はじめに
以前からリンカーに興味あったので、リンカーの勉強の一環でシンプルなリンカーを実装してみました。
次のコードのオブジェクトファイルからaarch64向けのELFバイナリを生成して実行できるだけのリンカーですが、
それでも色々と学びがあったので、実装について解説をしていきたいと思います。
__asm__(
".global _start\n"
"_start:\n"
" adr x0, x\n"
" ldr w0, [x0]\n"
" mov x8, #93\n"
" svc #0\n"
)
int x = 11;
$ gcc -c main.c -o main.o && gcc -c sub.c -o sub.o
$ cargo run -- a.out main.o sub.o
$ ./a.out
$ echo $?
11
リンカーとは
リンカーとは、コンパイラが生成したオブジェクトファイル(.oファイル)を結合して実行可能ファイルを作るソフトウェアです。
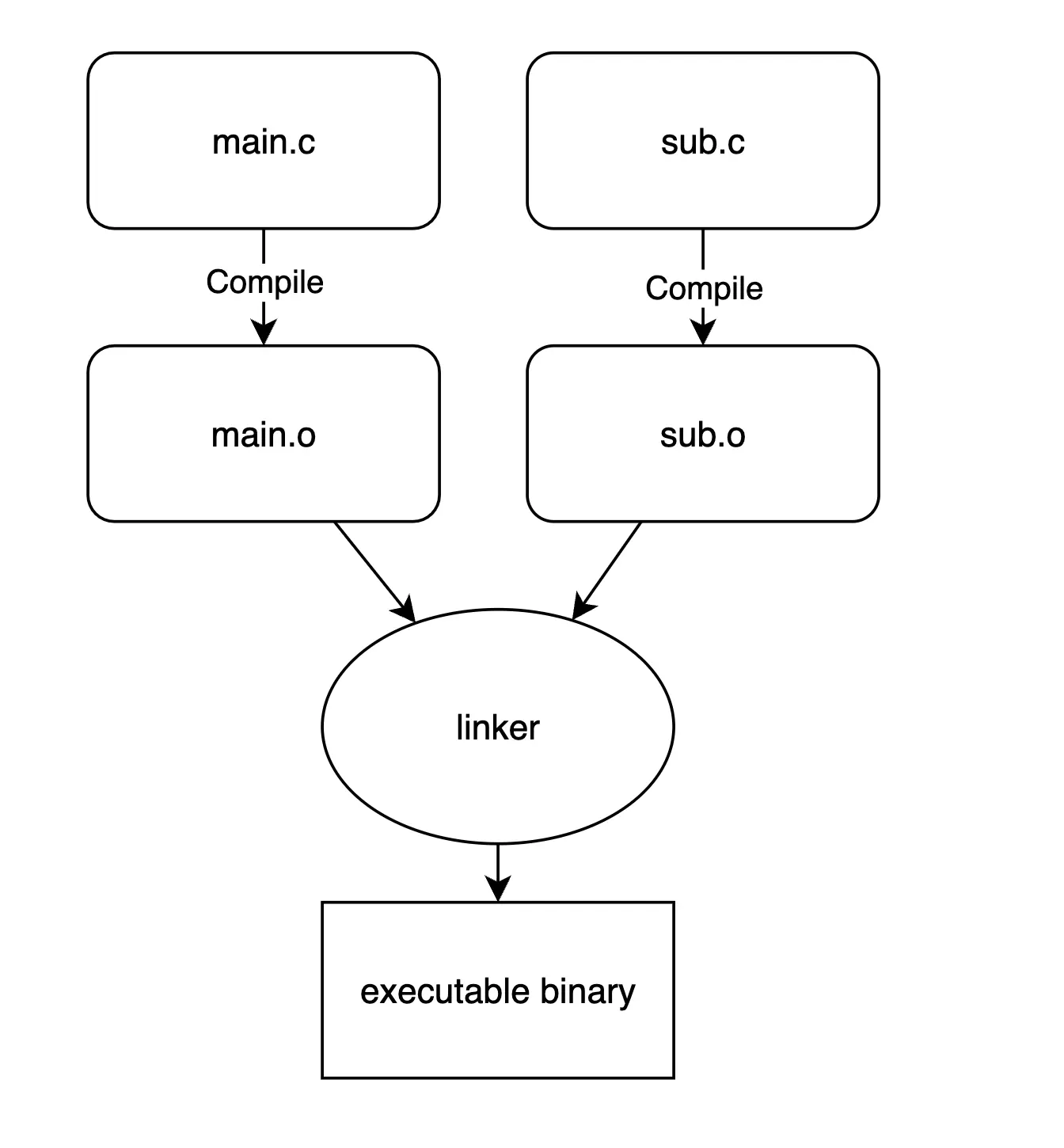
簡単に説明すると、次のようなことを行っています。
- 複数のオブジェクトファイルを読み込む
- シンボル(変数や関数の名前などの情報)を解決
- 重複や未定義の場合の処理
- セクション(コードやデータの固まり)を結合して適切にレイアウトする
- シンボルの参照先を正しいアドレスに調整する(再配置)
- 実行可能な形式のファイルを出力する
オブジェクトファイルとは
オブジェクトファイルとは、コンパイラがソースコード(CやRustなど)をコンパイルした結果の中間ファイルです。冒頭の例にあるsub.oやmain.oがオブジェクトファイルです。
オブジェクトファイルはOSによってフォーマットが異なります。
主に次のフォーマットがあります。
| OS | フォーマット |
|---|---|
| Unix/Linux | ELF(Executable and Linkable Format) |
| macOS | Mach-O(Mach object) |
| Windows | COFF(Common Object File Format) |
今回実装したリンカーはaarch64 Linuxで動くELFです。
オブジェクトファイルの中身
オブジェクトファイルの中には、主に次のような情報が含まれています。
-
ELFヘッダー:
ELFファイルの先頭に位置するメタデータで、ファイルの種類、ターゲットアーキテクチャ、エントリーポイントなどの基本情報を含みます。 -
コードセクション (
.text):
プログラムの実行命令(機械語)が格納されています。関数の実態などはここに入ります。 -
データセクション (
.data):
初期化済みのグローバル変数やスタティック変数が格納されます。 -
シンボルテーブル (
.symtab):
関数名や変数名などの「シンボル」とその属性(位置、可視性、サイズなど)を記録するテーブルです。 -
リロケーション (
.rel.text,.rel.dataなど):
リンク時に調整が必要な場所(関数呼び出しや変数参照など)を示す情報です。 -
セクションヘッダーテーブル:
オブジェクトファイル内の各セクションの位置、サイズ、属性などの情報を管理するテーブルです。
各セクションのファイル内のオフセットやサイズなどの情報が含まれています。 -
プログラムヘッダーテーブル:
主に実行可能ファイルや共有オブジェクトファイルに存在し、OSがプログラムをどのようにメモリに読み込むべきかを示す情報です。
実行時に必要です。
実際のELFファイルの構造はおおよそ次のようになっています。
┌──────────────────┐
│ ELF Header │
├──────────────────┤
│ Program Header │ ← For executables (OS-oriented)
