dyoshikawaです。
Zenn(Railsバックエンド+PostgreSQL+Google Cloud)において、ローカル開発環境での効率的なデバッグ・検証を可能にする目的でPostgreSQL Anonymizer拡張を導入しました。
先に全体構成です。
Cloud Run Jobを起動し、ダンプ用のCloud SQLクローンを作成し、クローンDBのデータをマスクしてダンプを出力するという構成になります。
以下、PostgreSQL Anonymizer自体の簡単な紹介やこの構成に至った経緯を書いていきます。
PostgreSQL Anonymizerとは
PostgreSQLデータベースのデータを匿名化・仮名化するための拡張機能(PostgreSQL extension)です。主に個人情報や機密データを扱うシステムで、開発・テスト・データ分析などの目的で「個人を特定できない形」にデータを変換したい場合に利用されます。
テーブルやカラム単位で匿名化ルールを指定でき、名前をランダムな文字列に置き換える、メールアドレスをマスキングする、日付をシフトするなどが実現できます。SQLコマンドや関数で匿名化処理を実行可能なPostgreSQLの拡張機能として動作し、データベース全体または特定のテーブルのみを匿名化することができ、ランダマイズ、マスキング、null化、ハッシュ化、置換、データ削除など、多様な匿名化手法に対応しています。また、SELECT時に一時的にマスキングを適用するダイナミックマスキング機能により、本番データを変更することなく匿名化したデータを閲覧することが可能です。
PostgreSQL Anonymizer導入の動機
開発環境に本番DBのデータをロードしてテストを可能にしたいが主な動機でした。
機微な情報を含む本番データをそのまま各開発者の端末にダウンロードしてローカル環境のDBにimportすることはセキュリティの観点から避けるべき運用です。この点、PostgreSQL Anonymizerを導入・設定することにより、機微な情報はマスクして利用しつつ、本番のデータやレコード数でしか再現しづらい不具合やパフォーマンスチューニングの分析・改善に役立てられることを期待しました。
本番DBがGoogle Cloud SQLの場合はバージョン1.0.0を使う必要がある
2025年5月現在の最新版はv2.x系ですが、
Cloud SQL for PostgreSQL ではバージョン 1.0.0 が使用されます。
とあるように、Google Cloud SQLではバージョン1.0.0が使用されるので注意が必要です。
また、最新版以外のドキュメントはPostgreSQL AnonymizerのWebサイト上では閲覧できないようなので、v1.0.0に対応したドキュメントは開発元のGitLabリポジトリを見に行く必要があります。
Anonymizerの概要と使い方
基本的にドキュメントに書いてありますが、代表的な3つの機能を紹介します。
Static Masking(静的マスキング)
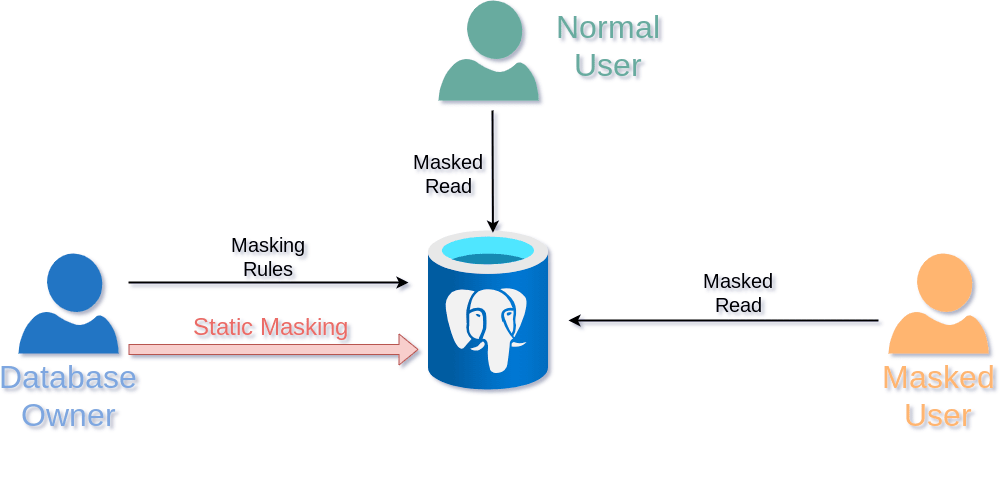
ドキュメントより
-- 拡張機能を有効化
CREATE EXTENSION IF NOT EXISTS anon;
-- `customer.full_name` を `'CONFIDENTIAL'` の固定文字列でマスクするルールを定義
SECURITY LABEL FOR anon ON customer.full_name IS 'MASKED WITH VALUE ''CONFIDENTIAL''';
-- DatabaseにStatic Maskingを適用
SELECT anon.anonymize_database();
Static Maskingを適用するとデータそのものに対してマスク値に上書きします。シンプルで理解しやすいですね。
稼働中の本番DBに適用すると正しいデータが消失することになるので注意してください。
個人的なファーストインプレッションでは用途にピンと来ませんでした。ドキュメントによると
(翻訳)
長年にわたり、ポールは顧客とその購入に関するデータをシンプルなデータベースに収集してきました。最近、彼は最新の販売アプリケーションを導入し、古いデータベースは今や不要になりました。彼はこのデータベースを保存したいと考えていますが、アーカイブする前にすべての個人情報を削除したいと思っています。
というシナリオが使いどころの例として挙げられています。
ちなみに、結果的に今回の目的はStatic Maskingで達成することになりました。
