AWSであらゆるものをモニタリングする方法を考える
はじめに
この記事はDevOps on AWS大全 実践編の一部です。
DevOps on AWS大全 実践編の一覧はこちら。
この記事ではAWSであらゆるものをモニタリングするアーキテクチャを決める流れを解説しています。
具体的には以下流れで説明します。
- 解決したい課題の整理
- 今回使うAWSサービスの整理
- アーキテクチャの策定
- 策定したアーキテクチャで達成できたこと
AWSの区分でいう「Level 400 : 複数のサービス、アーキテクチャによる実装でテクノロジーがどのように機能するかを解説するレベル」の内容です。
この記事を読んでほしい人
- DevOpsエンジニアがアーキテクチャを決めるときにどのような思考フローを踏んでいるか知りたい人
- AWSであらゆるものをモニタリングするアーキテクチャを知りたい人
- AWS Certified DevOps Engineer Professionalを目指している人
前回までの流れ
こちらの記事でAWSを使ってると出てくる様々なログを整理して分析するアーキテクチャを策定しました。
解決したい課題の整理
現在、解決したいと思っている課題は以下になります。
- 各種サービスのモニタリングを行いたい
- モニタリングしているなかで異常があれば検知したい
- モニタリングしているなかで異常があれば通知したい
- モニタリング状況をわかりやすく見えるようにしたい
ということで、これをどうやって解決するか考えていきましょう。
今回使うAWSサービスの整理
今回使う代表的なAWSサービスの概要とベストプラクティスは以下の通りです。
Amazon CloudWatch メトリクス
Amazon CloudWatch メトリクスとは、AWSのサービスやアプリケーションのパフォーマンスや状態を測定するための指標で時間単位で数値化されたデータポイントとして記録され、グラフやダッシュボードで可視化できます。
Amazon CloudWatch メトリクスを使うことで、AWSのリソースやアプリケーションの動作をモニタリングし、異常や問題を検知してアラームを発生させることができます。
Amazon CloudWatch メトリクスフィルター