├──────────────────┤
│ Section 1 │
│ .text │
├──────────────────┤
│ Section 2 │
│ .data │
├──────────────────┤
│ ... │
├──────────────────┤
│ Section Header │ ← For linkers
└──────────────────┘
readelfコマンドを使うと、これらの情報を確認できます。
実行例
# ELFヘッダーの表示
$ readelf -h sub.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: AArch64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 408 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 9
Section header string table index: 8
# セクション一覧
$ readelf -S sub.o
There are 9 section headers, starting at offset 0x198:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 1
[ 2] .data PROGBITS 0000000000000000 00000040
0000000000000004 0000000000000000 WA 0 0 4
[ 3] .bss NOBITS 0000000000000000 00000044
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .comment PROGBITS 0000000000000000 00000044
0000000000000028 0000000000000001 MS 0 0 1
[ 5] .note.GNU-stack PROGBITS 0000000000000000 0000006c
0000000000000000 0000000000000000 0 0 1
[ 6] .symtab SYMTAB 0000000000000000 00000070
00000000000000d8 0000000000000018 7 8 8
[ 7] .strtab STRTAB 0000000000000000 00000148
0000000000000006 0000000000000000 0 0 1
[ 8] .shstrtab STRTAB 0000000000000000 0000014e
0000000000000045 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
p (processor specific)
# プログラムヘッダー
$ readelf -l a.out
Elf file type is EXEC (Executable file)
Entry point 0x400100
There are 2 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000000000 0x0000000000400000 0x0000000000400000
0x0000000000000010 0x0000000000000010 R E 0x10000
LOAD 0x0000000000000110 0x0000000000410110 0x0000000000410110
0x0000000000000004 0x0000000000000004 RW 0x10000
Section to Segment mapping:
Segment Sections...
