こんにちは。Google Cloudの製品名を伝えるときに、どれに "Cloud" を付けて、どれに付けないのか未だに全然わかっていない typer です。
"バッチ処理"[1] 関連サービスが多くてよくわからない問題
テラーノベルでは定期実行したいジョブの実行環境として Cloud Composer を使用しています。Datastore のデータを BigQuery にエクスポートしたり、BigQuery に蓄積されたユーザ行動イベントを集計したり、ランキングを生成したり、機械学習の処理を走らせたり、といった、主に1時間おき、1日おきに実行するジョブを動かしています。
Cloud Composer は Python ファイルに下記の内容をすべて記述します。非常に柔軟性が高く、1個体ですべてが完結しているようなサービスです。
- タスク(実行したい処理)の定義
- タスク間の依存関係(実行順序)
- 定期実行スケジュール
- 実行環境のプロビジョニング
Python のコードを見ればすべてが集約されているという意味ではわかりやすいものの、一方で様々な概念を包括しているため、習熟するまでにかなりの罠を踏み抜かなければいけないサービスでもあります。
Google Cloud では、それとは対照的に上記の機能を個別のサービス群としても提供しています。
- タスク(実行したい処理)
- Container Image を作成して Artifact Registry に登録
- タスク間の依存関係(実行順序)
- 定期実行スケジュール
- 実行環境のプロビジョニング
1つ1つのサービスが提供する範囲は限定的で、基本的には他のサービスの責務に立ち入らないようになっています。それがわかりやすくもあり、面倒なところでもあって、簡単なタスクを1つ定期実行したい場合でも、各種サービスを組み合わせて使う必要があります。
どんなときに何を使うべきなのでしょうか?
バッチ処理の分類
そもそも、実行したいバッチ処理の内容によって適切なサービスは変わってきます。
特に、「同種なタスクの集合」なのか「異なるタスクの集合」なのかは大きなポイントです。
- 同種のタスク:Google Cloud Storage に置いてある100万個のファイルのハッシュ値を生成する類のもの、それぞれのタスクが独立して並列実行できる場合が多い
- 異なるタスク:データを Datastore から Google Cloud Storage にエクスポートして、それを BigQuery に取り込んで、BigQuery 上で SQL を実行して、その結果を分析ツールに入れて〜といった異なる処理を順番に実行していく類のもの
同種のタスクを実行したい場合は、タスク間の依存関係を考慮する必要がないので、Workflows のような仕組みは不要で、容易にスケールするような実行環境を選ぶことが重要です。冒頭のサービス一覧には載せていませんが、Dataflow は処理件数や負荷に応じて、水平スケーリング・垂直スケーリングをサポートしているのでおすすめです。
異なるタスクを実行したい場合は、タスクに依存関係がなければそれぞれ単独で起動するだけで良いですが、依存関係がある場合はそれを Workflows のようなサービスで制御する必要があります。順次実行する異なるタスクの中に、「同種のタスクの集合」が現れることもあるため、両者を組み合わせる場面も多々あります。
