先日、ZennのMarkdownエディタにEmojiの入力補完機能を追加しました。本記事では、この機能の実装方法を解説します。
また、記事中ではCodeMirrorのソースコードを紹介します。CodeMirrorについては、以前に「CodeMirror v6によるZennのMarkdownエディタの作り方」という記事で紹介していますので、あわせてご覧いただければ理解の助けになるかと思います。
入力補完機能の仕様
本機能は、SlackやGitHubなどでおなじみの、:から入力を開始することでEmojiの候補が表示される機能です。:の後に続く文字により、Emojiの候補がインクリメンタルサーチ形式で絞り込まれていきます。最終的に候補を選択すると、Emojiがエディタに入力されます。
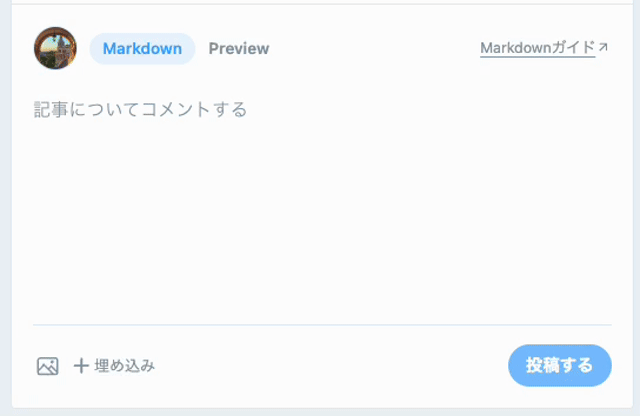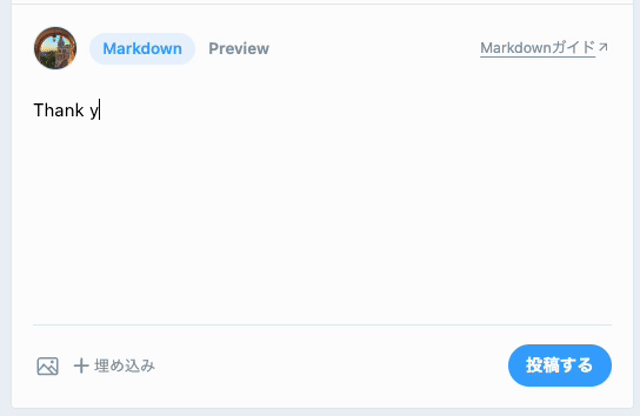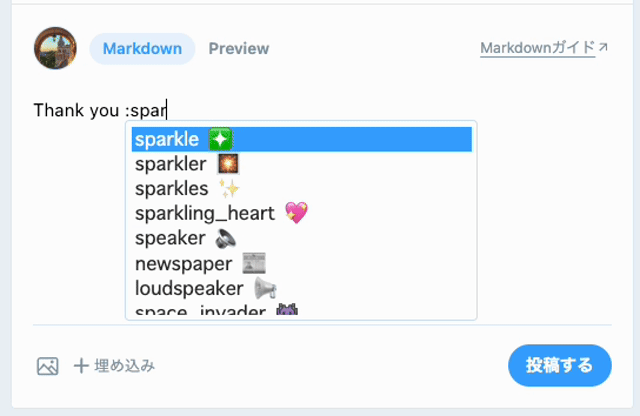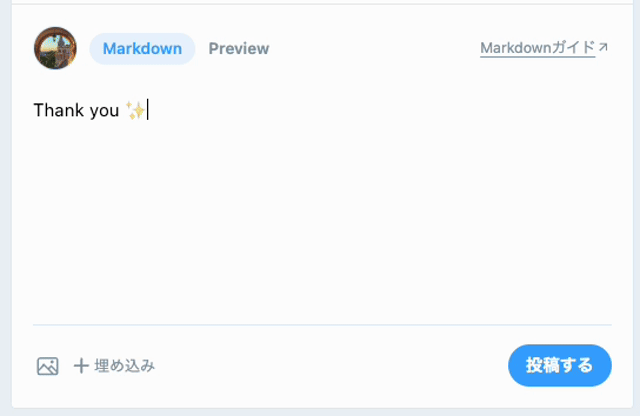
さらに、執筆時点ではZenn独自の詳細仕様として以下があります。
- テキスト入力のじゃまにならないように、
:の直前が「行の先頭」か「空白」か「Emoji」のいずれかであり、:の直後に1文字以上入力された時に、候補を表示する - Zennの独自記法とバッティングを防ぐために、
:が3つ以上連続して入力された場合は、候補を表示しない
入力補完機能の実装方法
CodeMirrorには入力補完機能を実装するために、@codemirror/autocomplete という拡張が提供されています。今回、Emojiの入力候補機能を実装するために、この拡張を利用しました。この拡張では、今回のような単純なインクリメンタルサーチから、プログラミング言語の文法を解析して出力するような複雑なものまで、さまざまな入力補完機能を実装することができます。
今回の実装は、EmojiのKeyとUnicodeのMapを用意し、:の後に入力された文字列にマッチするKeyを持つEmojiを候補として表示するという、シンプルなものです。
以下に実装例を示します。
まずはじめに、「EmojiのKeyとUnicodeのMap」を用意します。view の定義はここでは省きますが、CodeMirrorの実体と考えてください。data は @emoji-mart/data というパッケージを利用しています。Zennではもともと記事編集画面で絵文字のセレクターとして emoji-mart を利用しており、このパッケージで使われている data を都合よく利用できました。
import data from '@emoji-mart/data';
import {
Completion,
CompletionContext,
autocompletion,
} from '@codemirror/autocomplete';
const emojiCompletionOptions: Completion[] = useMemo(() => {
// viewの初期化を優先するため、viewの初期化が終わってからoptionsを生成する
if (!view) return [];
return Object.keys(data.emojis).map((key: keyof typeof data.emojis) => {
return {
label: `:${key}:`, // 入力されたテキストとマッチさせる文字列
