はじめに
GPT-4oがリリースされ、様々な取り組みに活用されています。
例えば、物体検出の分野でも、画像を入力してBounding Boxを出力するような試みが行われています。
しかし、大規模なマルチモーダルモデル(LMMs)であっても、画像内の細かな位置情報を用いるようなタスクは比較的不得意な分野です。
この問題への対策として、画像中にDot Matrixを付与するアプローチが提案されています。
この記事では、Dot Matrixを付与した画像をgpt-4oに入力することで、物体検出能力が向上するかを試してみたいと思います。
対象画像
本来は大規模なデータセットにおいて、統計的に精度検証すべきですが、今回はお試しということで、MS COCOデータセットから、次の画像1枚を対象に実験をしてみます。

また、今回はBoundingBoxの位置精度についての検証が主目的のため、画像中に存在し得るラベルの種類はプロンプトで与えてあげることとします。(今回だと、"person", "motorcycle")
実験
実装した内容は以下で公開しています。
python+OpenAI APIを用いて、Dot Matrixを付与した画像とそうでない画像で、物体検出の精度に影響が出るかを比較していきます。
Dot Matrixを用いない場合
Dot Matrixを付与する前に、そのままの画像を入力してどのような結果が得られるかを見てみましょう。
システムプロンプトとして、次の文章を利用しました。
あなたは画像中の物体を検出する役割を担っています。
userから与えられる画像の中から、[labelのリスト]に該当するすべての物体を検出し、その物体を過不足なく抽出することができる矩形の座標情報を教えてください。
あなたが出力する矩形は、物体の全てを完全に囲み、またできる限り物体にフィットしている必要があります。
検出結果は、次のようなJSON形式で出力する必要があります。座標値は画像の左上を(0.0, 0.0)、右下を(1.0, 1.0)とした相対座標で表現してください。
{{"num_annotations": 2, "annotations": [{{"label": "label1", "coordinates": {{"top": 0.15, "right": 0.25, "bottom": 0.35, "left": 0.40}}}}, {{"label": "label2", "coordinates": {{"top": 0.50, "right": 0.65, "bottom": 0.75, "left": 0.80}}}}]}}
ここで、num_annotationsは検出した物体の数、labelは[labelのリスト]のうちどのラベルに該当するかを、coordinatesは矩形の座標情報をそれぞれ表しています。
この作業を2つのSTEPに分けて実施します。STEP1では、検出対象の物体の左上と右下の位置を可能な限り正確に特定します。STEP2では、STEP1で特定した位置をもとに、物体のラベルを特定し、その情報をJSON形式で返してください。
このプロンプトと画像を入力とし、Bounding Boxの座標値とラベルをjson形式で出力させます。
import base64
import json
import os
from pathlib import Path
import cv2
from dotenv import load_dotenv
from matplotlib import pyplot as plt
from openai import OpenAI
load_dotenv(dotenv_path=".env")
if "OPENAI_API_KEY" not in os.environ:
raise ValueError("OPENAI_API_KEY is not set in the environment variables.")
def encode_image(image_path: Path) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def assign_label_colors(labels: list[str]) -> dict[str, tuple[int, int, int]]:
colors = {}
for x in labels:
if x not in colors:
colors[x] = (np.random.randint(0, 255), np.random.randint(0, 255), np.random.randint(0, 255))
return colors
def extract_coordinate_json(coordinate_json: dict[str, float], height: int, width: int) -> tuple[int, int, int, int]:
top = int(coordinate_json["top"] * height)
right = int(coordinate_json["right"] * width)
bottom = int(coordinate_json["bottom"] * height)
left = int(coordinate_json["left"] * width)
return top, right, bottom, left
def main():
image_path = Path("./target.jpg")
labels = ["person", "motorcycle"]
original_image = cv2.imread(str(image_path))
height, width, _ = original_image.shape
base64_image = encode_image(image_path)
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
system_prompt = f"""
あなたは画像中の物体を検出する役割を担っています。
userから与えられる画像の中から、{', '.join(labels)}に該当するすべての物体を検出し、その物体を過不足なく抽出することができる矩形の座標情報を教えてください。
あなたが出力する矩形は、物体の全てを完全に囲み、またできる限り物体にフィットしている必要があります。
検出結果は、次のようなJSON形式で出力する必要があります。座標値は画像の左上を(0.0, 0.0)、右下を(1.0, 1.0)とした相対座標で表現してください。
{{"num_annotations": 2, "annotations": [{{"label": "label1", "coordinates": {{"top": 0.15, "right": 0.25, "bottom": 0.35, "left": 0.40}}}}, {{"label": "label2", "coordinates": {{"top": 0.50, "right": 0.65, "bottom": 0.75, "left": 0.80}}}}]}}
ここで、num_annotationsは検出した物体の数、labelは{', '.join(labels)}のうちどのラベルに該当するかを、coordinatesは矩形の座標情報をそれぞれ表しています。
この作業を2つのSTEPに分けて実施します。STEP1では、検出対象の物体の左上と右下の位置を可能な限り正確に特定します。STEP2では、STEP1で特定した位置をもとに、物体のラベルを特定し、その情報をJSON形式で返してください。
"""
user_prompt = """
この画像に写っているものを検出して下さい。
まずSTEP1を始めて下さい。
"""
contents = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": [
{"type": "text", "text": user_prompt},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpg;base64,{base64_image}"},
},
],
},
]
# STEP1
response = client.chat.completions.create(
model="gpt-4o",
messages=contents,
max_tokens=300,
temperature=0.2,
)
answer = response.choices[0].message.content
# STEP2
contents.append({"role": "assistant", "content": answer})
contents.append({"role": "user", "content": "STEP2を始めて下さい"})
response = client.chat.completions.create(
model="gpt-4o",
messages=contents,
response_format={"type": "json_object"},
max_tokens=300,
temperature=0.2,
)
annotation_json = response.choices[0].message.content
if annotation_json is not None:
annotation_dict = json.loads(annotation_json)
annotations = annotation_dict["annotations"]
label_colors = assign_label_colors(labels)
for x in annotations:
label = x["label"]
coordinates = x["coordinates"]
color = label_colors[label]
top, right, bottom, left = extract_coordinate_json(coordinates, height, width)
cv2.rectangle(original_image, (left, top), (right, bottom), color, 2)
cv2.putText(original_image, f"{x['label']}", (left, top - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.4, color, 1)
plt.imshow(cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB))
plt.show()
if __name__ == "__main__":
main()
プログラムを実行してみると、次のような結果が得られました。