Cloud Run Jobs の組み合わせ例
Cloud Run Jobs は2022年5月にプレビューとして登場したサービスで、これまでは基本的に HTTP リクエストベースで処理を起動していた Cloud Run 上でバッチ処理を実行できるようになりました。
下図は Cloud Run Jobs と Workflows や Cloud Scheduler を組み合わせて、動かすイメージ図です。今回はタスク間に依存関係がある場合で、かつ定期実行したい、という場面を想定しているので、この2つと組み合わせています。
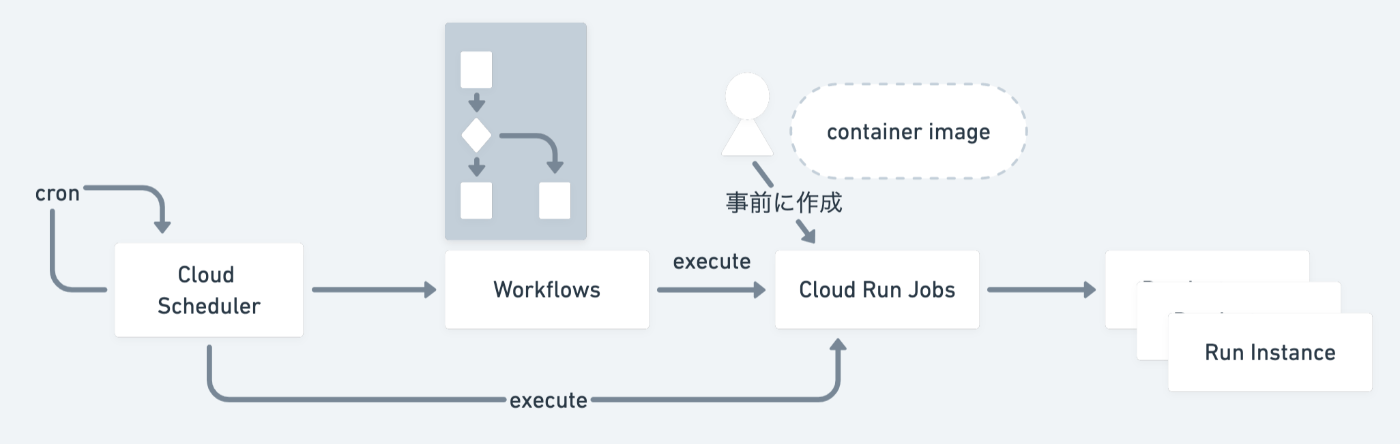
Cloud Scheduler が定期実行のトリガーとなって、まず Workflows を起動します。Workflows は各ステップを順次実行していき、ある1つのステップ中で Cloud Run Jobs をトリガーします。
Cloud Run Jobs は事前にContainer Image や環境変数を指定して「ジョブの作成」を行っておく必要があり、その後、適宜「ジョブの実行」をします。実行時に指定できるパラメータはほぼありません。
ジョブの作成時に parallelism パラメータを指定することで、同時に起動する Instance を増やして、タスクを並列処理することもできます。
選択する際のポイント
サービスの api 等をすでに Cloud Run で動かしている場合はバッチ処理も Cloud Run Jobs で動かすと管理しやすいかもしれません。ただし、Cloud Run と同様に1つ1つのタスクはデフォルトで10分間、最長で1時間までしか実行できないので、長時間の処理には向きません。
Batch の組み合わせ例
Batch は汎用のバッチジョブサービスです。これは Google が長年かけて作成してきた膨大なサービスのリストのなかでも最新のサービスで、企業がワークロードをクラウドに移行する際にジョブを処理してくれます。
Batch もまた2022年7月にプレビューとして登場したばかりのサービスです。
下図は Batch と Workflows や Cloud Scheduler を組み合わせて、動かすイメージ図です。
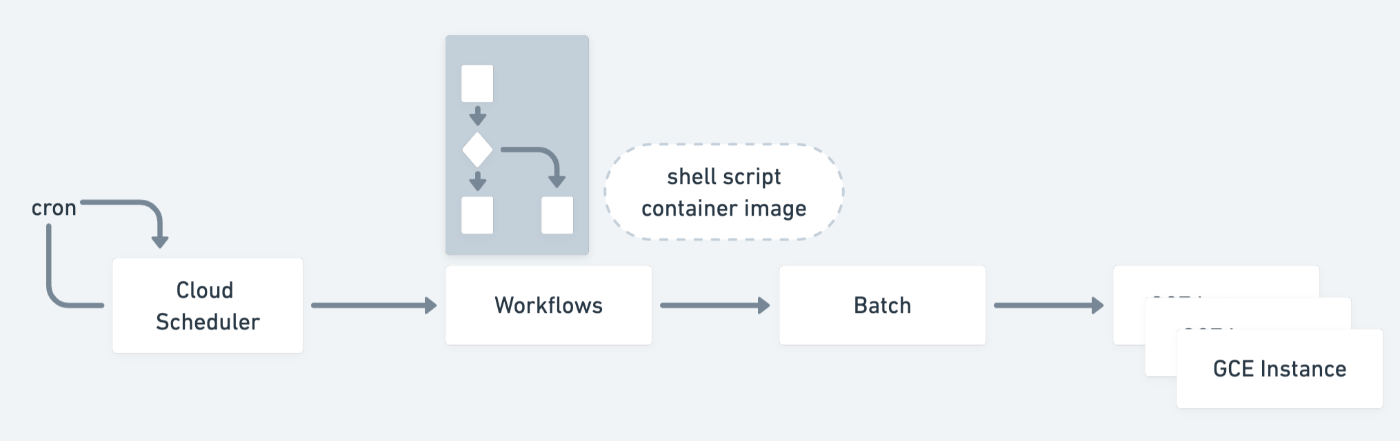
概ね Cloud Run Jobs と似ているのですが、こちらは事前準備なしで Batch をトリガーすると処理が開始されます。Batch は与えられた Container Image やシェルスクリプトと実行環境に関するパラメータに基づいて、GCE Instance を起動して処理を実行します。
Cloud Run Jobs と同様に parallelism パラメータを指定することで、同時に起動する GCE Instance を増やしてタスクを並列処理することもできますが、実行前に指定する必要があるため、Batch 起動前にデータ数に応じて並列数を変更する必要があります。
選択する際のポイント
企業がワークロードをクラウドに移行する際にジョブを処理