00
01 .data
# シンボルテーブル
$ readelf -s sub.o
Symbol table '.symtab' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 2
4: 0000000000000000 0 SECTION LOCAL DEFAULT 3
5: 0000000000000000 0 NOTYPE LOCAL DEFAULT 2 $d
6: 0000000000000000 0 SECTION LOCAL DEFAULT 5
7: 0000000000000000 0 SECTION LOCAL DEFAULT 4
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 2 x
オブジェクトファイルとリンカーの歴史
Deep Resarchで調査してもらった結果ですが、要約すると次のようです。
- 初期のコンピュータではメモリ容量が限られていたため、プログラムを分割してコンパイルしてあとで結合していた
- 分割することによって、部品(共有ライブラリなど)を共有できるメリットがある
詳細はこちらを参照してください。
一番シンプルなELF
リンカーの動作する仕組みを理解するにあたり、まず必要最低限で実行可能なバイナリの形を模索していきました。
最初に思いつくのはHello, Worldを標準出力するプログラムです。
#include <stdio.h>
int main() {
printf("Hello, World\n");
}
しかし、printfはlibcで提供されているため、実行バイナリを生成するためにはリンカーに動的リンクの機能を実装する必要があります。
単純なHello, Worldでも実装が結構大変です。
次に考えたシンプルなのが変数を終了ステータスコードとして使うだけのプログラムです。
int x = 11;
__asm__(
".global _start\n"
"_start:\n"
" adr x0, x\n"
" ldr w0, [x0]\n"
" mov x8, #93\n"
" svc #0\n"
)
このコードはsub.cにあるxをw0レジスタにロードして終了ステータスコードとして使っています。
glibcを使う必要のないおそらく一番シンプルな構成です。
これらのコードをコンパイルするとかなりシンプルなオブジェクトファイルが作られるので、
あとはそれらを解析して実行ファイルを作成すればよいです。
リンカーの実装
main.cとsub.cからコンパイルしたオブジェクトファイルmain.oとsub.oをリンクするシンプルなリンカーの実装について説明していきます。
リンク処理の流れ
最小限の実行可能なELFバイナリを作成するために必要最低限な情報は次です
- ELFヘッダー
- セクションヘッダー
- 各種セクション
-
.text:main.oの場合adrやldrなど、_startで記述している命令が格納されている -
.data:sub.oの場合xの実際の値が格納されている -
.strtab: シンボル名の文字列が格納されている -
.shstrtab: セクション名の文字列が格納されている -
.rela.text: リロケーション情報が格納されている
-
リンカーでsub.oとmain.oから上記の情報を読み取り、実行バイナリを作っていきます。
処理の流れはおおよそ次のとおりです。
- ELFヘッダーを解析して、ファイル内のセクションヘッダーの読み取り開始位置などを取得
- 1の情報を使って、各種セクションヘッダー情報を取得
- 2の情報を使って、各種セクション情報を取得
-
.textと.dataの結合してシンボルの参照先のアドレスを書き換える -
strtabと.shstrtab及び各セクションヘッダーを作成 - ELFヘッダー、セクション、セクションヘッダーなどをファイルに書き出す
最終的にでき上がるバイナリのセクションは次のようになります。
$ readelf -S a.out
There are 6 section headers, starting at offset 0x1e0:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000400100 00000100
0000000000000010 0000000000000000 AX 0 0 4
[ 2] .data PROGBITS 0000000000410110 00000110
0000000000000004 0000000000000000 WA 0 0 4
[ 3] .symtab SYMTAB 0000000000000000 00000128
0000000000000090 0000000000000018 4 4 8
[ 4] .strtab STRTAB 0000000000000000 00000111
0000000000000011 0000000000000000 0 0 1
[ 5] .shstrtab STRTAB 0000000000000000 000001b8
0000000000000027 0000000000000000 0 0 1
リンク処理の全体像は次のようになっています。
pub fn link_to_file(&mut self, inputs: Vec<Vec<u8>>) -> Result<Vec<u8>, Error> {
for input in inputs {
let obj = parser::parse_elf(&input)?.1;
self.objects.push(obj);
}
let mut resolved_symbols = self.resolve_symbols()?;
let (output_sections, section_name_offsets) =
self.layout_sections(&mut resolved_symbols)?;
let mut out = std::io::Cursor::new(Vec::new());
self.write_executable(
&mut out,
resolved_symbols,
output_sections,
section_name_offsets,
)?;
Ok(out.into_inner())
}
ELFパーサーの実装
開発はubuntuコンテナで行っているので、ELFの構造に関しては基本的にヘッダーファイル/usr/include/elf.hを参考にしました。
たとえばELFヘッダーの構造体は次のように定義されていて、バイナリのレイアウトがそのまま表現されています。
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
良くわからないところに関してはこちらのサイトなどを参考にしたりしました。
今回実装したリンカーではnomというパーサーコンビネータライブラリを使って、ELFバイナリをパースしています。
以前こちらの本でも使用していて便利だったので、引き続き使用しました。
ELFパースの流れ
ELFのパース処理は、大きく次のような流れになっています。
- ELFヘッダーのパース
- セクションヘッダーのパース
- 2のヘッダー情報を使ってシンボルテーブルとリロケーションをパース
これらを組み合わせて、最終的に次のELF構造体を生成します。
#[derive(Debug)]
pub struct ELF {
/// The ELF file header, containing metadata about the file.
