ更新を検知してなんらかの処理をさせることができます。
コストカットについて(パーティション分割テーブルの利用)
BigQueryを使うとき、そのコストを考えなければいけません。
まず、SELECT文で選択するカラムの数を少なくするのはそうですが、SELECT文で選択する対象を小さくすることが有効です。今回のようなユースケース(更新されたデータを検知してなんらかの処理をしていく)の場合、_metadata_big_query_commit_timestampによるパーティション分割テーブルを利用するのが良さそうです。パーティション分割テーブルというのは、特定のソート可能なカラムによって分割したテーブルのことです。分割したテーブルに対してクエリを投げることでデータ処理量を減らしてコストを減らすことができます。
dataflowが自動で生成してくれたテーブル(FugaTable_changelog)ですが、dataflowを経由せずに手動でスキーマを変更したり、パーティション分割テーブルにしても問題ありません。
パーティション分割テーブルにするための手順ですが、パーティション分割はテーブル作成時に定義するものであるため、同一スキーマでパーティション分割を設定した別テーブルを作って、そこにデータを移す必要があります。
それでは具体的な手順を説明します。
まず、データを損失させないため、dataflowのジョブを(一時的に)停止します。ここで停止した時刻を覚えておきましょう。
コンソール画面から実行するのが一番簡単です。
その際、ドレイン(新規のデータ取り込み停止)→停止(ジョブの停止)という順番で停止します。
バグかわかりませんが、表示上でドレイン中のステータスがずっと終わらないことがあるので、確かに取り込むべきデータがBigQueryに保存されていることを確認したら、停止してしまって良いでしょう。
次に、新しいテーブルを作るために古いテーブルのスキーマを確認します。
SELECT
table_name, ddl
FROM
INFORMATION_SCHEMA.TABLES --ここはBigQueryのデータセット名.INFORMATION_SCHEMA.TABLESという形で書きます
WHERE
table_name = 'Fuga_changelog';
それをもとに新しいテーブルを作ります。
CREATE TABLE `Fuga_changelog_new`
(
-- 省略
_metadata_spanner_mod_type STRING NOT NULL,
_metadata_spanner_table_name STRING NOT NULL,
_metadata_spanner_commit_timestamp TIMESTAMP NOT NULL,
_metadata_spanner_server_transaction_id STRING NOT NULL,
_metadata_spanner_record_sequence STRING NOT NULL,
_metadata_spanner_is_last_record_in_transaction_in_partition BOOL NOT NULL,
_metadata_spanner_number_of_records_in_transaction INT64 NOT NULL,
_metadata_spanner_number_of_partitions_in_transaction INT64 NOT NULL,
_metadata_big_query_commit_timestamp TIMESTAMP NOT NULL
)
PARTITION BY DATE(_metadata_big_query_commit_timestamp) -- これを追加した
OPTIONS(
description="BigQuery changelog table."
);
データを移します。
INSERT INTO `Fuga_changelog_new`
SELECT * FROM `Fuga_changelog`
名前を変えます。
DROP TABLE `Fuga_changelog`
ALTER TABLE `Fuga_changelog_new` RENAME TO Fuga_changelog;
最後に、停止したジョブを再開します。こちらと同様のコマンドを実行します。
#dataflowを起動する
ただし、追加でstartTimestampパラメータを指定し、先ほどの停止時刻より少し前を指定しましょう。そうすることで、停止していたときにChange Streamsで扱っていたデータもBigQueryのテーブルに入ります。
おわりに
Spanner Change StreamsをdataflowでBigQueryに送り、BigQueryから利用する方法についてご紹介しました。
他にも、Spanner側のスキーマ変更をした際にBigQuery側にどう反映するかをうまく行う方法など考えなければいけませんが、方法はありつつもなかなか苦心しているところなので、上手い方法が見つかればまた記事をかけたらと思います。

Discussion