テラーノベルで機械学習を中心に担当している川尻です。
テラーノベルでは、定期バッチ処理は主にBigQueryかDataflowを組み合わせて実行しています。データはBigQueryのテーブルにほとんど保存されているため、基本的にはBigQueryで完結させたいです。しかし、自作した機械学習モデルは前処理も含めてpythonで書く必要があるため、そこだけDataflowを使っていました。最近、BigQueryリモート関数を使ってみたところ、意外と簡単にBigQueryだけでシンプルに完結させることができました。今回は、機械学習モデルをBigQueryから実行したときのちょっとしたハマりどころや、実際にどれくらいコストや処理時間がかかったのか紹介します。
BigQueryリモート関数とは
BigQueryリモート関数は、好きな言語やフレームワークでCloud FunctionsやCloud RunをBigQuery SQLの関数として呼び出すことができる仕組みです。今回のように機械学習であれば、よく使われるPythonを言語として使って、PyTorchやTensorFlowなどのライブラリを呼び出すことができます。
バッチ処理を自分で書いたりDataflowなどのワークフローツールと比べたときのメリットは、
- 処理の分割やスケール、リトライなどはBigQueryとCloud Runが連携してやってくれる。
- 一度、リモート関数としてデプロイしてしまえば再利用性が高くて、簡単に扱える。
などが挙げられます。
デメリットがあるとしたら、簡単に使える分、間違って呼び出しすぎて予想以上に料金がかかってしまうことがあるかと思います。Cloud Runのスケールに関するパラメータを調整しておいて、確認しながら実行するなどが必要かもしれません。
BigQueryで機械学習モデルを実行したいというだけであれば、BigQuery MLの機能でTensorFlowやPyTorchのモデルを関数として呼び出すことが可能です。しかし、自然言語処理では分かち書きやパディングなどの前処理が発生するため、onnxだけで完結できずpythonコードを実行する必要があります。
呼び出す先はCloud Functionsではなく、Cloud Runを使うことにしました。社内的にCloud Runをよく使っているという特有の事情があることと、Cloud RunであればFastAPIのような慣れたフレームワーク使ってローカルでの開発やテストができるという理由からです。
実際にやってみた
今回は、文章を2値分類するモデルを実行します。リモート関数内で行われる処理内容はおもに以下の2つです。
- 分かち書きやパディングなどの前処理
- pytorchの軽量なモデルを実行
- ファイルサイズで46MB
実装やデプロイの詳細は各公式ドキュメントが詳しく、テックブログなどもすでにたくさん出ているためここでは省略します。
-
FastAPIのDockerイメージの作り方
https://fastapi.tiangolo.com/ja/deployment/docker/ -
Cloud Runのデプロイ方法
https://cloud.google.com/run/docs/deploying?hl=ja#service -
BigQueryリモート関数の作成
https://cloud.google.com/bigquery/docs/remote-functions?hl=ja#create_a_remote_function
主要な設定値
特に以下のパラメータの調整が少し難しかったです。
Cloud Run
- CPU: 1
- メモリー: 2GiB
- 最大同時リクエスト数:64
BigQueryリモート関数
- バッチ最大量(
max_branching_rows): 4096
バッチ最大量や最大同時リクエスト数が増えるとインスタンスあたりのメモリ消費が超えて、Cloud RunからはHTTPレスポンスコード500返ります。そうするとBigQueryからは何度もリトライされてしまうため、BigQueryのコンソールからキャンセルします。実際に使うデータを量を少しずつ増やしながら、エラーが出ないパラメータを探索しました。
バッチ最大量を再設定する場合は、以下のように CREATE OR REPLACEで可能です。
CREATE OR REPLACE FUNCTION `PROJECT.DATASET.FUNCTION`(content STRING) RETURNS FLOAT64
REMOTE WITH CONNECTION `CONNECTION`
OPTIONS (
endpoint = 'https://your-endpoint-uc.a.run.app',
max_batching_rows =16 * 256 -- バッチの最大量
)
結果
テラーノベル内にある全小説に対して判定処理を行いました。投入したデータのスペックは以下のようになっています。
- 総話数:620万話
- 総文字数: 64億文字
Cloud Runのインスタンスが立ち上がっていない状態から、BigQueryを実行して4分前後で終わりました。BigQueryコンソールの結果では、BigQueryでの課金対象しか見れません、Cloud Runのモニタリングを見ると課金対象の時間が確認できます。インスタンスに設定したCPUとメモリーと合わせて概算すると70円程度でした。
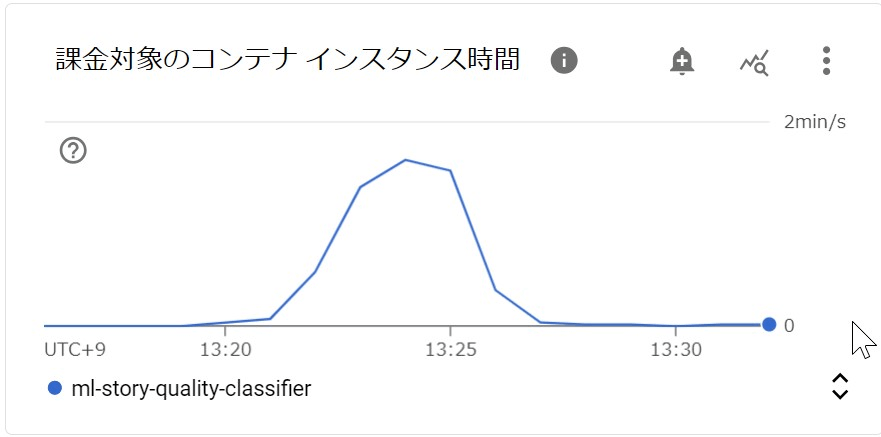
また、実際に掛かった金額をコンソールのレポートで見ると、テストで何回か動かしたもの含まれますが、Cloud Runでかかった料金は約100円でした。
まとめ
期待していたよりも実行速度はずっと速く、料金もかなり安かったです。すでに社内で実装されている機械学習モデルもBigQueryリモート関数として置き換えていくことを検討しています。
BigQueryは次々と新しい機能が実装されているので常にチェックしています。現在注目しているのは、BigQuery DataframesというBigQueryに対してをPandasやscikit-learnのように扱えるPython APIです。それを使うと以下のように通常のpythonでデコレーターをつけるだけで簡単にリモート関数が使えてます。Cloud FunctionsのデプロイからBigQueryやIAMの設定まで自動でやってくれちゃいます。この方法で機械学習のモデルを動かせるか試してみるという記事をまた別の機会に書こうと思います。
@bpd.remote_function(
[float], str, bigquery_connection="bigframes-rf-conn", reuse=False
)
def get_bucket(num):
if not num:
return "NA"
boundary = 4000
return "at_or_above_4000" if num >= boundary else "below_4000"

Discussion