Dynamic Masking(動的マスキング)
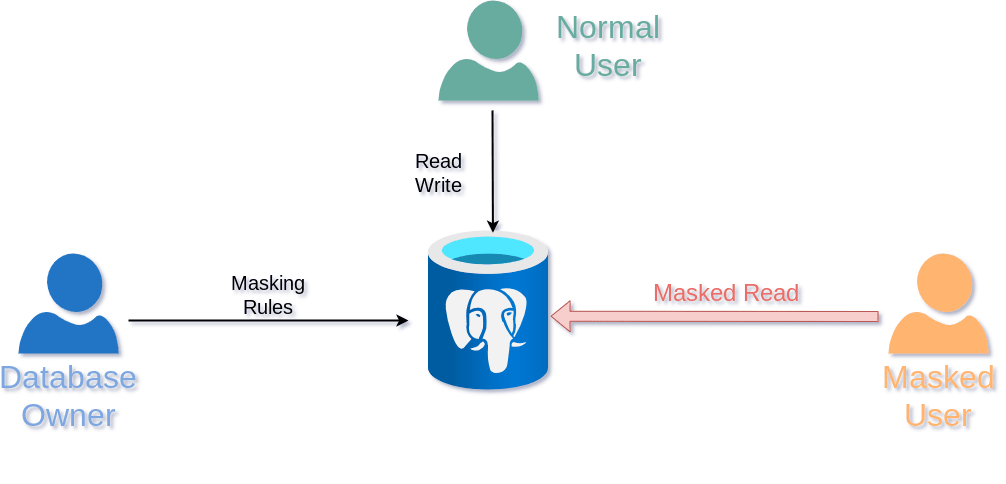
ドキュメントより
-- 拡張機能を有効化
CREATE EXTENSION IF NOT EXISTS anon;
-- DatabaseにDynamic Maskingを適用
SELECT anon.start_dynamic_masking();
-- `customer.full_name` を `'CONFIDENTIAL'` の固定文字列でマスクするルールを定義
SECURITY LABEL FOR anon ON COLUMN customer.full_name IS 'MASKED WITH VALUE ''CONFIDENTIAL''';
-- マスク後のデータだけを読み取れるロールを用意する
CREATE ROLE non_admin LOGIN;
-- `non_admin` ロールに読み取り権限を付与
GRANT pg_read_all_data to non_admin;
-- `non_admin` ロールで読み取った時はデータがマスクされるように設定する
SECURITY LABEL FOR anon ON ROLE non_admin IS 'MASKED';
Dynamic Maskingではマスタにあたるデータには変更が加わりません。
一般権限の開発者や運用担当者が問い合わせや不具合の調査のためにDBにSELECT文を発行するシチュエーションがあると思いますが、Dynamic Maskingを設定することにより、彼らがデータ取得を問い合わせた場合は個人情報をマスクした状態で表示させることができます。こちらは使用イメージが湧きやすいですね。
Anonymous Dumps(匿名ダンプ)
-- 拡張機能を有効化
CREATE EXTENSION IF NOT EXISTS anon;
-- DatabaseにDynamic Maskingを適用
SELECT anon.start_dynamic_masking();
-- `customer.full_name` を `'CONFIDENTIAL'` の固定文字列でマスクするルールを定義
SECURITY LABEL FOR anon ON COLUMN customer.full_name IS 'MASKED WITH VALUE ''CONFIDENTIAL''';
-- マスク後のデータだけを読み取れるロールを用意する
CREATE ROLE anon_dumper LOGIN;
-- `anon_dumper` ロールに読み取り権限を付与
GRANT pg_read_all_data to anon_dumper;
-- `anon_dumper` ロールにDynamic Maskingを適用
SECURITY LABEL FOR anon ON ROLE anon_dumper IS 'MASKED';
# `pg_dump_anon.sh` という固有のシェルスクリプトでダンプを実行
pg_dump_anon.sh -h localhost -U anon_dumper my_db > anonymous_dump.sql
Anonymous Dumpsはマスクされたデータをダンプします。これにより本番DBから機微な情報を除外したデータを開発環境DBにimportすることができます。
今回の目的に合致する機能はこちらでした。
ただし、ドキュメントにおいて、「consistent backup」を重視する場合はStatic Maskingを使用することを推奨する旨が記載されています。
IMPORTANT: due to its internal design, pg_dump_anon.sh MAY NOT produce a consistent backup.
Especially if you are running DML or DDL commands during the anonymous export,
you will end up with a broken dump file.
If backup consistency is required, you can simply use static masking and then
export the data with pg_dump. Here's a practical example of this approach:
https://gitlab.com/dalibo/postgresql_anonymizer/-/issues/266#note_817261637
この文脈におけるconsistent backup(バックアップの一貫性)の具体的に意味するところは正直完璧に理解できていないのですが、「Anonymous Dumps機能は pg_dump に比べると不安定である」というニュアンスを読み取りました。
そして、実際に検証したところ、 レコードのデータにSQL文字列が含まれていた場合、リストア時にそのSQLが実行されてしまう(無害化されていない) という不具合を確認したため、本機能の使用は断念し、Static Maskingを使う方法を採用することにしました。
anon.init() でfake関数が使用可能に
anon.init() を実行することでプリセットのfake関数が使用可能になります。
SELECT anon.init();
anon スキーマ下のテーブルにfake用のデータが作成されます。非常に小さいデータ量のためサイズ圧迫の問題は生じないでしょう。
SECURITY LABEL FOR anon ON COLUMN customer.company_name IS 'MASKED WITH FUNCTION anon.fake_company()';
マスクルールの定義
常に固定値を返したい場合は MASKED WITH VALUE を使います。
-- 常に `'CONFIDENTIAL'` を返す
SECURITY LABEL FOR anon ON COLUMN customer.full_name IS 'MASKED WITH VALUE ''CONFIDENTIAL''';
より柔軟に値を設定したい場合は関数を使います。 MASKED WITH FUNCTION で定義します。
-- 10文字のランダム文字列を返す
SECURITY LABEL FOR anon ON COLUMN customer.full_name IS 'MASKED WITH FUNCTION anon.random_string(10)';
プリセットで anon スキーマに関数が用意されていますが、これで用途を満たせない場合は自前でカスタム関数を定義することもできます。
-- カスタム関数を配置するスキーマを作成
CREATE SCHEMA IF NOT EXISTS anon_custom;
-- `{ランダム文字列}@example.com` のメールアドレスを生成するカスタム関数を定義
CREATE OR REPLACE FUNCTION anon_custom.email()
RETURNS TEXT AS $$
SELECT RETURN lower(anon.random_string(15)) || '@example.com';
$$ LANGUAGE sql;
-- マスクルールに `anon_custom.email()` を使用して定義
SECURITY LABEL FOR anon ON COLUMN users.email IS 'MASKED WITH FUNCTION anon_custom.email()';
Dockerを使ったローカルDB構築時のTips
postgres DockerイメージをベースにPostgreSQL Anonymizerを導入するには以下のようにDockerfileを構成します。
# PostgreSQL v17を指定
ARG PG_VERSION=17
# x86_64 アーキテクチャを指定
FROM postgres:${PG_VERSION} AS builder
# postgresql-anonymizer 1.0.0をインストール
RUN git clone --branch 1.0.0 --depth 1 \
https://gitlab.com/dalibo/postgresql_anonymizer.git /tmp/postgresql_anonymizer \
&& cd /tmp/postgresql_anonymizer \
&& make extension \
&& make install \
&& rm -rf /tmp/postgresql_anonymizer
最新版であればaptコマンドで簡単にインストールできるのですが、今回は1.0.0が必要なのでソースビルドしています。
注意点として、 --platform=linux/x86_64 を指定せずにM1などAppleチップのMacでイメージをビルドしようとすると apt-get update の段階で