person, motorcycleの検出ができており、位置関係も適切に認識していますが、Bounding Boxの位置は少々大雑把な印象を受けます。
Dot Matrixを用いる場合
次に、Dot Matrixを付与した画像を入力してみましょう。
Dot Matrixを付与した画像は次のように作成しました。
def overlay_dot_matrix(image_path: Path) -> Path:
STEP = 10
image = cv2.imread(str(image_path))
height, width, _ = image.shape
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, binary_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
step_x = width // STEP
step_y = height // STEP
for i in range(1, STEP):
for j in range(1, STEP):
x = i * step_x
y = j * step_y
if binary_image[y, x] == 0:
color = (255, 255, 255)
else:
color = (0, 0, 0)
cv2.circle(image, (x, y), 3, color, -1)
cv2.putText(
image,
f"({i / STEP:.1f},{j / STEP:.1f})",
(x - 20, y - 5),
cv2.FONT_HERSHEY_SIMPLEX,
0.4,
color,
1,
)
output_path = image_path.parent / (image_path.stem + "_with_dot_matrix" + image_path.suffix)
cv2.imwrite(str(output_path), image)
return output_path
画像を縦横10分割し、その位置の画像の色に応じて、白または黒のドットを打ちます。
また、画像のサイズを0.0-1.0として、(x, y)の形式で座標値も付与します。