と書いてあるように、Batch はどちらかというとオンプレで動かしていた既存のバッチ処理を移行するために用意されたような印象を受けます。互いに通信し合いながら並列処理を行う MPI フレームワークの実行をサポートしていたりすることから、そういったバッチ処理を動かしたい場合は Batch 一択になると思います。
そうでない場合でも、Cloud Run Jobs に比べると長時間実行(最長で1週間)をサポートしているので、より大規模・大容量のデータ処理を行いたい場合は Batch の方が良さそうです。
ただし、2022年12月現在では、まだ東京リージョンでは使用できないです。
Cloud Composer の構成
ハイブリッドおよびマルチクラウド環境にまたがるパイプラインを作成、スケジューリング、モニタリング
Apache Airflow のオープンソースのプロジェクト上に構築され、Python を使用して運用
特定のベンダーに依存する必要がなくなり、使用も簡単
Cloud Composer は Airflow という OSS を Google Cloud がマネージドサービスとして提供しているものです。Airflow を動かすためには非常に多くのコンポーネントを起動する必要があるため、マネージドサービスとして使えるのは非常に助かります。
下図は Cloud Composer のコンポーネントのイメージ図です。タスクを管理するための RDB 等も必要になりますが、ここでは他に合わせて簡略化しています。
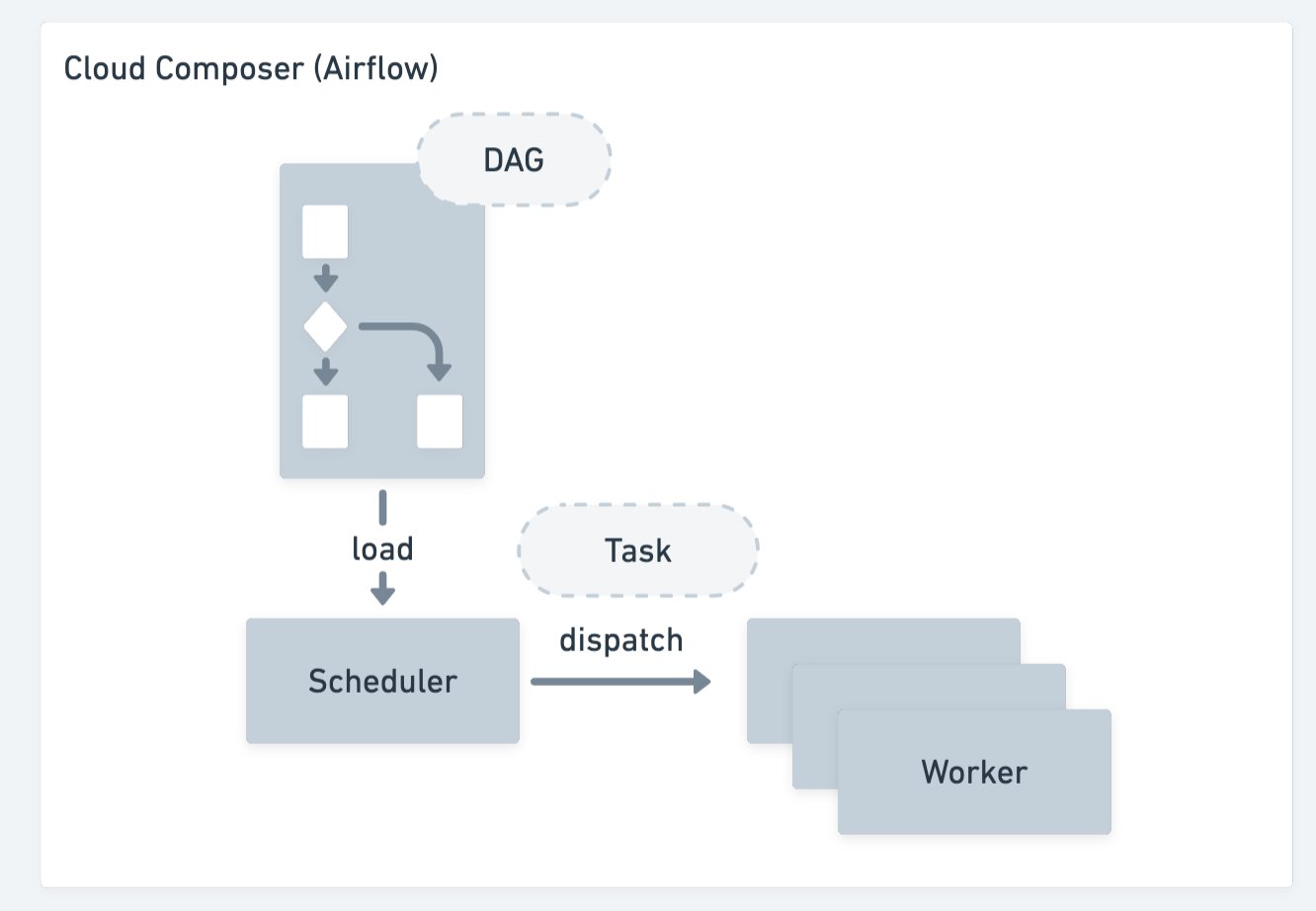
Batch や Cloud Run Jobs と打って変わって、構成要素がすべて Cloud Composer の内部に包括されていることがわかります。Python で書いた DAG ファイルを Google Cloud Storage にアップロードすると、それを Composer の Scheduler が読み取って、スケジュールに従ってタスクを Worker ノードにディスパッチしてくれます。
実行すべきタスクの負荷によって Worker ノードを自動的に増やすことも可能で、異なるタスクの順次実行だけでなく、同種のタスクの並列実行も Cloud Composer 単体で可能です。任意の外部サービスと連携もできるので、Cloud Composer から Batch や Cloud Run Jobs, Dataflow といったサービスを使うこともできます。
選択する際のポイント
癖が強い
冒頭にも書いたとおり、Airflow は様々な概念や機能を内包しているので、何を書いたらどのように動くのか、理解するまでが難しいと思います。シェルスクリプトを実行する機能や外部サービスと簡単に連携できる機能等を各種 xxxOperator として提供しているのですが、それぞれの Operator がどのように動くのか、1つずつ慎重に確認していく必要があります。
維持するためのコスト
Cloud Composer を選択する場合に注意すべき点は、Cloud Composer 環境を維持[2]しておくのに Google Cloud の費用がかかる点です。最小のインスタンスで動かすにしても、月に数万円はかかります。個人のプロジェクトやプロトタイプ的なプロジェクトにとっては小さくはない金額なので、その点から行くと Cloud Scheduler をベースにする方が無難でしょう。
