Twemoji(Twitter社が提供するオープンソースの絵文字)の読み込みを改善するのが好きです。
最近もう一つ改善を行ったので簡単に記事にまとめておきます。
twemojiの一般的な使い方
npmを利用したプロジェクトでTwemojiを導入する場合、twemojiという公式ライブラリを使うのが一般的だと思います。このライブラリを読み込んでtwemoji.parse()を呼び出すとDOMから絵文字を見つけて、それをtwemojiの画像(<img />)に変換してくれます。
例えば、こんなHTMLに対してtwemoji.parseを実行すると…
<p>こんにちは😺</p>
次のように<img />要素に変換されるというイメージです。デフォルトではMaxCDNから配信されている画像が読み込まれます。
<p>こんにちは <img src="https://twemoji.maxcdn.com/2/svg/1f63a.svg" alt="😺" ... /></p>
クライアント側のJSのバンドルサイズを抑えたい
ライブラリの使い勝手は十分に良いのですが、twemoji.parseをクライアントで実行するとなれば、そのぶんだけクライアントで読み込まれるJavaScriptが大きくなってしまいます。サーバーサイドでのみ実行するという手も考えられるのですが、Next.jsやNuxt.jsといったSPA的な側面を持つフレームワークでそれをやろうとすると色々とややこしいことなります(ややこしいのでここでは説明しません)。
自分のプロジェクトでは「DOMから絵文字を見つけて全てTwemojiに変換したい」というケースは無く、「この絵文字をTwemojiで表示したい」というケースしかありません。<Twemoji emoji="😺"/>というコンポーネントが<img src="TwmeojiのURL" />を出力してくれるだけで良いのです。
URL内で指定した絵文字のTwemojiを返してくれるヤツがほしい
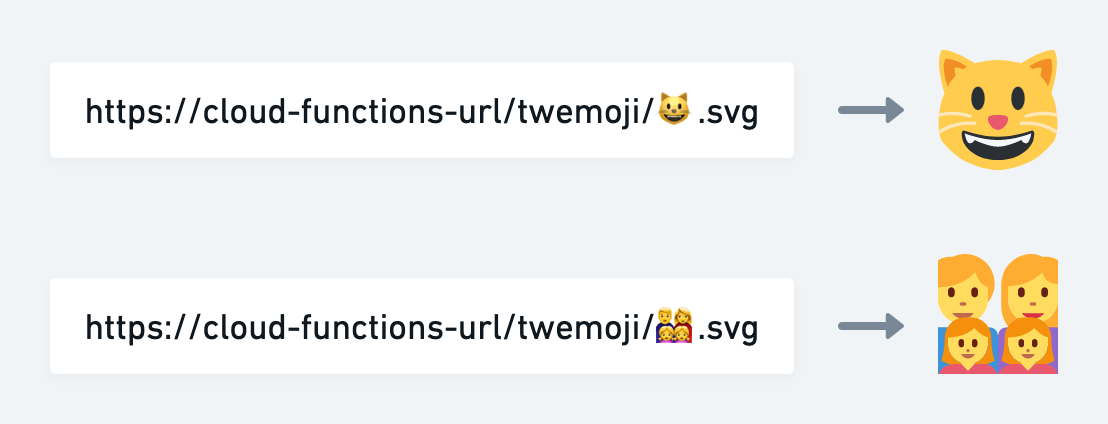
そこで考えたのは「絵文字をURLに含めたらその絵文字にマッチするTwemoji画像を返してくれるサーバーがあればいいんじゃないか」ということです。https://.../😺.svgにアクセスすると猫のTwemoji画像を返してくれるようなイメージです。URLのパターンは限られるのでCDNへのキャッシュもやりやすそうです。
Cloud Functionsで作ってみた
というわけでGoogle Cloud Functionsで実際に作ってみました。URLに絵文字を入れることでその絵文字に該当するTwemoji画像が返ってくるというイメージです。
Cloud RunではなくCloud Functionsを選んだ理由は、Google Cloudのエッジキャッシュを簡単に利用できるためです(レスポンスヘッダにCache-Control: public, max-age:86400のような指定をするだけでOK)。
このFunctionsを導入することで具体的には以下のような形でブラウザでのパフォーマンス改善が期待できます。
これまで
- ブラウザでTwemoji parserを読み込む
- ブラウザでTwemoji parserを実行して絵文字の画像URL(MaxCDN)を取得
-
ブラウザで
<img>からURLを読み込む - MaxCDNから画像がレスポンスされる
導入後
-
ブラウザで
<img>から表示したい絵文字入りのURLを読み込む - Cloud FunctionsでTwemoji parserを実行し、絵文字の画像URL(MaxCDN)を取得
- Cloud FunctionsでMaxCDNから画像を読み込む
- エッジキャッシュの設定をしたうえでクライアントに画像を返す
※ Cloud FunctionsからのレスポンスをGoogle Cloudのエッジキャッシュにのせれば、ほとんどのリクエストで(2)と(3)は実行されなくなります。
これにより、ブラウザ上で読み込まれるJavaScriptを削減できますし、Twemoji parserによる負荷も削減できます。また、実際に試してみると、自分の環境ではGoogle Cloudのエッジキャッシュからのレスポンス時間がMaxCDNからのレスポンスに比べて約100msほど速いことが分かりました(もしかしてtwemoji.maxcdn.comは日本リージョンがないのかも? 要調査)。
サンプルコード
実装はごく単純です。リクエストURLから絵文字を取り出し、twemoji-parserを使って最初の1つ目を取り出します(ZWJまわりで悩む必要なし!)。あとはそのURLの画像をMaxCDNからフェッチし、Cache-Controlを設定したうえでクライアントに返します。
