

Zennチームのdyoshikawaです。
オープンセミナー広島2024にて、「エンジニア向けコミュニティZennの開発チームを支える自動化の仕組み」というタイトルで登壇させていただきました。
参加者は上記Connpassより57人でした。
イベントのテーマが「XRE - エンジニアを支える組織」とのことで、他の登壇者はSREの方が多く、SREでない自分は何を話そうかなと考えていたのですが、主催より
すごく広く捉えて「エンジニアを支える何か」みたいなテーマに収まっていれば大丈夫ですよ
とのことだったので、このようなタイトルで登壇させていただきました。
SpeakerDeckはこちらです。
今回は原稿を一言一句作り込んで話しましたので、せっかくなので少し手直した上で記事として投稿してみたいと思います。
自己紹介など

それでは始めさせていただきます。
クラスメソッド株式会社Zennチームの吉川と申します。本日は「エンジニア向けコミュニティZennの開発チームを支える自動化の仕組み」というテーマで話をいたします。よろしくお願いします。

スライドは、すでにSpeakerDeckにもアップしています。お手元でも資料を確認したい方は、本イベント、オープンセミナー広島2024のConnpassのページの下の方に「資料」という欄がありますので、そこからSpeakerDeckのページをお開きください。
では、始めていきます。

自己紹介です。
dyoshikawaというハンドルネームで活動しております。広島市に住んでいるソフトウェアエンジニアです。
現在はフロントエンドNext.js バックエンドRuby on Rails インフラはGoogle Cloudを使ってZennというサービスの開発をしております。それ以前はAWS LambdaやDynamoDBをバックエンドに使ったAWSサーバレス、バックエンドNode.js、PHP Laravel、Vue.jsなどを使って開発しておりました。
資格は応用情報技術者、AWS Security Specialtyなど合格しております。

最近は生成AI活用にも取り組んでおり、Google Cloud Generative AI Summit Tokyo 2024 秋の「生成 AI Innovation Awards」のファイナリストとして、最終審査のピッチ大会に登壇しました。
聞いている人は200か300人くらいいたんじゃないかと思います。めちゃくちゃ緊張して、出番の1つ前になったときはなぜか咳が止まらなくなったのですが、なんとか話しきることができました。結果は入賞ならずで残念でしたが、とてもよい経験をさせていただきました。
ここで発表した事例については、後ほど、具体的な取り組みのセクションで紹介いたします。

今日お話することです。
まずはZennについての紹介と、そもそもなぜ自動化に取り組むのか、取り組むべきなのかについて話をいたします。
続いて、具体的な取り組みを紹介いたします。
ソースコードに対してLinter、Formatter、型チェックによる静的解析の導入、テストの自動化、CI/CDの整備、そして生成AIの活用について紹介いたします。
最後に、さらに自動化していくために必要なことと、全体のまとめについて話をいたします。
はじめに
Zennの紹介

それでは、まずはZennについて紹介します。
少し質問させてください。ここで、Zennをご存知の方はいらっしゃいますでしょうか?聞いたことがあるレベルでも構いません。
(ほとんどの方から手が上がりました)
ありがとうございます。

では、Zennで記事を読んだり、実際に書いたりしたことがある方はいらっしゃるでしょうか?
(7、8割くらいの方から手が上がりました)
ありがとうございます。

Zennはエンジニアのための情報共有コミュニティです。
実際見ていただいた方がイメージしやすいと思いますので、差し支えなければ、話を聞きながら、お手元の端末で zenn.dev にアクセスしてみていただけると幸いです。
Zennでは、問題解決を振り返って書く記事、記事よりさらにまとめた分量を有料販売できるBook、自分用のメモや他ユーザとの議論ができるScrapの3種類の投稿形式で知見を発信できます。記事の著者が金銭的な対価を得ることもできます。
また、活発なコミュニティも強みです。月間PV数は1300万以上、会員数は12万以上、そして企業や組織が投稿する記事をまとめることができるグループ機能であるPublicationの数は900以上にのぼります。