pub header: header::Header,
/// A list of section headers, describing the sections in the ELF file.
pub section_headers: Vec<section::Header>,
/// A list of symbols defined in the ELF file.
pub symbols: Vec<symbol::Symbol>,
/// A list of relocation entries with addends.
pub relocations: Vec<relocation::RelocationAddend>,
}
ELFヘッダーのパース
ELFの最初にはヘッダーがありreadelf -hで出力される情報が格納されています。
$ readelf -h main.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
...
これをnomを使ってバイナリを読み取って構造体のフィールドに格納していくだけです。
pub fn parse(raw: &[u8]) -> ParseResult<Header> {
if raw.len() < ELF_IDENT_HEADER_SIZE {
bail_nom_error!(ParseError::InvalidHeaderSize(raw.len() as u8));
}
// ELF識別子をパース
let (rest, ident) = parse_ident(raw)?;
// 各種フィールドをパース
let (rest, r#type) = parse_type(rest)?;
let (rest, machine) = parse_machine(rest)?;
// ... その他のフィールド ...
Ok((
rest,
Header {
ident,
r#type,
machine,
// ... 他のフィールド ...
},
))
}
セクションヘッダーのパース
セクションヘッダーを読み取るにあたり、EFLヘッダーにある次の情報が必要です。
- shoff: セクションヘッダーのオフセット
- shnum: セクションヘッダーの数
- shstrndx: 文字列テーブル
.shstrtabへのインデックス
パース処理はシンプルで、shoffの位置からshnum回繰り返しセクションヘッダーの各フィールドの値を読み取るだけです。
セクションの名前は直接ヘッダーに含まれているわけではなく、文字列テーブル(.shstrtab)内のオフセットとして格納されているので、パース後に名前を解決するようにしています。
また、セクションヘッダーをパースできた時点でセクションのデータも取得できるので、あとの処理が楽になるようにデータをヘッダーといっしょに持っておきます。
pub fn parse_header(
raw: &[u8],
shoff: usize,
shstrndx: usize,
shnum: usize,
) -> ParseResult<Vec<Header>> {
if shnum == 0 {
return Ok((raw, vec![]));
}
// セクションヘッダーをshnum分パース
count(
|rest| {
let (rest, name_idx) = le_u32(rest)?;
let (rest, r#type) = parse_type(rest)?;
// ... その他のフィールド ...
// セクションデータを取得
let data = raw[offset as usize..(offset + size) as usize].to_vec();
let header = Header {
name_idx,
name: "".into(), // あとで埋める
// ... その他のフィールド ...
section_raw_data: data,
};
Ok((rest, header))
},
shnum,
)
.parse(&raw[shoff..])
.map(|(rest, mut headers)| {
// セクション名を文字列テーブルから解決
let shstrtab = &headers[shstrndx];
let string_table =
&raw[shstrtab.offset as usize..(shstrtab.offset + shstrtab.size) as usize];
for header in headers.iter_mut() {
header.name = helper::get_string_by_offset(string_table, header.name_idx as usize);
}
(rest, headers)
})
}
ELFの場合、文字列テーブルに格納されている文字列はNULL終端をもつので、インデックスからNULLまで読み取ります。
pub fn get_string_by_offset(raw: &[u8], offset: usize) -> String {
let mut end = offset;
while raw[end] != 0 {
end += 1;
}
String::from_utf8_lossy(&raw[offset..end]).to_string()
}
シンボル一覧の取得
シンボル解決するためにまず最初はシンボル一覧を集めます。
シンボルセクションヘッダーにある次の情報が必要です。
- link: シンボル名の文字列テーブルのインデックス
- size: セクションのサイズ
- entsize: 各シンボルのサイズ
こちらもセクションヘッダーのパースと同様、size/entsizeの回数だけ繰り返しパースしていきます。
シンボル名の文字列テーブルの位置は.strtabにあるので、linkからヘッダー情報を取得して文字列テーブルを取得しておきます。
pub fn parse<'a>(raw: &'a [u8], section_headers: &'a [Header]) -> ParseResult<'a, Vec<Symbol>> {
let Some(symbol_header) = section_headers
.iter()
.find(|header| header.r#type == SectionType::SymTab)
else {
return Ok((&[], vec![]));
};
let strtab = §ion_headers[symbol_header.link as usize];
let string_table = &raw[strtab.offset as usize..(strtab.offset + strtab.size) as usize];
let entry_count = (symbol_header.size / symbol_header.entsize) as usize;
let (rest, symbols) = count(
|raw| {
let (rest, name_idx) = le_u32(raw)?;
// ... その他のフィールド ...
let name = helper::get_string_by_offset(string_table, name_idx as usize);
let symbol = Symbol {
name,
// ... その他のフィールド ...