Amazon CloudWatch メトリクスフィルターとは、Amazon CloudWatch ロググループに保存されたログイベントに対してパターンマッチングを行い、メトリクスに変換する機能です。
Amazon CloudWatch メトリクスフィルターを使うことで、ログイベントに含まれる特定の値やキーワードを抽出し、数値化してメトリクスとして記録できます。
例えば、ログイベントに含まれるHTTPステータスコードやエラーメッセージなどをメトリクスに変換して、グラフやアラームで利用できます。
Amazon CloudWatch Synthetics
Amazon CloudWatch Syntheticsとは、AWSのサービスやアプリケーションのエンドユーザー体験をシミュレートするための機能で、定期的にウェブサイトやAPIなどに対してリクエストを送信し、レスポンスタイムやエラー率などを測定します。
Amazon CloudWatch Syntheticsを使うことで、実際のユーザーが利用する前にサービスやアプリケーションの可用性やパフォーマンスを確認し、問題を早期に発見して修正できます。
Amazon CloudWatch Anomaly Detection
Amazon CloudWatch Anomaly Detectionとは、AWSのサービスやアプリケーションのメトリクスに対して異常検知を行うための機能で、過去のメトリクスデータから正常な動作パターンを学習し、現在のメトリクスデータと比較して異常な値を検出します。
Amazon CloudWatch Anomaly Detectionを使うことで、予期しない変動や傾向を自動的に検知し、アラームや通知で対応できます。
AWS X-Ray
AWS X-Rayとは、AWSのサービスやアプリケーションの分散トレーシングを行うためのサービスで、サービス間やマイクロサービス間の呼び出し関係やパフォーマンスを追跡し、ビジュアル化します。
AWS X-Rayを使うことで、サービスやアプリケーションの内部動作を詳細に分析し、ボトルネックやエラーなどの原因を特定しやすくなります。
ベストプラクティス
以下は、これらのサービスを使用する際のベストプラクティスです。
| サービス | ベストプラクティス |
|---|---|
