AWSでAuto Scaling Groupsを用いた耐障害性を考える
はじめに
この記事はDevOps on AWS大全の一部です。
DevOps on AWS大全の一覧はこちら。
この記事ではAuto Scaling Groupsを耐障害性の観点から超詳細解説しています。
具体的には以下流れで説明します。
- Auto Scaling Groupsのスケーリングポリシーとターミネートポリシー
- Auto Scaling Groupsのライフサイクルとイベント通知
- Auto Scaling Groupsのウォームプール
- Application Auto Scaling
AWSの区分でいう「Level 200:トピックの入門知識を持っていることを前提に、ベストプラクティス、サービス機能を解説するレベル」の内容です。
この記事を読んでほしい人
- Auto Scaling Groupsを採用するときのベストプラクティスを説明できるようになりたい人
- Computeリソースの耐障害性に不安を感じている人
- AWS Certified DevOps Engineer Professionalを目指している人
Auto Scaling Groupsのスケーリングポリシーとターミネートポリシー
Auto Scaling Groupsのスケーリングポリシー
Auto Scaling Groups(ASG)は、アプリケーションのトラフィック変動に迅速に対応するためのスケーリングポリシーを提供しています。スケーリングポリシーは主に以下のタイプがあります。
まずはTarget Tracking Scalingです。
Target Tracking Scalingでは事前に設定したメトリクスの目標値を保ちながら自動的にスケーリングします。
例えば、CPU使用率やネットワークトラフィックの目標値を指定できます。
次はSimple Scaling/Step Scalingです。
Simple Scaling/Step Scaling特定のメトリクスの閾値を超えた場合に、指定された数だけインスタンスを追加または削除します。
例えば、CPU使用率が閾値を超えたら2台追加、といった指定が可能です。
続いてScheduled Actionsです。
Scheduled Actionsはその名の通り、予め定義された時間に定義された台数だけスケーリングします。
そのため、変動が予測しやすい場合に適しています。
例えばサービスローンチのタイミングやキャンペーンを打つタイミングで台数を増やすといったシナリオが考えられます。
最後にPredictive Scalingです。
これは一番新しいスケーリングポリシーで厳密にいうと上3つとは異なる区分です。
上3つは動的なスケーリングの区分ですが、Predictive Scalingは予測スケーリングとして別の区分になっています。
Predictive Scalingは機械学習を使用して CloudWatch からの履歴データに基づいたキャパシティー要件を予測しスケーリングポリシーを定義します。
そのため、トラフィック増加に規則的なパターンがあり、アプリケーションの初期化に長い時間がかかる場合に適しています。
例えば、通常の営業時間にはリソースの使用率が高く、夜間や週末はリソースの使用率が低いといったサイクルがあるトラフィックの処理への適用が考えられます。
Predictive Scalingを利用する際にはベストプラクティスに沿って、まずはキャパシティー要件の予測だけをしてみることが重要です。
これは、Predictive Scalingを有効にしたものの思った通りにスケールせずビジネスに損失を与えることを防ぐためです。
Auto Scaling Groupsのターミネートポリシー
