はじめに
MySQL(InnoDB)でSQLのパフォーマンスチューニングをするときに役に立つ知識をエッセンスとしてまとめました。結合(JOIN)やB-treeインデックスの探索の仕組み、実行計画の基本的な見方を紹介します。
想定する読者は、SQLのパフォーマンスを改善する必要があるが実行計画をみてもいまいちピンと来ない方です。インデックスの作成の経験や、複合インデックスやカーディナリティの知識があることを前提にしています。目標は、実行計画の内容がよく分からない読者が、実行計画をみただけでクエリが実行される様子をイメージでき、自信を持ってクエリの改善にあたることができるようにすることです。
ストレージエンジンはInnoDBを前提としています。また、インデックスはB-treeインデックスを想定しています。全文検索の転置インデックスや空間検索のR-treeインデックスについては触れません。
インデックスとは
インデックスとは、効率よく探索するための仕組みのことです。例としては、実用書の巻末にある索引が、まさにこれです。インデックスは日本語で索引と呼ばれます。
本の中から特定の単語について説明されているページを探す場合、索引を参照してすぐさま目的のページを探し出すことができます。また、索引では単語が50音順やアルファベット順に並んでいるので、索引の中から単語自体を見つけることも簡単です。もし索引がなければ、最悪の場合、本のすべてのページを調べることになり、とても非効率です。
B-treeインデックス
B-treeインデックスは、B-treeと呼ばれるデータ構造で実現されたインデックスのことです。B-treeはバランス木の一種で、最悪のケースの場合でも比較的効率よく探索ができるように工夫されています。B-treeインデックスはMySQLだけではなく、他の多くのRDBMSでも採用されています。
InnoDBで使用されているB-treeインデックスでは、実際にはI/O性能がよくなるように最適化されたB-treeの改良版が用いられています。このデータ構造はB+treeと呼ばれていますが、MySQLの公式ドキュメント同様に、この記事でもB-treeと表記することにします。
B-treeは図のような木構造になっています。ノードはキーを持ちます。キーはインデックス作成時に指定したカラムの値です。上下に連なっているノードの上側を親ノード、下側を子ノードといいます。一番上に一つだけあるノードをルートノードといい、反対に、末端にあるノード群をリーフノードといいます。ルートノードとリーフノードの間にあるノード群はブランチノードです。データ量が増えていくと、ブランチノードの階層だけが増えていき、木が高くなっていきます。リーフノード同士は隣のリーフノードと双方向に参照しあっており、双方向リンク構造になっています。全てのノード内で、キーは昇順または降順で並んでいます。
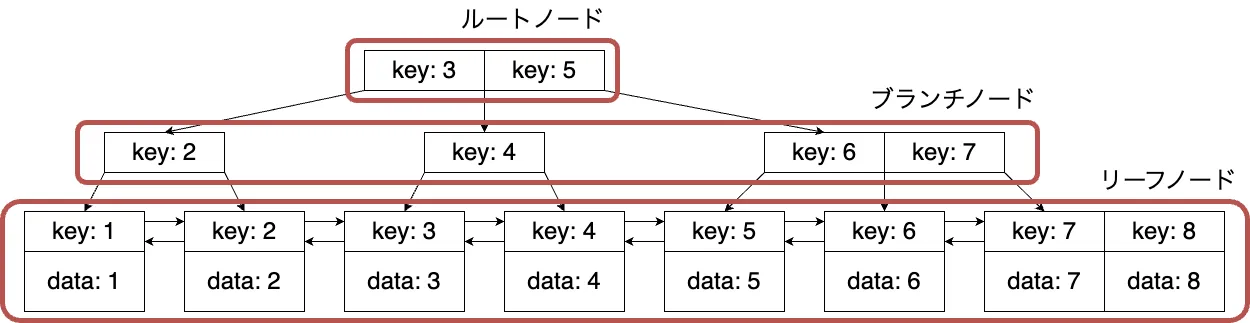
図1. B-treeのノードの種類
B-treeインデックスの探索
B-treeは、どのリーフノードに対してもルートノードからの高さが同じになる性質を持ちます。これは、どのデータに対しても同じ探索回数でアクセスできるで、安定した探索ができることを意味します。
例として、IDによる商品の検索を考えてみます。次のようなクエリを実行して、インデックスを探索して8番のキーの商品を取得します。