N: Skipping acquire of configured file 'main/binary-arm64/Packages' as repository 'http://apt.dalibo.org/labs bookworm-dalibo InRelease' doesn't support architecture 'arm64'
というエラーが発生しました。PostgreSQL AnonymizerはARMアーキテクチャには対応していないようなので、 --platform=linux/x86_64 を指定してビルドする必要があります。
また、上記DockerfileでDocker Composeでコンテナを起動した際に
! db The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested 0.0s
という警告が出る場合、
services:
db:
platform: linux/x86_64 # 指定
build:
context: .
dockerfile: ./Dockerfile
# ...
docker-compose.yml に明示的に platform: linux/x86_64 を指定することで解消しました。
Cloud SQLでPostgreSQL Anonymizerを有効化する
Cloud SQLでは、
- Cloud SQLインスタンスを編集し、データベースフラグ
cloudsql.enable_anonをonに設定 -
CREATE EXTENSION IF NOT EXISTS anon CASCADE;の実行
を行うことでPostgreSQL Anonymizerを有効にできます。
RubyonRailsマイグレーション特有のTips
Railsアプリケーションにおいては次のようなマイグレーションファイルを作成してPostgreSQL Anonymizerを有効化することになります。
class EnableAnon < ActiveRecord::Migration[8.0]
disable_ddl_transaction!
def up
execute "CREATE EXTENSION IF NOT EXISTS anon CASCADE;"
end
def down
execute "DROP EXTENSION IF EXISTS anon CASCADE;"
execute "DROP SCHEMA IF EXISTS anon CASCADE;"
end
end
anon スキーマは拡張有効化時に自動的に有効化されるため、down時にはこれらの削除も必要です。また、pgcrypto 拡張も依存拡張として自動的に有効化されます。
ただ、デフォルトの挙動だとマイグレーション時のschema.rbの更新で次の2つの問題が生じます。
anon が依存する pg_crypto が後ろに記述される問題と解決策
CREATE EXTENSION anon CASCADE; を実行すると自動的に anon が依存している pgcrypto 拡張も有効化されます。
これにより、マイグレーションすると schema.rb にアルファベット順で
create_schema "anon"
create_schema "pg_crypto"
が記述されるのですが、 rails db:schema:load でDBを構築する際、先に anon 拡張を有効化しようとして依存先の pg_crypto がないためエラーになってしまいます。解決するには pg_crypto を先に有効化する必要があります。
これの対処に頭を悩ませたのですが、 schema.rb の更新時に anon より pgcrypto が先に記述されるよう、schema_dumperをモンキーパッチすることにしました。
module ActiveRecord
module ConnectionAdapters
module PostgreSQL
class SchemaDumper
private
# パッチしているメソッド
# https://github.com/rails/rails/blob/main/activerecord/lib/active_record/connection_adapters/postgresql/schema_dumper.rb#L8
def extensions(stream)
extensions = @connection.extensions
if extensions.any?