この画像を入力とし、またDot Matrixに関する説明を含んだ追加のプロンプトを入力します。
additional_prompt = """
画像中には、その位置の目印として、ドットとその座標が(x座標, y座標)の形式で記入されています。
ドットは9x9の81個存在し、左上のドットが(0.1, 0.1)、右下のドットが(0.9, 0.9)に位置しています。
また、画像の左上端が(0.0, 0.0)、右下端が(1.0, 1.0)です。
あなたはこの情報を利用して物体の位置を特定してください。以下の手順を参考にしてください:
1. 検出対象の物体を認識し、どのように配置されているかを説明する
2. 認識した物体のの上下左右それぞれの端に最も近いドットの位置を特定し、その座標を説明する
3. ドットの座標を用いて、物体の境界を示す矩形の位置を特定する。複数のドットがある場合、平均値を取るなどして精度を上げる。
"""
system_prompt = f"""
あなたは画像中の物体を検出する役割を担っています。
userから与えられる画像の中から、{', '.join(labels)}に該当するすべての物体を検出し、その物体を過不足なく抽出することができる矩形の座標情報を教えてください。
あなたが出力する矩形は、物体の全てを完全に囲み、またできる限り物体にフィットしている必要があります。
{additional_prompt}
検出結果は、次のようなJSON形式で出力する必要があります。座標値は画像の左上を(0.0, 0.0)、右下を(1.0, 1.0)とした相対座標で表現してください。
{{"num_annotations": 2, "annotations": [{{"label": "label1", "coordinates": {{"top": 0.15, "right": 0.25, "bottom": 0.35, "left": 0.40}}}}, {{"label": "label2", "coordinates": {{"top": 0.50, "right": 0.65, "bottom": 0.75, "left": 0.80}}}}]}}
ここで、num_annotationsは検出した物体の数、labelは{', '.join(labels)}のうちどのラベルに該当するかを、coordinatesは矩形の座標情報をそれぞれ表しています。
この作業を2つのSTEPに分けて実施します。STEP1では、検出対象の物体の左上と右下の位置を可能な限り正確に特定します。STEP2では、STEP1で特定した位置をもとに、物体のラベルを特定し、その情報をJSON形式で返してください。
"""
検出結果は次の通りです。

Dot Matrixなしに比べて、より物体にフィットしたBounding Boxを出力しています。
また、以下は途中出力の一例です。
STEP1では、検出対象の物体の左上と右下の位置を特定します。
1. person:
- 左上: ドット(0.3, 0.2)
- 右下: ドット(0.6, 0.5)
2. motorcycle:
- 左上: ドット(0.25, 0.4)
- 右下: ドット(0.75, 0.7)
次に、この情報をもとにSTEP2で最小の矩形の座標情報を特定し、物体のラベルを特定してJSON形式で出力します。
{
"num_annotations": 2,
"annotations": [
{
"label": "person",
"coordinates": {
"top": 0.2,
"right": 0.6,
"bottom": 0.5,
"left": 0.3
}
},
{
"label": "motorcycle",
"coordinates": {
"top": 0.4,
"right": 0.75,
"bottom": 0.7,
"left": 0.25
}
}
]
}
Dotの位置を活用して、最終的な座標値を求めていることがわかります。
IoUの比較
参考までに、IoUを用いて、どの程度の改善ができたか定量化してみます。
次のような正解のBBoxを定義した上で、
Dot Matrixありとなしで、各30回判定を行い、IoUを算出しました。
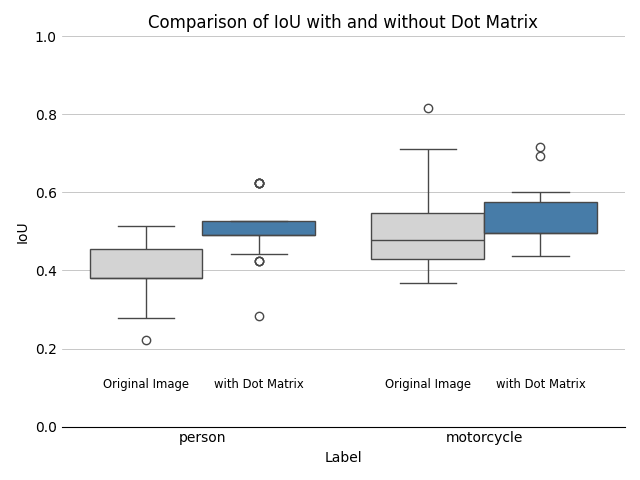
Dot Matrixありの方が、person、motorcycleともに若干IoUが向上しています。
上記の画像では比較的うまくいった例を挙げましたが、グラフを見て分かるとおり、両者の差は決して大きくはなく、また、Dot Matrixを使っていても的外れなBBoxを出力する場合、Dot Matrixなしでも的確なBBoxを出力することもありました。
今回のユースケースにおいては、Dot Matrixは、検出の堅牢性を若干高めてくれる、程度のものだと思った方が良さそうです。
あとがき
今回の検証を通じて、Dot Matrixを用いることで精度が若干向上することが確認できました。劇的な改善とは言えないものの、これだけ簡単な処理で精度が上がるのであれば取り入れてみても良いかもしれないですね。

Discussion