};
Ok((rest, symbol))
},
entry_count,
)
.parse(symbol_header.section_raw_data.as_ref())?;
Ok((rest, symbols))
}
シンボル解決の実装
リンカーの重要な役割のひとつがシンボル解決です。
今回の例ではmain.cがsub.cのxを参照しているので、xを見つける必要があります。
改めてそれぞれのシンボルテーブルをreadelf -sコマンドで確認すると次のようになっています。
# main.oのシンボルテーブル
$ readelf -s main.o
Symbol table '.symtab' contains 10 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 3
4: 0000000000000000 0 SECTION LOCAL DEFAULT 4
5: 0000000000000000 0 NOTYPE LOCAL DEFAULT 1 $x
6: 0000000000000000 0 SECTION LOCAL DEFAULT 6
7: 0000000000000000 0 SECTION LOCAL DEFAULT 5
8: 0000000000000000 0 NOTYPE GLOBAL DEFAULT 1 _start
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND x
# sub.oのシンボルテーブル
$ readelf -s sub.o
Symbol table '.symtab' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS
2: 0000000000000000 0 SECTION LOCAL DEFAULT 1
3: 0000000000000000 0 SECTION LOCAL DEFAULT 2
4: 0000000000000000 0 SECTION LOCAL DEFAULT 3
5: 0000000000000000 0 NOTYPE LOCAL DEFAULT 2 $d
6: 0000000000000000 0 SECTION LOCAL DEFAULT 5
7: 0000000000000000 0 SECTION LOCAL DEFAULT 4
8: 0000000000000000 4 OBJECT GLOBAL DEFAULT 2 x
ここで重要なポイントは次のとおりです。
-
main.oの5番目のシンボル:xがUND(未定義)として登録されている -
sub.oの8番目のシンボル:xが定義済み(.dataセクションにある)-
Ndxはシンボルの値(今回は11というリテラル)を保持しているセクションのインデックスで、sub.oの2番目のセクションは.data
-
main.oの未定義シンボルxを、sub.oの定義済みシンボルxと紐付ける処理は次になります。
- 同じ名前のシンボルがある場合、未定義シンボルは定義済みシンボルで上書き
- 定義済みシンボル同士が競合する場合は、バインディング(LOCAL/GLOBAL/WEAK)の強さで判断
- すべての未定義シンボルが解決できたかチェック
これを実装したコードは次のとおりです。
pub fn resolve_symbols(&self) -> Result<HashMap<String, output::ResolvedSymbol>, Error> {
// シンボル解決の結果
let mut resolved_symbols: HashMap<String, output::ResolvedSymbol> = HashMap::new();
// 重複したシンボル
let mut duplicate_symbols = vec![];
// すべてのオブジェクトファイル内のシンボルを処理
for (obj_idx, obj) in self.objects.iter().enumerate() {
for symbol in &obj.symbols {
let new_symbol = output::ResolvedSymbol {
name: symbol.name.clone(),
value: symbol.value,
size: symbol.size,
info: symbol.info,
shndx: symbol.shndx,
object_index: obj_idx,
// シンボルが特定のセクションに定義されているかどうかを判断
// SymbolIndex::Undefinedでなければ定義済みと判断
is_defined: SymbolIndex::Undefined != symbol.shndx,
};
// 同じ名前のシンボルが既に解決済みリストにあるか確認
if let Some(existing) = resolved_symbols.get(&symbol.name) {
// 両方のシンボルが定義済み(重複定義)の場合
if new_symbol.is_defined && existing.is_defined {
// 新しいシンボルの方が強ければ、既存のものを上書き
if new_symbol.is_stronger_than(existing) {
resolved_symbols.insert(symbol.name.clone(), new_symbol);
} else {
// 重複シンボルとして記録(エラー報告用)
duplicate_symbols.push(symbol.name.clone());
}
} else if new_symbol.is_defined && !existing.is_defined {
// 新しいシンボルが定義済みで既存が未定義の場合は上書き
// 例: main.oの未定義シンボルxがsub.oの定義済みシンボルxで解決される
resolved_symbols.insert(symbol.name.clone(), new_symbol);
}
} else {
resolved_symbols.insert(symbol.name.clone(), new_symbol);
}
}
}
// 重複シンボルがあればエラーを返す
if !duplicate_symbols.is_empty() {
return Err(format!("Duplicate symbols: {:?}", duplicate_symbols).into());
}
// 未解決のシンボルを抽出
let unresolved_symbols: Vec<_> = resolved_symbols
.iter()
.filter_map(|(_, symbol)| {
if symbol.is_defined {
return None; // 定義済みなのでスキップ
}
Some(symbol.name.clone())
})
.collect();
// 未解決シンボルがあればエラーを返す
if !unresolved_symbols.is_empty() {
return Err(format!("There are unresolved symbols: {:?}", unresolved_symbols).into());
}
// すべてのシンボルが正常に解決されたら結果を返す