stream.puts " # These are extensions that must be enabled in order to support this database"
# pgcryptoを先頭に配置し、残りの拡張機能をアルファベット順にソート
pgcrypto, others = extensions.partition { |ext| ext == "pgcrypto" }
(pgcrypto + others.sort).each do |extension|
stream.puts " enable_extension #{extension.inspect}"
end
stream.puts
end
end
end
end
end
end
モンキーパッチファイルの配置などは次のクックパッドさんの記事を参考にしました。
anon スキーマの作成が記述されてしまう問題と解決策
CREATE EXTENSION anon CASCADE; を実行すると自動的に anon スキーマも作成されます。 schema.rb には
create_schema "anon"
enable_extension "anon"
が追加されるのですが、この記述だとCI環境などで rails db:schema:load でDBを初期構築する際に
-
anonスキーマが作成される -
anon拡張が有効化される(そして自動的にanonスキーマを作成しようとする)
となり、 anon スキーマを2重に作成しようとしてエラーになってしまうのです。
こちらもモンキーパッチで対処することにしました。 schema.rb の更新時に anon スキーマを無視するよう、schema_statementsメソッドをモンキーパッチしました。
module ActiveRecord
module ConnectionAdapters
module PostgreSQL
module SchemaStatements
# パッチしているメソッド
# https://github.com/rails/rails/blob/main/activerecord/lib/active_record/connection_adapters/postgresql/schema_statements.rb#L201
def schema_names
names = query_values(<<~SQL.squish, "SCHEMA")
SELECT nspname
FROM pg_namespace
WHERE nspname !~ '^pg_.*'
AND nspname NOT IN ('information_schema')
ORDER by nspname;
SQL
# `anon` スキーマと `mask` スキーマを除外する
# `anon` はanon拡張有効化時に作成される
# `mask` はDynamic Masking有効化時に作成される
names.reject { |name| ["anon", "mask"].include?(name) }
end
end
end
end
end
Dynamic Maskingも使用する場合は、 mask スキーマも無視リストに入れた方が良いと思います。
このパッチにより、
enable_extension "anon"
だけが出力されるようになり解決します。
Google Cloud上の構成
Google Cloud上では次のような構成を組みました。
Cloud Run Jobでバッチ用のインスタンスを起動し、以下を実施するシェルスクリプトを走らせるようにしています。
- プライマリCloud SQLインスタンスからクローンCloud SQLインスタンスを作成する
- クローンCloud SQLインスタンスにStatic Maskingを適用する
-
pg_dumpを実行し、取得したダンプファイルをGCSバケットにアップロードする - クローンCloud SQLインスタンスを削除する
実行時間は20分〜30分程度でしょうか。完了したら、GCSバケットからマスク済みのダンプファイルを取得して、 pg_restore でローカル開発環境のDBにリストアすることができます。
まとめ
本記事では、PostgreSQL Anonymizerを使って本番データベースの機微情報をマスキングすることで、開発環境に比較的安全にリストアする方法を紹介しました。
PostgreSQL AnonymizerはGoogle Cloud SQLでは現状v1.0.0のみがサポートされている点に注意が必要です。本拡張には主にStatic Masking、Dynamic Masking、Anonymous Dumpsという3種類の機能がありますが、v1.0.0時点のAnonymous Dumpsは挙動が不安定と思われます。今回はStatic Maskingを採用して匿名ダンプを実現しました。
実際の適用について、Dockerを使ったローカル環境構築方法やCloud SQLでの有効化手順に触れました。特にRailsにおけるマイグレーションで schema.rb 更新時の課題があり、モンキーパッチで対応しました。Google Cloud上のシステム構成としては、Google Cloud上でCloud Run JobとCloud SQLクローンを組み合わせることでマスクされたダンプの出力を実現しました。
本番環境のデータ量や構造を維持しつつ機微情報をマスクして開発・テスト環境で使用できるようになったので、これから検証用途に活用していきたいと思います。
以上、参考になれば幸いです。

Discussion