Zennは、2020年にCatnoseさんという方の個人開発サービスとしてリリースされました。
その後、2021年にクラスメソッドが運営会社となりました。
そして現在はエンジニア3名、デザイナー1名、ビジネス1名、オペレーター1名の6人のチームで運営しています。
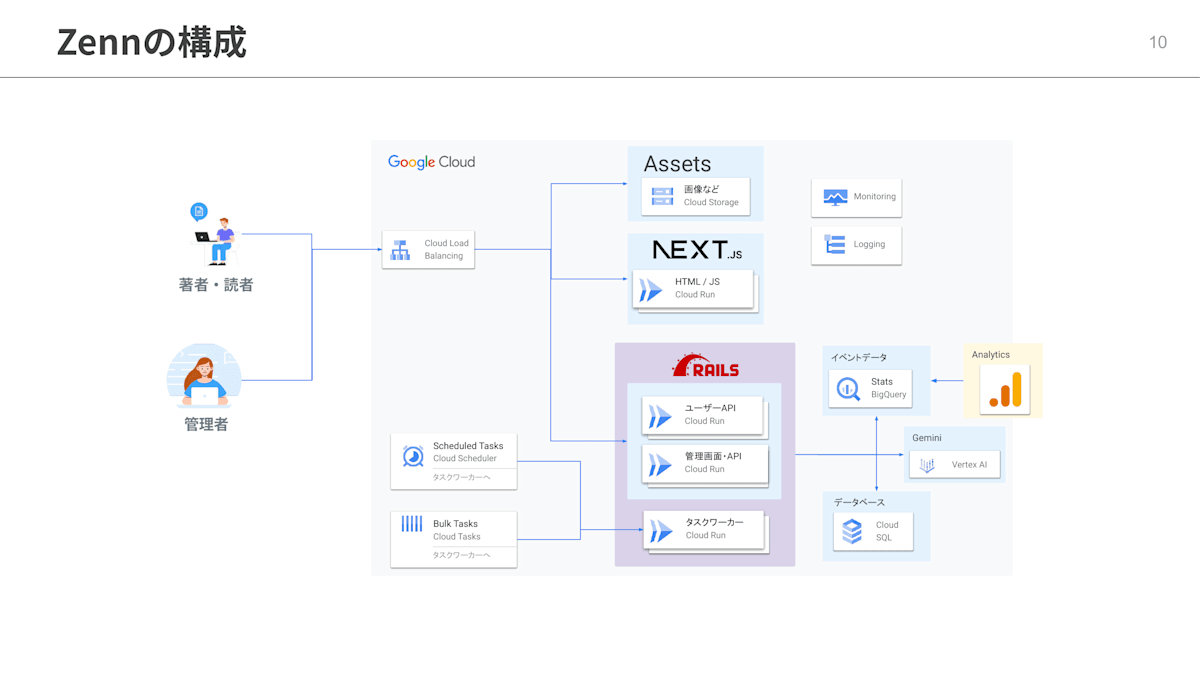
Zennの技術構成です。
Zennは主にGoogle Cloud上に構築されています。コンピューティングにはCloud Runを使用し、フロントエンドはNext.jsを、バックエンドはRuby on Railsのアプリケーションをホスティングしています。バッチ処理のためのタスクワーカーもRailsとCloud Runです。データベースはCloud SQLにホスティングしています。
この図には載せられていませんが、最近はCDNやWAFについてはCloudflareを導入してGoogle Cloudと併用しています。
なぜ自動化するのか

具体的な取り組みのセクションに入る前に、そもそもなぜ自動化するのか?について私の考えをお話します。
まず、自動化できる作業、特に定型的な作業については、単純に人間がやるよりも「速くて正確」です。仕組みが完成すれば、反復的な定型作業は瞬時に完了できるようになります。人間と違ってうっかりミスをすることもありませんし、疲労や集中力低下の影響を受けることもありません。
また、開発や運用の自動化を進めれば進めるほど、チームの規模はそのままに生み出す価値をスケールすることができると考えています。

自動化により時間が生み出されることで、より多くの創造的なタスクに取り組むことができると考えています。
もし、目先の定型的な作業で1日の大半が埋まってしまうと、その既存業務に追われることでフローを改善する時間がどんどん取れなくなっていきます。新たな課題が生じた際も、じっくりと検討するゆとりがないので、場当たり的に人力で対処することになりがちです。これではさらに定型的な作業が増加する悪循環になってしまいます。

逆に、自動化により定型作業に割く時間を圧縮できれば、浮いた時間を検討に当てることができるようになります。新しい課題が浮上しても、その場しのぎ的な対処に留まらない仕組みづくりができるようになります。
また、新しい課題だけでなく、すでに自動化の仕組みを作ってある既存業務のさらなる効率化にも着手できます。

「いや、現実世界の業務はそんなに単純じゃないよ」という向きもあるかもしれません。
私自身もそうだと思います。
例えば、ある対象を自動化しようと思えばできるが、それがあまりにも大変過ぎて、自動化で削減できる工数より仕組みづくりの工数の方が大きい場合はどうでしょうか?また、単純作業だが、1度しか行わない可能性がある作業をすぐに自動化すべきでしょうか?
これらの問いに対しては、対象とタイミングの選定に注意すれば、少ない労力で高い効果を得られるのではないかと考えています。
作業を分解し、自動化することで費用対効果が高い作業を発見する、これが対象の選定です。例えば、コードレビューのすべてを自動化するのは難しいですが、コーディングスタイルのチェックについてはLinterやFormatterを使っての自動化が容易です。
同じ作業を繰り返すことが確定してから自動化を検討する、これがタイミングの選定です。テストやデプロイについては繰り返し行うことが確定しているため、最初から自動化を視野に入れるのがいいでしょう。一方で、例えば、ユーザからの問い合わせを受けてのデータパッチ対応などに対して、最初の1回目からボタン一発でデータを更新できる管理機能を用意すべきかは微妙です。何度か同じことがあり、今後も繰り返しあるだろうと判断したタイミングで仕組みを作り始めるのが良いと思います。
この発表では、エンジニア組織においてほぼ確実に導入コストよりリターンが上回ると合意が取れているような取り組みをメインに据えつつ、Zenn特有に生じた課題も織り交ぜて紹介していきます。
具体的な取り組み