| Amazon CloudWatch メトリクス | - コストと用途に応じてメトリクスデータの収集間隔を調整する - カスタムメトリクスを作成する - メトリクスの単位や名前を統一する - メトリクスの期間や統計値を適切に選択する |
| Amazon CloudWatch メトリクスフィルター | - ログイベントのフォーマットを標準化する - メトリクスフィルターのパターンをテストする - メトリクスフィルターの名前や値をわかりやすくする - メトリクスフィルターの数を最小限にする |
| Amazon CloudWatch Synthetics | - ウェブサイトやAPIの重要な機能をカバーする - シナリオの実行頻度やタイムアウトを設定する - シナリオの成功条件や失敗条件を定義する - シナリオの結果をメトリクスやアラームで監視する |
| Amazon CloudWatch Anomaly Detection | - 正常な動作パターンが安定しているメトリクスに適用する - 異常検知モデルの学習期間と評価期間を設定する - 異常検知モデルの感度や信頼区間を調整する - 異常検知モデルの結果をアラームや通知で利用する |
| AWS X-Ray | - X-Ray SDKを利用してサービスやアプリケーションにトレース情報を埋め込む - X-Ray デーモンやエージェントをインストールしてトレースデータを送信する - X-Ray コンソールやAPIでトレースマップやセグメントを分析する - X-Ray サービスマップやグループでサービス間の関係やパフォーマンスを可視化する |
アーキテクチャの策定
ここからはやりたいことを順番に考えながらアーキテクチャを策定していきます。
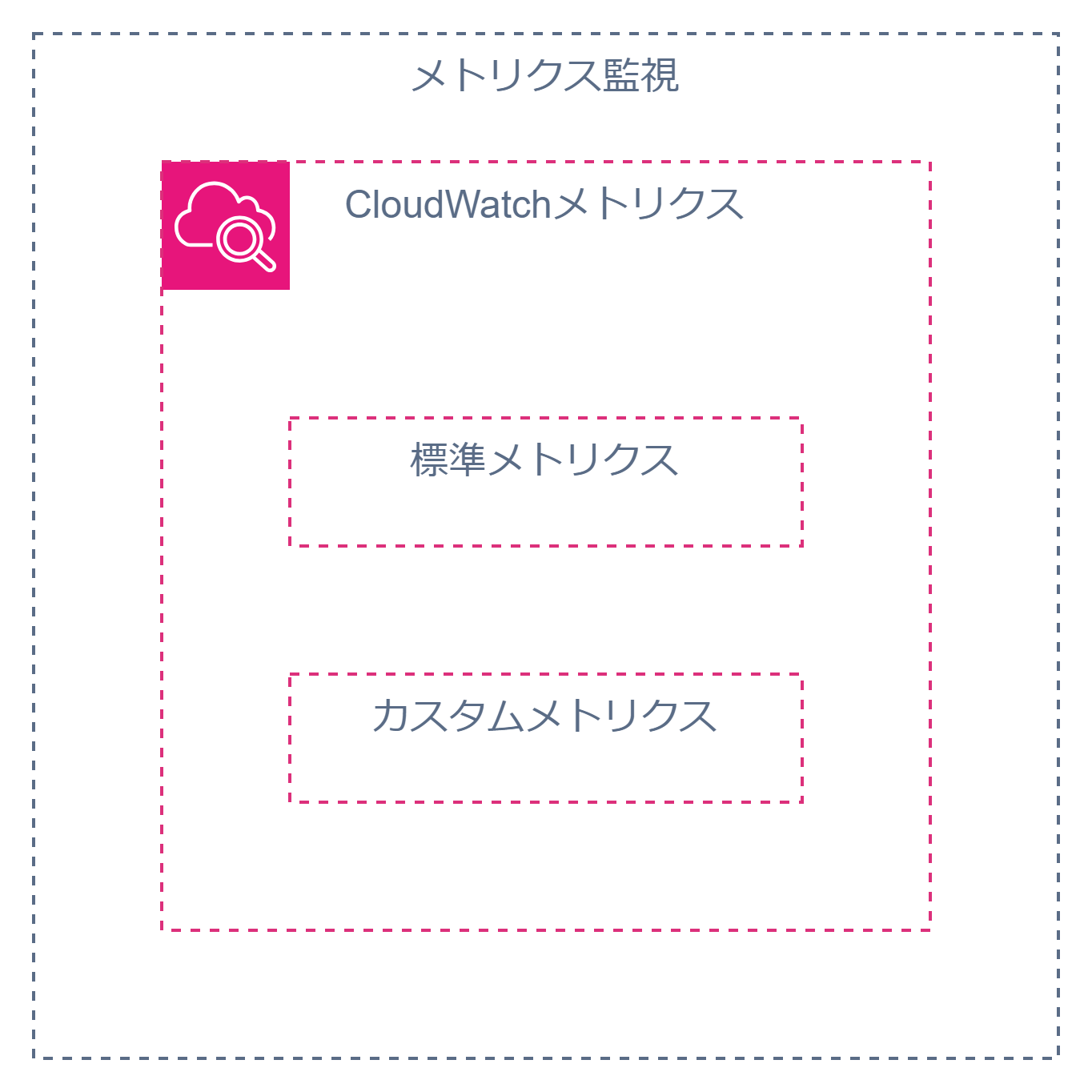
メトリクス監視
システムモニタリングの基本はまず、各種メトリクスを収集してモニタリング対象とすることです。
そして、AWSでメトリクスを集めたければCloudWatchメトリクスを使うのが鉄則です。
CloudWatchメトリクスにはAWSが準備してくれている標準メトリクスと、プラグインやエージェントと組み合わせて使うカスタムメトリクスがあります。
カスタムメトリクス、と書かれるとオプション扱いで基本は使わないように聞こえるかもしれませんがそんなことはありません。