ASGは、インスタンスの終了時にどのインスタンスを優先的にターミネートするかを制御するターミネートポリシーを提供しています。以下は一般的なターミネートポリシーの例です。
まずはDefaultです。
DefaultはASGがどのインスタンスを終了するかに関して自動的な決定を行います。
この場合、ASGは異常なく運用されているインスタンスから順に選択して終了します。
このポリシーはバランスの取れたスケールダウンを実現し、手動の介入が不要な場合に適しています。
次はOldestInstanceです。
OldestInstanceは、最も古い起動時間を持つインスタンスが優先的に終了されます。
これは、長期間稼働しているインスタンスから順に終了させることで、アプリケーションの古いバージョンを終了させたい際によく利用します。
最後にNewestInstanceです。
NewestInstanceでは、最も新しい起動時間を持つインスタンスが優先的に終了されます。
これにより、新しく起動したインスタンスが終了され、古いインスタンスが稼働し続けることが期待されます。
これは、新しいAMIの試験などを行いたい場合によく利用します。
Auto Scaling Groupsのライフサイクルとイベント通知
Auto Scaling Groupsのライフサイクルフック
ASG のライフサイクルフックは、スケーリングアクションの前後にカスタム処理を挿入するためのメカニズムです。
これにより、新しいインスタンスが起動する前や古いインスタンスが終了する前に、特定のスクリプトや処理を実行できます。
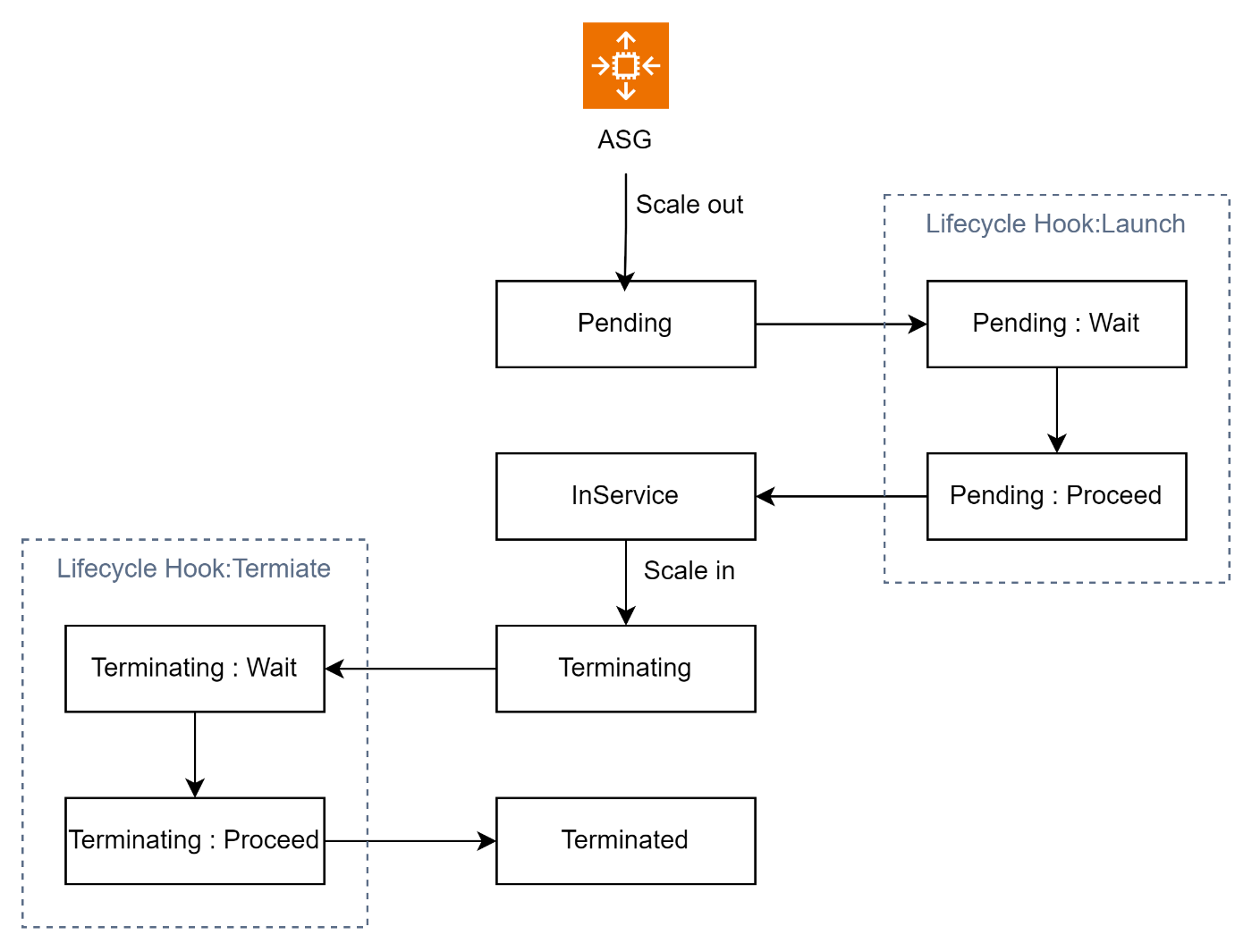
ASGのライフサイクルフックは、主に以下の2つのイベントで構成されます。
1つめがLaunchイベントです。
新しいインスタンスが ASG に追加される際にトリガーされます。
この時点で、新しいインスタンスはまだ完全に運用に組み込まれておらず、処理が途中の状態です。
2つめがTerminateイベントです。
インスタンスがスケーリングアクションや手動で終了される際にトリガーされます。
この時点で、インスタンスはまだ完全に終了していない状態です。
ちなみに、ライフサイクルフックを使用する典型的なケースは以下の通りです。
- 起動スクリプトの実行
- 新しいインスタンスが起動する前後に特定の処理や設定を行いたい場合、ライフサイクルフックを使用して、起動前にスクリプトを実行したり、起動後に設定を適用したりできます。
- 終了前の確認処理の実施
- インスタンスが終了される前に、特定の確認処理を行いたい場合、Terminate イベントに対してライフサイクルフックを設定できます。これにより、終了前の確認やデータのバックアップなどを行うことができます。
ライフサイクルフックを利用する際には以下2つの注意点を考慮することが必要です。
-
タイムアウトの考慮
- ライフサイクルフックにはタイムアウトが設定されており、ユーザーアクションがその時間内に完了しない場合、ASG はデフォルトで処理を続行します。そのため、タイムアウトの設定は慎重に検討する必要があります。
-
冪等性の確保
- ライフサイクルフックの処理は冪等性を考慮する必要があります。同じイベントに対して複数回処理が行われた場合でも、安全に実行できるように設計することが重要です。
ライフサイクルフックを利用することで、ASG のスケーリングアクションにおいて追加のカスタム処理を組み込むことが可能となり、アプリケーションの特定の要件や条件に応じた柔軟な管理が実現できます。
Auto Scaling Groupsのイベント通知
ASGは、スケーリングイベントや状態変更に対してSNSトピックやEventBridge、Lambda関数に通知を送ることができます。
これにより、重要なイベントが発生した際に通知を受け取り、迅速に対応できます。