それでは、Zennにおいて実施している具体的な取り組みを紹介します。
コードの静的解析

まずはコードの静的解析です。
ZennのフロントエンドではFormatterとしてPrettier、LinterとしてESLint、そして型チェックをするために言語はTypeScriptを採用しています。
バックエンドではFormatterとLinterを兼ねてRuboCopを採用しています。

FormatterとLinterを導入することで、コードレビューの定型的な観点からのチェックを自動化できます。
コードレビューにおける定型的な観点とは何かというと、コーディングスタイルの統一です。これは機械的にチェックできる項目であるため、人間よりもツールにやらせた方が速くて正確です。

スペース、インデント、改行などの統一をするのがFormatterです。
一般的に、可読性を維持するためにスペースやインデントについてコーディング規約を定めると思いますが、これらを人間のレビューで完全に守らせるのは不可能だと思います。レビュアーがすべての変更コードのスペースを数えるのは労力に見合いませんし、本質的でもありません。
ただ、統一が全くされないと、コードが徐々に読みづらくはなってしまいます。そこで、Formatterを導入することで、非常に低コストかつ確実にこれらの統一をすることができます。

そしていわゆる「書き方」的な観点で統一をしてくれるのがLinterです。
例えば、JavaScript、TypeScriptでは変数定義は var より let もしくは const にするように提案してくれたり、Rubyでは、 if not foo unless foo どちらの条件式でも書けるところを、コード全体でどちらかに統一してくれたりします。
その他にも、未使用変数や冗長なコード、ベストプラクティスから外れるコードを検出してエラーを出してくれるなど、Linterは非常に有用です。

FormatterとLinterでコードレビューの定型的な観点チェックを自動化することで、レビュアーはソフトウェア設計、パフォーマンス、セキュアコーディングといった非定型的な観点に集中できるようになります。
総じて、FormatterとLinterはコードレビューの負荷を下げるものであり、また、コードレビューは開発中に繰り返し行うことが確定しているため、本取り組みは費用対効果が非常に高いといえると思います。

フロントエンドについては、TypeScript言語を採用しているため、さらに型チェックが静的解析に加わることになります。これにより、コードの実行前にかなりのエラーを検出できるようになります。
型チェックは実はテストの一種であり、静的テストといわれます。コードを実行することなくテストをしていることが、「静的」といわれるゆえんです。
一般的に言われる「テスト」は厳密には動的テストになります。こちらはコードを実際に実行する形のテストになります。
Webサービス系のフロントエンドでは動的テストのテストコードをあまり書かず、TypeScriptによる静的テストをベースに、ブラウザからの手動テストと自動E2Eテスト組み合わせるという判断をしている現場が少なくないように感じています。この理由については、Webサービス系のフロントエンドではブラウザAPIへの依存がたくさん生じてモックが大変なことや、バックエンドよりビジネスロジックが少ない、さらに、バックエンドに比べて仕様が安定せず変更が頻繁であることから、相対的にテストを書く価値を感じられにくいのではないかと思っています。
このような事情もあり、現代のフロントエンドアプリケーションの品質保証においてTypeScriptの存在感は非常に大きいと考えています。
また、これは静的型付け言語一般の強みですが、IDE上で正確なコード補完が実現され、開発効率が向上することも、TypeScriptを採用するメリットかと思います。
テストの自動化
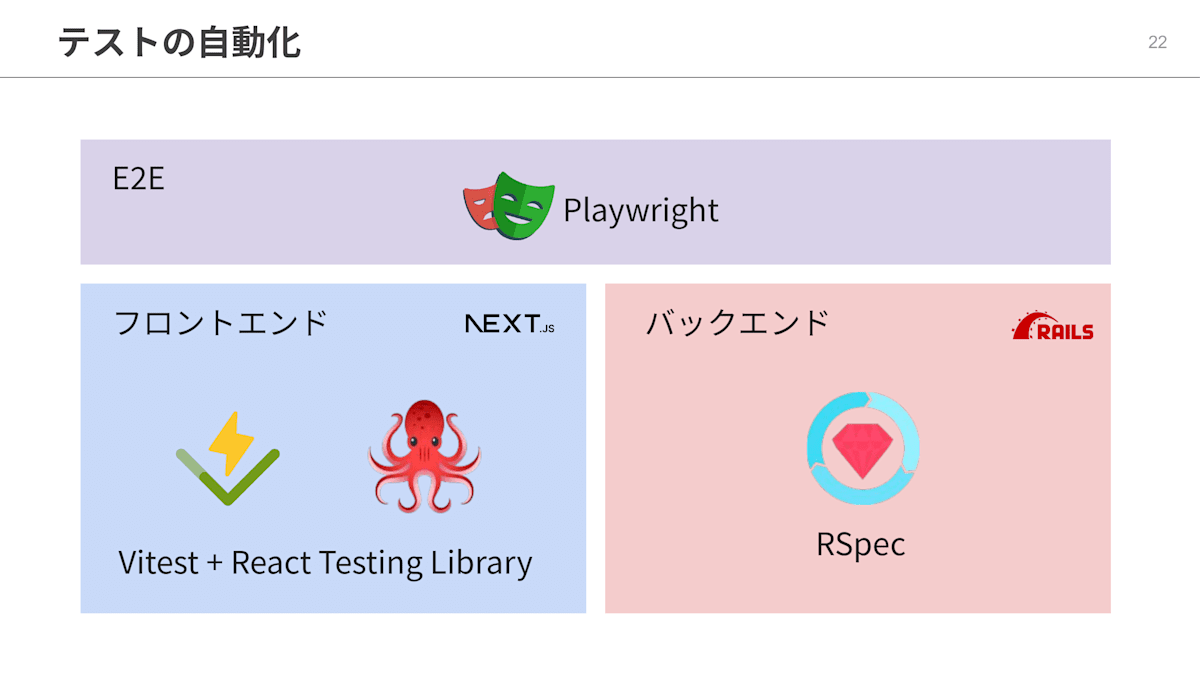
続いての取り組みは、テストの自動化です。
フロントエンドはVitest と React Testing Library、バックエンドはRSpecを使って自動テストを実施しています。
また、フロントエンドとバックエンドを一気通貫でテストするために、E2EテスティングツールとしてPlaywrightを採用しています。