Ok(resolved_symbols)
}
シンボルの「強さ」を判断するために、バインディング(GLOBAL、LOCAL、WEAKなど)を考慮しています。
pub fn is_stronger_than(&self, other: &Self) -> bool {
match (self.info.binding, other.info.binding) {
(symbol::Binding::Local, _) => true, // LOCALが最強(常に他のバインディングより優先)
(_, symbol::Binding::Weak) => true, // WEAKより他のすべてのバインディングは強い
(symbol::Binding::Global, symbol::Binding::Global) => false, // 同じGLOBAL同士なら後勝ち(新しいシンボルは優先されない)
(symbol::Binding::Global, symbol::Binding::Local) => false, // LOCALのほうがGLOBALより強い
(symbol::Binding::Weak, _) => false, // WEAKは最も弱い(他のバインディングに常に負ける)
_ => false,
}
}
今回の例では、main.oのxは未定義なので、sub.oの定義済みxが優先されます。
もし両方のオブジェクトファイルに定義済みの同名シンボルがあった場合は、この「強さ」の比較が行います。
セクションの配置
ELFのパースが終わり、すべてのシンボルが解決された後は、これらの情報を使って実行バイナリに必要なセクションの作成とメモリ配置やリロケーションの処理をしていきます。
全体の流れは次のとおりです。
pub fn layout_sections(
&self,
resolved_symbols: &mut HashMap<String, output::ResolvedSymbol>,
) -> Result<(Vec<output::Section>, HashMap<String, usize>), Error> {
let output_sections = self.merge_sections(&self.objects, resolved_symbols, BASE_ADDR)?;
let latest_section_offset = output_sections.iter().last().unwrap().offset;
let (symtab_section, strtab_section) =
self.make_symbol_section(latest_section_offset, resolved_symbols);
// ... shstrtab の作成 ...
let section_tables = [
// .text, .data, ...
output_sections.as_slice(),
&[
symtab_section.clone(),
strtab_section.clone(),
shstrtab_section.clone(),
],
]
.concat();
Ok((section_tables, section_name_offsets))
}
まず最初に同じセクションを結合し、メモリ上の適切な場所を決めていきます。
この際、アライメント(メモリ境界の調整)も考慮する必要があります。
実際のセクションのマージ処理は次のとおりです。
fn merge_sections(
&self,
objects: &[ELF],
resolved_symbols: &mut HashMap<String, output::ResolvedSymbol>,
base_addr: u64,
) -> Result<Vec<output::Section>, Error> {
// テキストセクションとデータセクションのバイナリデータを保存する配列
let mut raw_text_section = vec![];
let mut raw_data_section = vec![];
// 各オブジェクトファイルのセクションが結合後にどこに配置されるかを記録するマップ
// キー: (オブジェクトインデックス, セクションインデックス)
// 値: 結合後のセクション内でのオフセット
let mut text_offsets = HashMap::new();
let mut data_offsets = HashMap::new();
// 現在の各セクションのオフセット位置
let mut text_current_offset = 0;
let mut data_current_offset = 0;
// 各オブジェクトファイルのセクションを処理
for (obj_idx, obj) in objects.iter().enumerate() {
for (section_idx, section) in obj.section_headers.iter().enumerate() {
match section.name.as_str() {
".text" => {
// テキストセクションの場合、現在のオフセットを記録
text_offsets.insert((obj_idx, section_idx as u16), text_current_offset);
// データを結合
raw_text_section.extend_from_slice(§ion.section_raw_data);
// 次のセクションのオフセットを計算
text_current_offset += section.section_raw_data.len();
}
".data" => {
// データセクションの場合も同様に処理
data_offsets.insert((obj_idx, section_idx as u16), data_current_offset);
raw_data_section.extend_from_slice(§ion.section_raw_data);
data_current_offset += section.section_raw_data.len();
}
_ => {
// TODO
}
}
}
}
// ELFヘッダーとプログラムヘッダーの後に配置(0x100バイト目から)
let text_offset = 0x100;
// ベースアドレスからの適切なアライメントを計算
let text_addr = align(base_addr + text_offset, 4);
// テキストセクションを生成
let text_section = output::Section {
name: ".text".to_string(),
r#type: section::SectionType::ProgBits,
flags: vec![section::SectionFlag::Alloc, section::SectionFlag::ExecInstr],
addr: text_addr,
offset: text_offset,
size: raw_text_section.len() as u64,
data: raw_text_section,
align: 4,
};
// データセクションはテキストセクションの後に配置