例えばEC2のメモリ使用率や、サーバ内のアプリケーションプロセスの死活など一般的にモニタリングしたい項目がカスタムメトリクスになっています。
そのため、モニタリングの要件を整理しやりたいことの全体像を作ったうえで、どのメトリクスを集める必要があるかを全サービスにわたって検討することが求められます。
これらをまとめると以下のようなアーキテクチャになります。
ログ監視
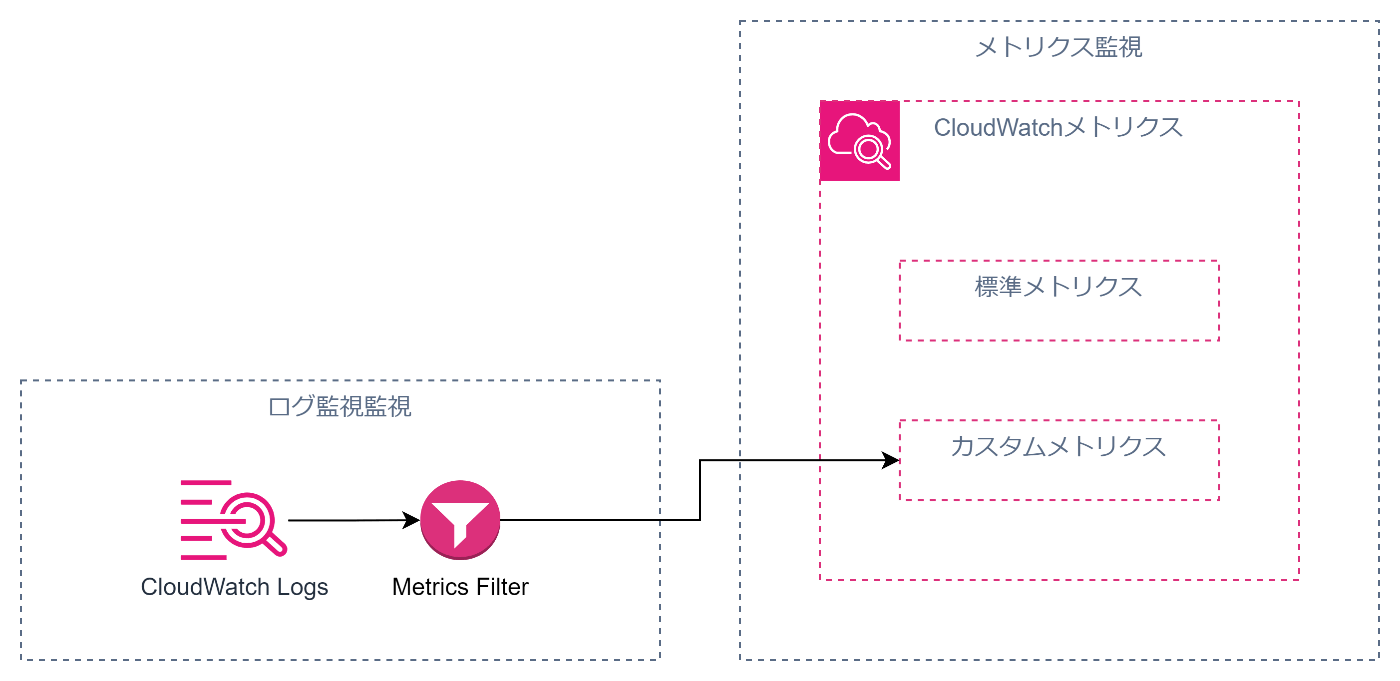
メトリクスを収集してモニタリングできるようになると、次にやりたくなるのがログのモニタリングです。
例えば、バックエンドサーバのアプリケーションでエラーの文言が出たら検知したい、といったことが想定されます。
その場合はCloudWatchLogsのメトリクスフィルタを用いるとよいでしょう。
メトリクスフィルタを用いると、ログに指定した文言が出たときにカスタムメトリクスとしてCloudWatchメトリクスに値をPUTしてくれます。
これにより、ログ監視とメトリクス監視がCloudWatchメトリクスで統合されその後の通知機構などを1つにできるというメリットがあります。
これらをまとめると以下のようなアーキテクチャになります。
外形監視
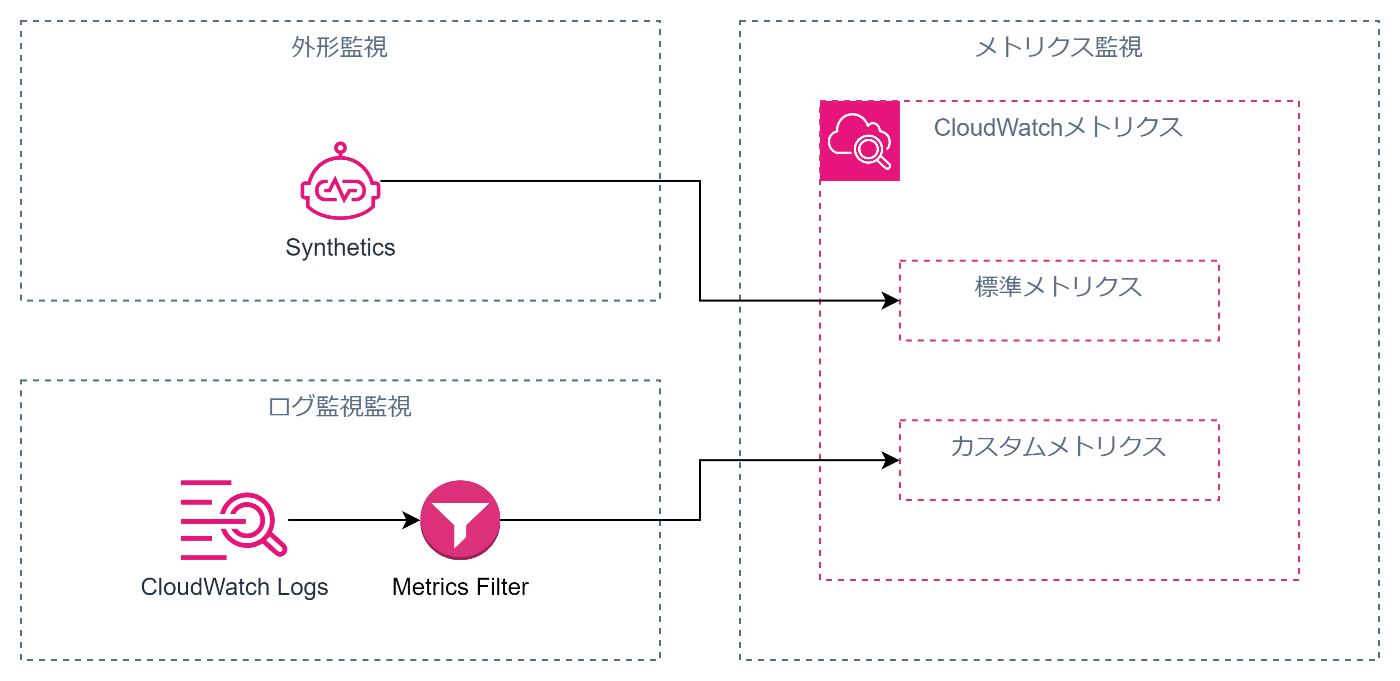
オンプレミスの時代のいわゆる監視、であればメトリクス監視とログ監視で要件充足することがほとんどです。
しかし、クラウドネイティブなシステムでDevOpsで考えると外形監視、すなわちエンドユーザがサービスとして使える状態が維持されているかどうかをきちんと監視する必要があります。
これは多少のサーバが落ちていてもサービスとして使える状態を維持するということにもつながるのでクラウドネイティブなシステムでは非常に重要な考え方です。
AWSのサービスで外形監視をするためにはSyntheticsを利用するとよいでしょう。
Syntheticsで外形をモニタリングし、4XXや5XXなどが発生するとそれをメトリクスとしてCloudWatchメトリクスに連携することができます。
これによって、メトリクス監視、ログ監視、外形監視のすべてのCloudWatchメトリクスに集約することができます。