フロントエンドのテストというと、ReactコンポーネントをNode.js環境で描画して行うテストや、コードの変更前と変更後でUIが壊れていないかを確認するビジュアルリグレッションテストなどもありますが、現状、ZennではUtility的な関数やReact Hooksに関するテストに留まっています。
ここは課題感がありますが、ある程度TypeScriptやE2Eテストで品質担保できている部分もあり、現在エンジニア3名ということもあってフロントエンドのテストをなかなか拡充できていないという状況です。

バックエンドテストは、RSpecを使ってModel単位、Controller単位のテストを記述しています。RDBへのReadとWriteを含む振る舞いのテストがほとんどなので、ボリュームとしてはユニットテストよりも結合テストが大きい状態になっています。
フロントエンドに比べるとテストは非常に充実している状態になっています。

そしてE2Eテストです。
これはPlaywrightで実現しています。以前はCypressを使っていたのですが、Cypressの開発元に課金をしないと機能をフルに使うことが難しい点と、PlaywrightがE2Eテスティングツールとして存在感を増してきているタイミングであったことから移行を決断し、1年ほど前に移行しました。
ブラウザを自動操作し、フロントエンドとバックエンドを一気通貫でテストすることができます。フロントエンドとバックエンドそれぞれをしっかりテストできたとしても、繋ぎ込みのインターフェイスのやり取りでお互いの定義にズレがあって動かないなど、よくありますので、このテストの存在も非常に重要です。
ただし、テストを書いたりメンテナンスに必要な工数がRSpecなどと比べて高くなりがちなのと、テスト結果が安定しづらいーーたまに落ちるみたいなことですねーーそして自動といえどテストの実行に時間がかかるというデメリットもあるため、一般的にテスティングピラミッドやテスティングトロフィーといった考え方においては、E2Eのテストケースをある程度絞って運用するのが最も費用対効果が良いと言われています。実際、私もそう思います。
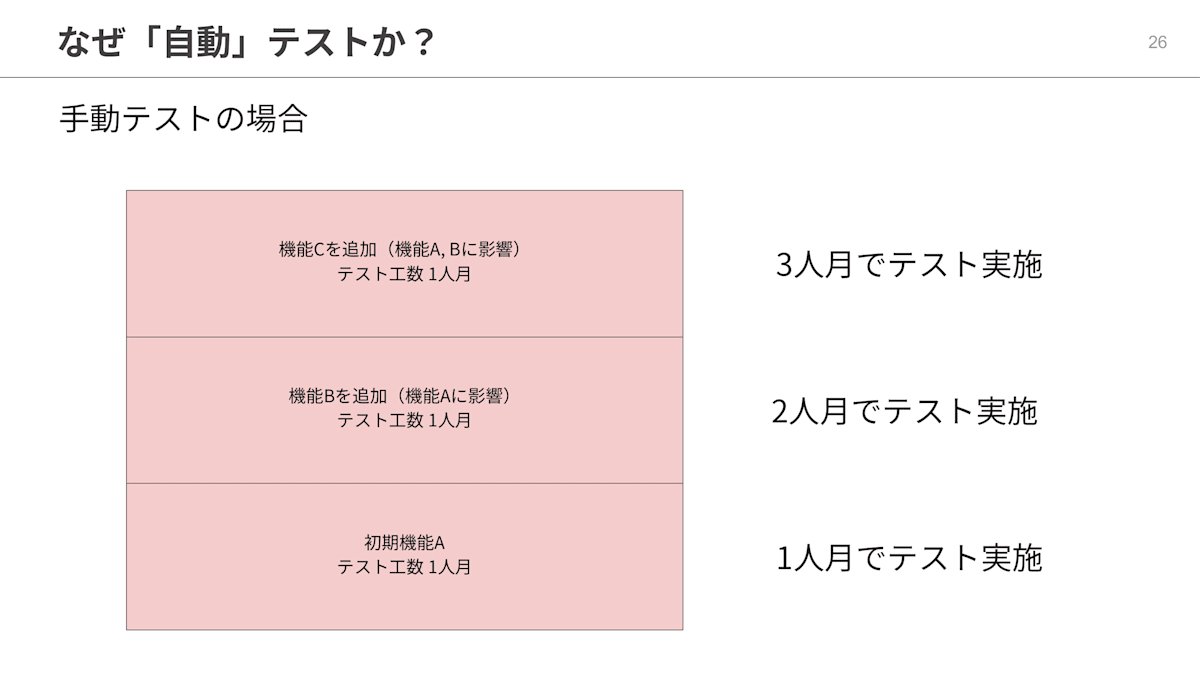
テストの自動化にこだわるのは、チームの規模はそのままに、開発速度も品質も落とさずにサービスを拡張したいからです。
ここで、あるサービスをゼロイチで作る事例を考えてみます。
このサービス開発では自動テストを全く導入せず、手動テストで品質を担保することにしました。
まず、初期機能Aだけを開発してテストをし、ファーストリリースをします。テスト工数は1人月でした。
続いて、機能Aに影響がある機能Bを追加してリリースをします。機能Bのテスト工数も1人月でした。機能Aに影響があるため、機能Aと機能B両方のテストをする必要があります。そのためテストに2人月かかりました。
さらに、機能Aと機能Bに影響がある機能Cを追加してリリースをします。機能Cのテスト工数も1人月でした。既存の機能Aと機能Bに影響があるため、機能A、機能B、機能Cすべてのテストをする必要があります。そのためテストに3人月が必要になりました。