let data_offset = text_offset + text_section.size;
// テキストセクションとの領域が被らないように十分な距離を取っておくため、
// データセクションのアドレスは0x10000を加算
let data_base_addr = align(text_section.addr + text_section.size + 0x10000, 4);
let data_section = output::Section {
name: ".data".to_string(),
r#type: section::SectionType::ProgBits,
flags: vec![section::SectionFlag::Alloc, section::SectionFlag::Write],
addr: data_base_addr,
offset: data_offset,
size: raw_data_section.len() as u64,
data: raw_data_section,
align: 4,
};
// データセクションのアドレスが確定したのでシンボルの実際のアドレスを更新
// 結合後のセクション内での位置に基づいて計算する
for symbol in resolved_symbols.values_mut() {
if let Some(&offset) = text_offsets.get(&(symbol.object_index, symbol.shndx)) {
// テキストセクション内のシンボルの場合
// offset: 結合後のセクション内でのオフセット
// symbol.value: 元々のセクション内でのオフセット
symbol.value = text_section.addr + (offset + symbol.value as usize) as u64;
} else if let Some(&offset) = data_offsets.get(&(symbol.object_index, symbol.shndx)) {
// データセクション内のシンボルの場合
symbol.value = data_section.addr + (offset + symbol.value as usize) as u64;
}
}
// 出力セクションの配列を作成
let output_sections = vec![text_section, data_section];
// シンボルの参照先アドレスを修正するリロケーションを適用
self.apply_relocations(&mut output_sections, resolved_symbols)?;
Ok(output_sections)
}
次にシンボルの参照先アドレスを正しく調整するリロケーションをしていきます。
merge_sectionsでシンボルのアドレス値(symbol.value)が確定したので、これを使って参照アドレスを修正してきます。
pub fn apply_relocations(
&self,
output_sections: &mut [output::Section],
resolved_symbols: &HashMap<String, output::ResolvedSymbol>,
) -> Result<(), Error> {
let section_indices: HashMap<String, usize> = output_sections
.iter()
.enumerate()
.map(|(i, s)| (s.name.clone(), i))
.collect();
for (obj_idx, obj) in self.objects.iter().enumerate() {
for reloc in &obj.relocations {
self.process_relocation(
obj_idx,
reloc,
output_sections,
§ion_indices,
resolved_symbols,
)?;
}
}
Ok(())
}
リロケーションでは各シンボル参照の種類に応じて、適切な計算をして参照先アドレスを修正します。
参照の種類に関してはreadelf -rのTypeフィールドで確認できます。
$ readelf -r main.o
Relocation section '.rela.text' at offset 0x178 contains 1 entry:
Offset Info Type Sym. Value Sym. Name + Addend
000000000000 000900000112 R_AARCH64_ADR_PRE 0000000000000000 x + 0
このタイプに応じた参照アドレスの書き換え処理は次のとおりです。
fn process_relocation(
&self,
obj_idx: usize,
reloc: &relocation::RelocationAddend,
output_sections: &mut [output::Section],
section_indices: &HashMap<String, usize>,
resolved_symbols: &HashMap<String, output::ResolvedSymbol>,
) -> Result<(), String> {
match reloc.info.r#type {
relocation::RelocationType::Aarch64AdrPrelLo21 => {
// シンボルインデックスを取得し、範囲チェック
let symbol_index = reloc.info.symbol_index as usize;
if symbol_index >= self.objects[obj_idx].symbols.len() {
return Err(format!("Symbol index out of range: {}", symbol_index));
}
// リロケーション対象のシンボル名を取得
let symbol_name = &self.objects[obj_idx].symbols[symbol_index].name;
// 解決済みシンボルから情報を取得
let resolved_symbol = resolved_symbols
.get(symbol_name)
.ok_or_else(|| format!("Symbol is not resolved: {}", symbol_name))?;
// リロケーションを適用する.textセクションを取得
let text_section_idx = section_indices
.get(".text")
.ok_or_else(|| "Relocation target section not found: .text".to_string())?;
let target_section = &mut output_sections[*text_section_idx];
// リロケーションオフセットが有効範囲内かチェック
if reloc.offset as usize >= target_section.data.len() {
return Err(format!("Relocation offset out of range: {}", reloc.offset));