displayLabel: key, // 候補に表示する文字列
detail: data.emojis[key].skins[0].native, // 候補に表示する詳細情報(Emoji)
apply: data.emojis[key].skins[0].native, // 選択された時に挿入する文字列(Emoji)
};
});
}, [view]);
次に、入力補完を表示する条件を正規表現で指定します。ルールは仕様の説明で述べたとおりです。returnで返す validFor が重要なオプションで、一度条件にマッチした後で文字を入力したり削除した際に、この正規表現にマッチしている限りは、optionsを再利用するようになり、パフォーマンスが向上します。本実装では、optionsは動的ではないのでパフォーマンスにはさほど影響ありませんが、設定しないよりは良いと思うので設定しました。
// Emojiの入力補完ルール
const emojiCompletions = useCallback(
(context: CompletionContext) => {
const regex = /(?<=^|\s|\p{Emoji})(?<!:{2}):[0-9a-zA-Z_\-+]+:{0,1}$/u;
const word = context.matchBefore(regex);
if (!word) return null;
return {
from: word.from,
options: emojiCompletionOptions,
// wordがこの正規表現にマッチする限り候補を再利用する
validFor: /^:[0-9a-zA-Z_\-+]+:{0,1}$/,
};
},
[emojiCompletionOptions]
);
さいごに、autocompletion関数に、さきほどのルールやオプションを設定して拡張の完成です。
const autocomplete = useMemo(
() =>
autocompletion({
activateOnTyping: true,
icons: false,
override: [emojiCompletions],
}),
[emojiCompletions]
);
あとは view にこの拡張を追加するだけですが、これは前回の記事で紹介しているので省略します。
改善したい点
-
Emojiの入力補完機能のために、Markdownエディタに
dataが追加されたためバンドルサイズが100KBほど大きくなってしまいました。Markdownエディタ自体は遅延読み込みをしているのでページロードには影響ないのですが、ページ内で初めてエディタを表示する際に、多少の引っかかりを感じます。少なくとも入力補完が発動するまでは不要なデータなので、読み込みを遅延させるなどの工夫をしたいところです。 -
入力補完が発動するルールの正規表現で、
uフラグとp{Emoji}を用いて、直前がEmojiかどうかを判定していますが、これは複数のEmojiを組み合わせたコードの場合はマッチすることができません。ES2024で導入される予定のvフラグとp{RGI_Emoji}を用いることで、この問題は解決される予定です。こちらの記事[1]が参考になりました。
おわりに
SlackやGitHubなどで :emoji: 記法を使い慣れている方が直感的に使えることを目指して実装しました。Zennでのコミュニケーションに、ささやかな彩りや楽しさが増えることを願っています。
本機能に関するフィードバックはコメント欄かzenn-communityからお寄せください 😃

Discussion