一方、別のあるサービスをゼロイチで作る事例を考えてみます。
このサービス開発ではテストコードを書いてテストを自動化することにしました。
まず、初期機能Aだけを開発してテストをし、ファーストリリースをします。テストコード作成工数は1人月でした。
続いて、機能Aに影響がある機能Bを追加してリリースをします。機能Bのテストコード作成工数も1人月でした。機能Aに影響がありますが、機能Aのテストコードはすでにあるため、こちらについては0.1人月の修正で済みました。そのためテストコードの追加と修正に1.1人月かかりました。
さらに、機能Aと機能Bに影響がある機能Cを追加してリリースをします。機能Cのテストコード作成工数も1人月でした。既存の機能Aと機能Bに影響がありますが、機能A、機能Bのテストコードはすでにあるため、こちらについても0.2人月の修正におさまりました。そのためテストコードに1.2人月が必要になりました。

やや極端な仮定だったかもしれませんが、いかがでしょうか?
自動テストの例では、既存機能の修正工数を少し考慮しました。実際のプロジェクトでもこの傾向はあると思います。
いくらテストを自動化するとはいえ、1万行のコードベースと10万行のコードベースでは、開発速度や品質保証の難易度に影響は出るでしょう。ただ、自動テストを導入することで生産性の低下をかなりゆるやかにすることはできると思います。サービスの規模が拡大しても、テスト工数が倍々ゲームのように雪だるま式に増加することは防げます。
これにより、開発チームの人数を増やさなくてもサービスをスケールできるようになります。また、テストコードを実行するコストは極めて低いため、基本的には何度でも瞬時に実行できます。そのため、リリースの度にテストカバレッジを上げるようなことも自動テストでは可能です。手動テストは実施してソースコードを変更する度に振り出しに戻ってしまいますが、テストコードは積み上げることができます。
自動テストについても、プロジェクトを通して繰り返し実行することがほとんど確定しているので、静的解析の導入よりは手間がかかりますが、同時により大きなリターンももたらしてくれる投資だと思います。
CI/CDの整備
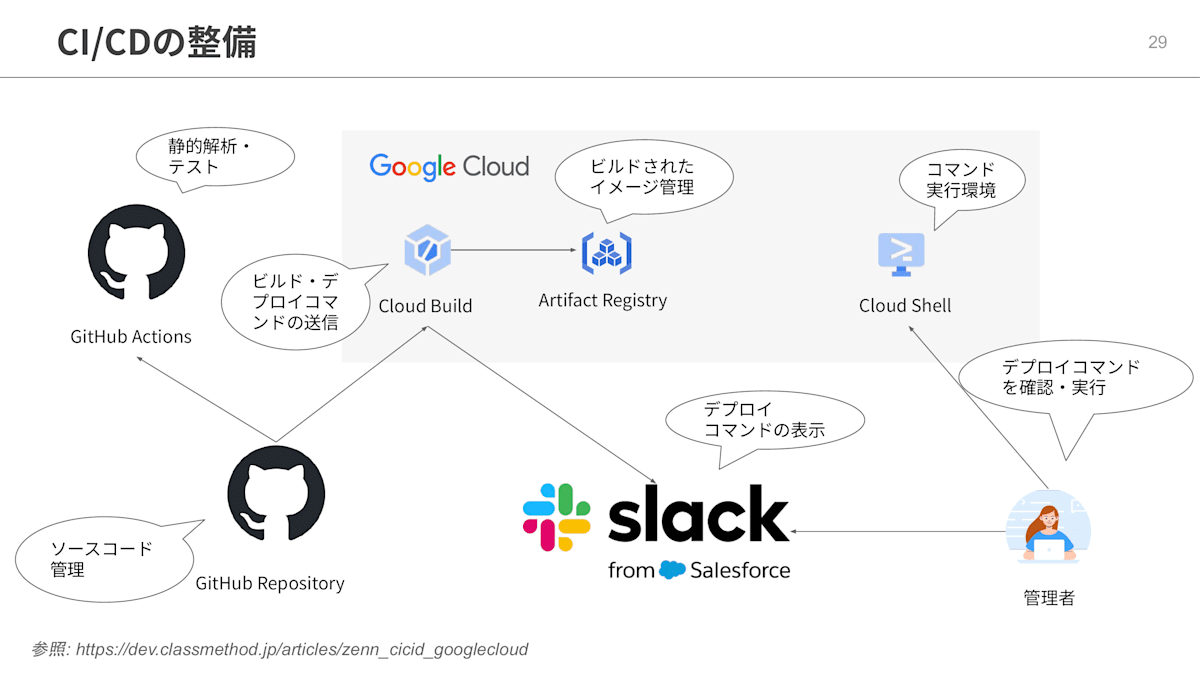
続いて、CI/CDの整備です。
Zennでは、CI/CDをこのような仕組みで導入しています。
現在はCI/CDの基盤として、GitHub ActionsとGoogle CloudのCloud Buildを併用しています。
GitHub Actions は、デプロイには関与せず、静的解析や自動テストに集中します。Cloud Buildは、Dockerイメージのビルドとプッシュ、そしてCloud Runへのデプロイに利用しています。ソースコード管理はGitHubのリポジトリで行っています。
開発者がプルリクエストを作成すると、GitHub Actions が起動し、静的解析や自動テストが実行されます。
GitHub Actions およびコードレビューにパスしたら、開発者がメインのブランチへマージします。するとCloud Build が起動し、新しいコンテナイメージを作成、イメージを Artifact Registry へプッシュします。
そして、gcloud コマンド経由で Cloud Run の新しいリビジョンを作成し、Slackにトラフィック切り替えのコマンドを送信します。
最後に、開発者がCloud Shellでトラフィック切り替えコマンドを実行することで、リリースが完了します。