}
// 命令の実際のアドレスとシンボルのアドレスを取得
let instruction_addr = target_section.addr + reloc.offset;
let symbol_addr = resolved_symbol.value;
// 相対アドレスを計算(シンボルのアドレス - 現在の命令のアドレス + アデンド)
// AArch64のADR命令は、PCからの相対アドレスを使用
let relative_addr =
((symbol_addr as i64) - (instruction_addr as i64) + reloc.addend) as i32;
// リロケーション位置の現在の命令を取得
let pos = reloc.offset as usize;
let instruction =
u32::from_le_bytes(target_section.data[pos..pos + 4].try_into().unwrap());
// ADR命令のオペコードとレジスタ部分を保持
// ADR命令フォーマット: 0bxxx10000 iiiiiiiiiiiiiiiiiiiiiiiiiiiiii ddddd
// x: オペコード、i: 即値ビット、d: 目的レジスタ
let opcode_rd = instruction & 0x9F00001F;
// ADR命令のエンコーディング(ARMv8アーキテクチャリファレンスマニュアルに基づく)
// immhi: 即値の上位19ビット(ビット5-23)
// immlo: 即値の下位2ビット(ビット29-30)
let immlo = ((relative_addr & 0x3) as u32) << 29;
let immhi = (((relative_addr >> 2) & 0x7FFFF) as u32) << 5;
// 新しい命令を組み立て(オペコード+レジスタ+即値)
let new_instruction = opcode_rd | immlo | immhi;
// 計算した新しい命令でバイナリを更新
target_section.data[pos..pos + 4]
.copy_from_slice(new_instruction.to_le_bytes().as_slice());
}
}
Ok(())
}
実行可能ファイルの生成
最後に作成したセクション情報を使って実行可能なELFファイルを生成していきます。
ELFヘッダー、プログラムヘッダー、各種セクション、そしてセクションヘッダーを順番にファイルに書き出しています。
fn write_executable<W: std::io::Write + std::io::Seek>(
&self,
writer: &mut W,
resolved_symbols: HashMap<String, output::ResolvedSymbol>,
section_tables: Vec<output::Section>,
section_name_offsets: HashMap<String, usize>,
) -> Result<(), Error> {
let Some(output::ResolvedSymbol { value: entry, .. }) = resolved_symbols.get("_start")
else {
return Err("sybmol _start not found".into());
};
let elf_header = self.create_elf_header(*entry, §ion_tables);
writer.write_all(&elf_header.to_vec())?;
let program_headers = self.create_program_headers(§ion_tables);
self.write_program_headers(writer, &program_headers)?;
self.write_sections(writer, §ion_tables)?;
writer.seek(SeekFrom::Start(elf_header.shoff))?;
// null section header
self.write_section_header(writer, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0)?;
// section headers
for section in section_tables.iter() {
let name_offset = *section_name_offsets.get(§ion.name).unwrap_or(&0);
let sh_type = section.r#type as u32;
let mut sh_flags: u64 = 0;
for f in §ion.flags {
sh_flags |= *f as u64;
}
let (sh_link, sh_info) = if section.name == ".symtab" {
let strtab_idx = section_tables
.iter()
.position(|s| s.name == ".strtab")
.map(|i| i + 1) // includes null section
.unwrap_or(0) as u32;
let local_sym_count = resolved_symbols
.values()
.filter(|s| s.info.binding == crate::elf::symbol::Binding::Local)
.count() as u32
+ 1; // include null symbol
(strtab_idx, local_sym_count)
} else {
(0, 0)
};
let sh_entsize = if section.name == ".symtab" { 24 } else { 0 };
self.write_section_header(
writer,
name_offset as u32,
sh_type,
sh_flags,
section.addr,
section.offset,
section.size,
sh_link,
sh_info,
section.align,
sh_entsize,
)?;
}
Ok(())
}
まとめ
色々と書きましたが、リンカーの本質の仕事は次の2点です。
- オブジェクトファイルを結合する
- シンボルの参照アドレスを修正して実行可能なバイナリを作成する
やること自体はシンプルとはいえ、リンカーを実装したことで多くのことを学びました。
-
ELFフォーマットの詳細
- ELFヘッダー、セクション、シンボルテーブルなどの構造
- リロケーションの種類と処理方法
-
リンカーの内部動作
- シンボル解決のアルゴリズム
- セクションレイアウトの決定方法
- リロケーションのメカニズム
今後の展望としてはprintfでHello, Worldを出せるように動的リンクを実装していきます。
最終的にはリアルワールドで使われているプログラム(たとえばgitなど)をリンクできるようにしていきたいなと思っています。

Discussion