また、Cloud Composer(Airflow) は頻繁にアップデートが入り、バグ修正や新機能の追加も行われます。あるバージョンのサポート期限は、リリースされてからおよそ1年なので、定期的に Cloud Composer 環境のアップグレード作業が必要になります。ボタン1つでバージョンが上がるわけではないため[3]、クリーンな新環境を構築して、旧環境のジョブを停止して、新環境を稼働し始め、問題なければ旧環境を削除する、といったメンテナンス作業が必要になります。止めてはいけないジョブが短い間隔で動いている場合は面倒なメンテナンス作業になる可能性があります。
定期的に一定期間のデータを処理するかどうか
別の観点で、Cloud Composer(Airflow) はもともと、1日に1回、前日分のデータを処理する、といったバッチ処理をターゲットに作られたため、タスクが起動するたびに「今回処理すべき対象日時」の値が渡されます。例えば、毎日10時に実行するジョブがあったときに、11/29 10:00に実行されると、対象日時として「11/28 10:00」が渡されます。
この仕組みがあるおかげで、過去のある時点のタスクを再実行するといったことが簡単にできます。
日次で何かを集計するのは日常茶飯事ですが、バッチ処理には失敗がつきものです。各処理を冪等に実装しておけば、たとえ実行に失敗していたとしても、特定の日時の分を簡単に再実行できるというのは安心感があります。
テラーノベルではまさにこの点が刺さって Cloud Composer を使い始めました。
おわりに
大規模なデータ処理や複雑な依存関係があるタスクをうまく実現できると楽しいですよね!
各サービスをこんなユースケースで使ってるよーみたいなのがあればぜひ教えて下さい。
この記事を書くために GCPUG Slack で Cloud Run Jobs や Batch の仕様やユースケース等いろいろ教えていただきました。いつも助けられてばかりです。感謝!
余談: cron には注意
上記のような構成とは別に、昔ながらの cron を GCE Instance 上で動かすという方法もありますが、ある程度サービスが大きくなってくると関連するシステムがどんどん増えていきます。依存関係のある異なるタスクを各システムの cron で実行していくのは絶対に避けたいところです。
- 1:00 システム A の処理を実行してファイルを B に送る(30分で終わる予定)
- 2:00 システム B の処理を実行してファイルを C に送る(1時間で終わる予定)
- 4:00 システム C が処理を実行して、関係者にメールを送る
システム X の処理は n 時間で終わる「だろう」という思想で作られた各システムの cron は前のシステムが失敗していようが関係なしに次のジョブを起動していきます。2,3個ならまだ良いですがシステム数が10個を超えていくと、途中で失敗したり予定時刻を超えたりしたときにまさに地獄です。
本当に地獄なのでやめましょう……。

Discussion