ここで、CIとCDの定義について軽く振り返っておきます。
CIはContinuous Integrationの略で、日本語にすると継続的インテグレーションとなります。
コードの変更をリポジトリに自動かつ頻繁に統合する開発手法のことです。こまめに自動テストやビルドを実行することで、問題の早期発見を実現します。

CDはContinuous DeliveryもしくはContinuous Deploymentのことで、継続的デリバリー・継続的デプロイメントのことになります。
自分も今回調べて知ったのですが、CDはCIの後継ステップであり、継続的デリバリーは本番環境にデプロイ可能な状態を常に維持すること、つまり、デプロイの直前までを指しているようです。
一方、継続的デプロイメントは本番環境へのデプロイそのものを自動化することを指しています。

Zennでは、GitHub Actionsで実施している静的解析チェックや自動テストがCIに該当し、Cloud Buildで実施しているコンテナイメージビルドやSlackへのデプロイコマンドの送信が継続的デリバリーの方のCDに該当すると考えています。
なぜ使い分けているかというとGitHub Actions にはGoogle Cloudのアクセスキー・シークレットキーを含めない方針としているためです。
ChatOps的にSlackを活用しており、管理者はSlackに表示されたコマンドをコピーアンドペーストするだけでリリースができるようになっています。コマンド実行時も、Cloud Shell経由で個人端末の環境に寄らずにリリースコマンドを実行できるようになっています。
最後のデプロイまでは完全に自動化しておらず、継続的デプロイメントは実装せず、継続的デリバリーまで実装しているようなイメージです。そのため人の手が入る部分もありますが、チーム規模を考えるといいバランスに落ち着いていると思います。
生成AIの活用