import type { Request, Response } from "express";
import { parse } from "twemoji-parser";
import * as http from "https";
export function twemoji(req: Request, res: Response) {
const rawText = req.url.match(/\/([^\/]+)\.svg$/)?.[1];
if (!rawText) {
return res.status(400).end("Invalid URL");
}
const targetText = decodeText(rawText);
if (!targetText) {
return res.status(500).end("Failed to decode URL");
}
const twemojiURL = getFirstTwemojiUrl(targetText);
if (!twemojiURL) {
return res.status(404).end("No emoji found");
}
http
.request(twemojiURL, (response) => {
if (res.statusCode === 200) {
res.writeHead(200, {
"Content-Type": "image/svg+xml",
// Google Cloudのエッジキャッシュにのせる
"Cache-Control": "public, max-age=1209600, s-maxage=5184000",
});
response.pipe(res);
} else {
console.error(response);
res.writeHead(500);
res.end("Internal server error");
}
})
.end();
}
// 最初の1つめのTwemojiのURLを取り出す
function getFirstTwemojiUrl(text: string): null | string {
const entities = parse(text, { assetType: "svg" });
return entities.length === 0 ? null : entities[0].url;
}
function decodeText(raw: string): null | string {
try {
return decodeURIComponent(raw);
} catch {
return null;
}
}
デプロイ
Cloud Functionsではデプロイ時にgcp-buildという名前のnpmスクリプトを自動で実行してくれます(Cloud Functions for Firebaseだとpredeployという名前になるっぽい)。今回はTypeScriptを使っているので"gcp-build": "tsc -p ."のようにコンパイルの処理を書いておきます。
ローカルからデプロイするのであればgcloudを使ってこんな感じでデプロイコマンドを叩けばOKです。
gcloud functions deploy twemoji \
--region=[region-name] \
--memory=256 \
--timeout=3s \
--source=. \
--entry-point=twemoji \
--project=[gcp-project-name] \
--trigger-http \
--allow-unauthenticated
こういうちょっとした処理を書くときにCloud Functionsは本当に便利ですね。

Discussion
twemoji.maxcdn.com の URI を見た感じでは下記の実装でも問題なさそうですね
ありがとうございます。仰る通りだと思います!自分も最初は
という感じで書いていたのですが、
という理由からtwemoji-parserを使うことにしました。
関連
twemoji-parserの該当部分のソースコード: https://github.com/twitter/twemoji-parser/blob/master/src/index.js
なるほどです
絵文字が2つ渡された場合に関しては Intl.Segmenter という選択肢もありますが
前後に絵文字以外が入る可能性については確かに正規表現しか無い気がしますね…
Unicode はつらい…