例えば、スケーリングにより新しいインスタンスが起動した場合や、インスタンスのHealthCheckが変化した場合などです。
Auto Scaling Groupsのウォームプール
ASGのウォームプールは、インスタンスが追加される前に、事前に起動しておくプールのことを指します。
これにより、インスタンスが必要になったときに素早く対応でき、起動にかかる時間を最小限に抑えることができます。

ASGのウォームプールは、スケーリングアクションがトリガーされた際に、即座に使用可能な事前に起動したインスタンスのプールです。
通常、ASGは新しいインスタンスを起動する際に起動までの時間がかかるため、ウォームプールを使用することで、遅延を最小限に抑え、システムの応答性を向上させることができます。
そのため、ウォームプールは、以下のようなシナリオで有用です。
- 予測不可能なトラフィックの急増
- 予測できないトラフィックの急増が発生した場合、ASGはウォームプールから追加のインスタンスを素早く起動してトラフィックに対応します。
- スパイクが発生するイベント
- 特定のイベントやキャンペーンなどで一時的にトラフィックが急増する場合、ウォームプールを使用してスムーズに対応できます。
- 定期的なスケールイン/スケールアウト
- 一定の期間でスケールインやスケールアウトが発生する場合、ウォームプールを用意して起動までの待ち時間を短縮します。
なお、ウォームプールを利用する際には性能要件を明確に定義することがベストプラクティスです。
なぜなら、ウォームプールのコストは、インスタンスの実行時間に応じて発生するため必要以上に長時間インスタンスを起動しておくと、余分なコストがかかるからです。
Application Auto Scaling
Application Auto Scalingは、Auto Scalingを更に拡張し、Elastic Load BalancerやDynamoDBなどのAWSマネージドサービスに対しても自動的なスケーリングを提供します。
Application Auto ScalingもASG同様に、ターゲットトラッキングスケーリングやスケーリングポリシーを使用して、自動的なスケーリングを実現します。
これにより、AWSサービス全体で一元的かつ効率的なスケーリングが実現され、クラウドネイティブなアプリケーションの構築が容易となります。
参考までにApplication Auto Scalingで対象とできるリソースの抜粋を以下にまとめました。
| スケーリング対象リソース | 説明 |
|---|---|
| Amazon ECS Services | ECSのサービスのタスク数の自動スケーリング。 |
| Amazon DynamoDB Tables | DynamoDBテーブルのスループットの自動スケーリング。 |
| Amazon Aurora Replicas | Auroraデータベースのリードレプリカの数の自動スケーリング。 |
| Amazon AppStream 2.0 Fleets | AppStream 2.0のフリートの数の自動スケーリング。 |
| Custom Resources | カスタムリソースを使用して、ユーザーが定義したスケーリング対象をサポート。 |
まとめ
この記事ではAuto Scaling Groupsを耐障害性の観点から超詳細解説しました。
- Auto Scaling Groupsのスケーリングポリシーとターミネートポリシー
- Auto Scaling Groupsのライフサイクルとイベント通知
- Auto Scaling Groupsのウォームプール
- Application Auto Scaling
次回は耐障害性を考慮したアーキテクチャ on AWSを考えます。
Discussion