続いて、生成AIの活用です。
今までは、定型作業のみが自動化の対象でした。静的解析にしろ、自動テストにしろ、CI/CDにしろ、そうですよね。
しかし、生成AIの登場により、非定型的な作業についても自動化できる余地が出てきたのではないかと思います。
では、どういったことに活用できるでしょうか?
ここでは実際にZennの運用業務で生成AIを適用した事例を紹介いたします。
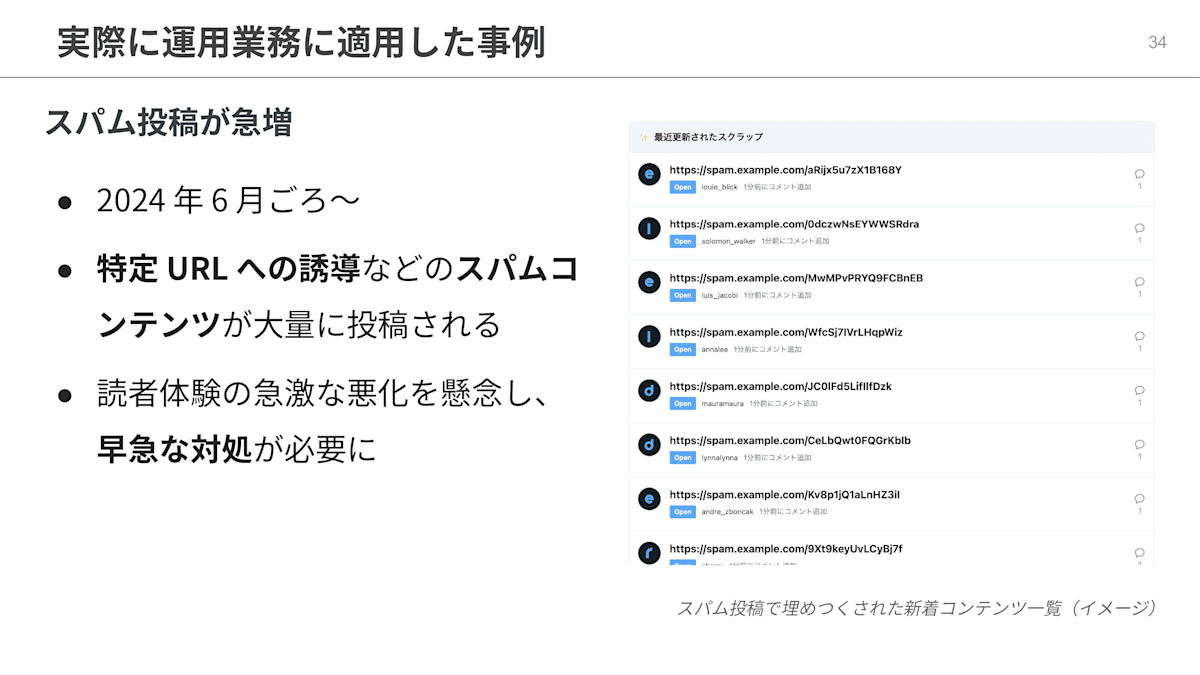
生成AIの力が必要になった背景から説明いたします。今年の6月ごろより、Zennにおいてスパム投稿が急増しました。特定URLへの誘導などの内容のスパムコンテンツが大量に投稿されていました。ひどいときは新着一覧がスパムで埋め尽くされるほどでした。これでは読者体験が急激に悪化してしまうと考え、早急な対処が必要となりました。
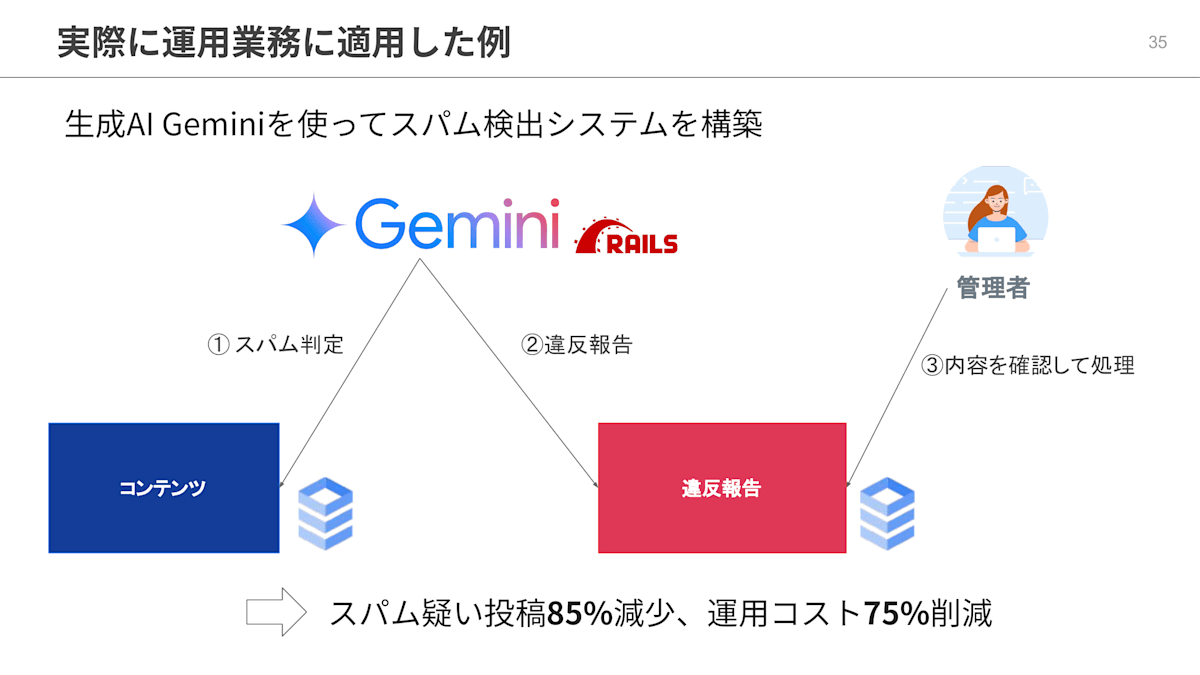
そこで、生成AIに新着コンテンツを巡回してもらい、スパム判定と違反報告をさせるというシステムを構築しました。生成AIモデルはGoogle Cloud上のGeminiを選定しました。
まず、 Gemini にプロンプトで何がスパムであるかの判定基準を与えます。そして、 Gemini を搭載した Ruby on Rails ワーカーがコンテンツを巡回し、スパム判定を行います。
そしてスパム疑いの場合、違反報告をします。人間の管理者は違反報告の内容を確認の上、対象アカウントやコンテンツへ対処をします。
この取り組みにより、人間の労力を最小限におさえることができました。そして、スパム疑いの投稿の85%減少、試算にはなりますが運用コストは75%の削減という成果を得ることができました。
このような取り組みは、従来からある文字列一致、ルールベース的な手法では難しいものでした。そのような従来の枠組みを超えた対処をするには、機械学習や自然言語処理の専門家が必要でしたが、そのような専門家がいない我々にとっては、自然言語のプロンプトを考えるだけで、そこそこの結果を上げられる点において画期的でした。
ちなみに余談ですが、この事例をGoogle Cloudイベントのピッチ大会で話したのですが、審査員の方に「生成AIにより機械学習の専門家は不要になったという話ですよね」というようなことをコメントいただきました。もちろん好意的な文脈でそれを言われており、審査員の方に他意があるという話では全くないのですが、私としては「そういう人材が不要になった」とは全く思っておらず、もし機械学習などの専門家がチームにいたらより柔軟に高精度に目的を実現できた可能性が高いと考えています。ピッチの制限時間が5分しかなくて、言葉足らずになっていたのだと思います。
あくまで、「そのノウハウがない人間でもそこそこのものができた。その意味で生成AIは画期的である」という点を強調したいと思います。