これらをまとめると以下のようなアーキテクチャになります。
異常検知
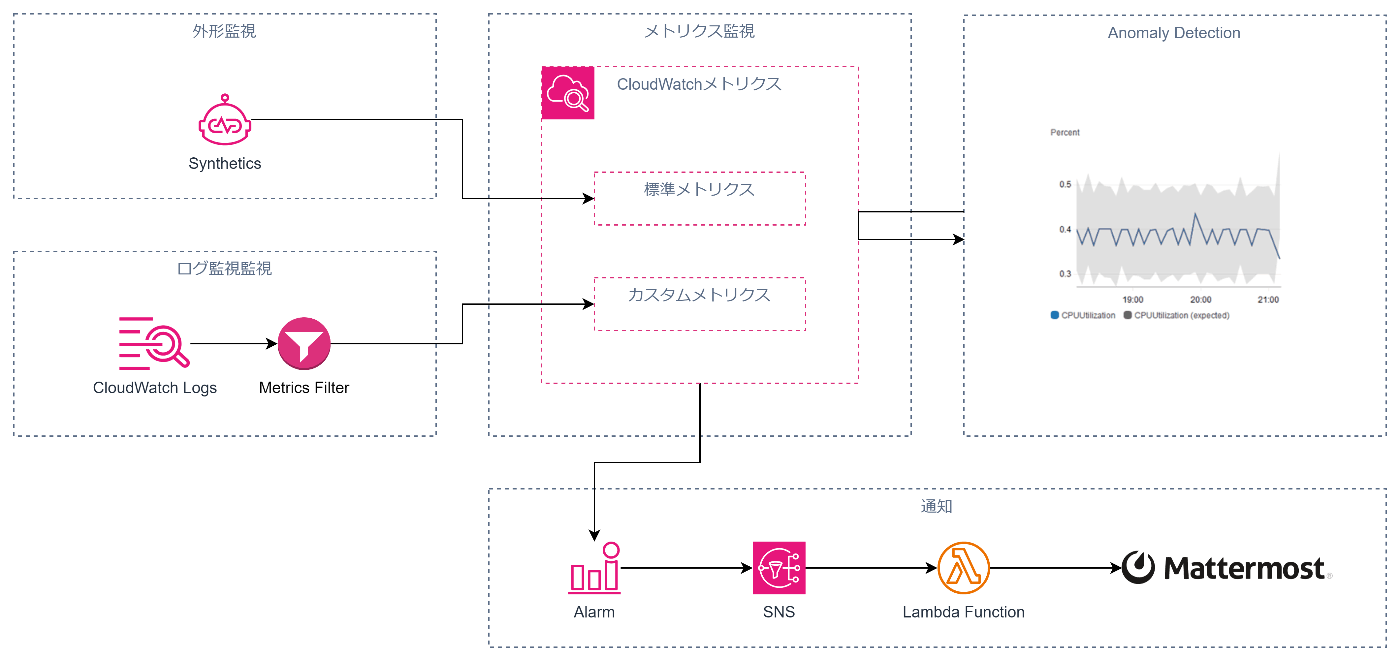
モニタリングにおいて設定した閾値を超えたら通知を行うのは一般的です。
しかし、この方法だと予定された周期的なバーストでもアラートをあげてしまうため不要な通知が飛んでくることがあります。
そこで利用する場面が増えてきているのが機械学習を用いた異常検知です。
メトリクス監視、ログ監視、外形監視のすべてのCloudWatchメトリクスに集約することができた結果Anomaly Detectionを利用することで簡単に、機械学習を用いた異常検知が実現できます。
そして、異常を検知したらCloudWatch Alarmに連携しチャット通知をすることで迅速な対応が可能になります。
これらをまとめると以下のようなアーキテクチャになります。
可視化
最後に、異常を検知したら実際の調査を行います。
また、異常を検知していなくても定期的にシステムの健全性を確認する必要があります。
この時に役立つのがモニタリング状況の可視化です。
ダッシュボードの作成やシステム全体のビジュアライゼーションを利用することでシステムのパフォーマンスや障害ポイントを一目で把握することができます。
前者のために利用するのがCloudWatch Dashboardで、後者のために利用するのがAWS X-Rayです。
これらをまとめると以下のようなアーキテクチャになります。

まとめ
本記事ではAWSであらゆるものをモニタリングするアーキテクチャをまとめました。
今回策定したアーキテクチャで実現できたのは以下の項目です。
- メトリクスのモニタリング
- ログのモニタリング
- 外形のモニタリング
- モニタリング結果の異常検知
- モニタリング状況に応じた通知
- モニタリング状況の可視化
今回は取り上げませんでしたがパフォーマンス関連に特化したサービスもあります。
例えば、EC2ではCompute Optimizer、RDSではPerformance Insightsです。
これらを利用することで適切なサイジングの推奨や長時間クエリの特定が可能になるので必要に応じて組み合わせるとよいでしょう。
次回は障害対応を考えてみたいと思います。
Discussion