開発業務でも生成AI活用が進んでいます。開発中にChatGPTやClaude、GeminiをGoogle検索と併用して活用されている方はすでに多いかと思います。
私個人としては、初めて使用するライブラリやフレームワークで開発するときに、これまでそれらのチュートリアルドキュメントやStackOverflowのコードを参考にコードを書いていたようなところがかなり効率化されたという印象です。よりコーディングエディタと体験が統合されたGitHub Copilotも普及が進んでいると思います。弊社でも導入されています。

弊社では、主にGitHub CopilotとAI-Starterという内製ツールを組み合わせた開発が標準になりつつあります。
AI-Starterについて少しだけ説明すると、GPT・Claude・Geminiなど主要な生成AIモデルを1つのUIから切り替えて使用できるツールになります。GitHub CopilotはVSCodeで開発する際のコーディング支援として活用し、AI-Starterは汎用的な質問やOpenAI社以外のモデルを使いたい場合に使用しています。

ただ気をつけたいのが、生成AIは決して全知全能ではないということです。
この分野の専門家ではないので、私自身も調べてみたのですが、生成AIは世の中にある大量のテキストを取り込んだ上で、次に来る確率が高い単語を繋ぎ合わせて文章を出力しています。これは、生成AIの返答は、取り込んだ大量の文章をもとに多数決的に決まるということだと思います。そして、多数決で決められたことが正しいとは限らないですよね。そのため、専門家から見るとミスがある場合があります。
ChatGPTのo1-previewモデルにコード生成を依頼すると、脆弱性のあるコードが生成されたという報告もあります。

生成AIを使う際は、全部丸投げするという意識ではなく、スペシャリストである自分と生成AIのかけ算で開発するという前提でいるのが良いと思います。
そして、何よりも、成果物の品質に責任を持つのは人間であることを忘れないようにしたいと思っています。
おわりに

ここまでお聞きいただきありがとうございました。
「おわりに」です。
さらに自動化していくために

最後は、「さらに自動化していくために」という話で締めていきたいと思います。
まずひとつは、段階を踏んでインクリメンタルに導入することです。大風呂敷を広げると、結局何も実現せず頓挫しがちです。
また、小さく始めることが大切だと思います。既存業務を分解し、自動化に着手しやすい箇所を探しましょう。
そして、小さな自動化を確実にこなしていくことで、組織で成功体験を積み重ねられると良いと思います。実際の事例が積み重なると、机上のメリットではなく、チーム全員が自動化のメリットに腹落ちするようになり、前向きに取り組めるようになっていくはずです。

もうひとつは、HRTを大切にすることです。HRTとは、謙虚、尊敬、信頼です。
まずは、課題がない環境など存在しないことを認識しましょう。そして、解決に向けて動いていないように見えるチームメンバーにいらだって敵視しないようにしましょう。課題が解決されず残っていること、もしくはそのように見えることにはほとんどの場合、合理的な理由があります。
周囲を責めて敵に回しても、むしろ課題解決から遠ざかるだけです。「人を憎まず・・・」と言いますがその通りで、「バーサス誰か」ではなく「バーサス課題」で考えるようにしたいと思っています。
かくいう私も、時おり傲慢な気持ちになって、勝手に周囲に期待して勝手に失望して、イライラしてしまうことはあります。自戒もこめての話でした。

まとめ
まとめです。
最初に、そもそもなぜ自動化するのか?について話しました。これについては、人間よりも速くて正確だから、そして、時間を生み出して、より創造的なタスクに当てたいからといったことを述べました。
続いて、具体的な取り組みを紹介しました。まずはコードレビューを効率化するための静的解析、より開発をスケーラブルにするためのテストの自動化、そしてCI/CDの整備といった定型作業の自動化です。
また、生成AIを活用しての非定型作業の自動化や、開発業務への活用についても紹介しました。そして、自動化を推進していくために、大風呂敷を広げずインクリメンタルに進めようという話をしました。
最後に、これが一番大切で、HRTを大切に進めようということを述べました。

発表は以上になります。今回の話が、少しでもみなさんの参考になれば嬉しいです。ありがとうございました。

Discussion
HRTは大事ですね!ふだん働いてるなかで、「これはHRTが不足しているな」と感じる言動や予兆はありますか?