SELECT * FROM products WHERE id = 8;
ここでは話をシンプルにしたいので、高さが2の3次のB-treeを考えます。3次のB-treeというのは、ノードが最大で3つの子ノードと2つのキーを持つB-treeのことです。
最初に、ルートノードから探索をスタートします。ルートノード内には2つのキーがソートされた状態で保持されています。ノードの各キーの値と8を比較します。8は3と5よりも大きいので一番右の参照を辿ります。さらに、この手順をブランチノードでも繰り返すと、目的の商品のデータが存在するリーフノードへ辿り着きます。そしてリーフノードが持つデータの中から目的のものを探し出します。これで探索は終了です。
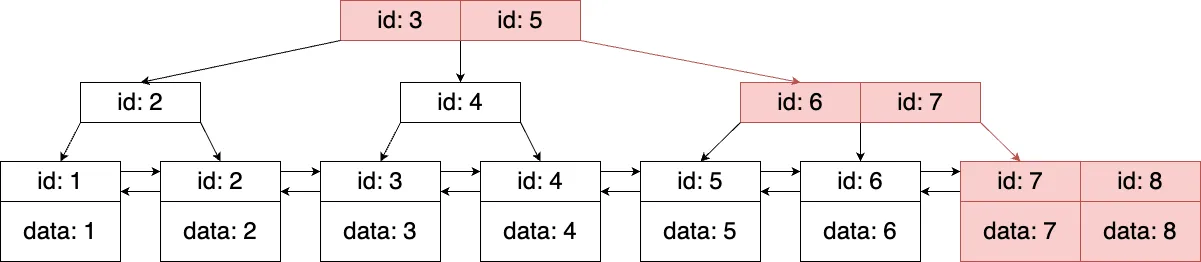
図2. B-treeのノードの探索
ここで、探索の効率について考えます。B-treeを使用した場合と使用していない場合とで効率を比較します。探索とは、1つのノードを調べることとします。先のB-treeを使った探索では、3つのノードを調べたので探索回数は3です。一方で、B-treeをルートノードから探索しない場合を考えます。一度、B-treeの構造を無視して、リーフノードだけに着目します。リーフノードにはすべてのデータが存在しているので、すべてのリーフノード調べることで目的の商品を探し出すことができます。実際に、先の例のリーフノードを左から順番に調べていくと、左から7番目のノードの左端に目的の商品を見つけることができます。この探索回数は、7つのノード調べたので7です。この探索は線形探索と呼ばれます。
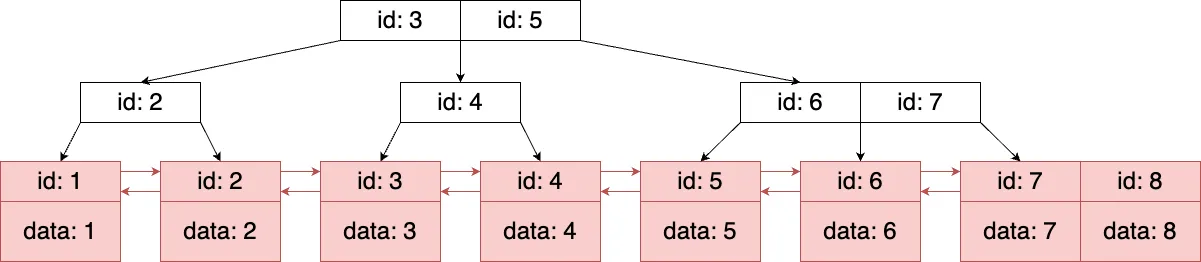
図3. リーフノードの探索(線形探索)
先の例では、B-treeをルートから探索する場合とリーフノードをすべて探索する場合とでは、B-treeの探索のほうが効率がよいことがわかりました。一般に、
クラスタインデックスとセカンダリインデックス
MySQLのインデックスは、クラスタインデックスとセカンダリインデックスに分けられます。どちらもB-treeインデックスです。
クラスタインデックスは、テーブルのプライマリキーをキーとして持つインデックスです。リーフノードにキー以外のテーブルのすべてのデータが含まれています。プライマリキーを使ってクラスタインデックスを探索した場合、リーフノードから目的のデータを取得した時点で探索は終了です。
一方、セカンダリインデックスは、インデックス作成時に指定したカラムの値をキーとして持ちます。また、リーフノードにはキーとテーブルのプライマリキーのみを持ちます。セカンダリインデックスを使った探索は、キーとプライマリキー以外のデータを取得する必要がある場合、プライマリキーを使って別途クラスタインデックスを探索する必要があります。
一般に、セカンダリインデックスを利用した探索は、探索後に別途クラスタインデックスの探索を行うため、クラスタインデックスのみの探索と比べて遅くなります。例外として、セカンダリインデックスに取得したいデータが全て揃っている場合は、クラスタインデックスへの追加の探索は行われません。このような特定のクエリに対して必要なデータを網羅しているセカンダリインデックスのことを、カバリングインデックスと呼びます。
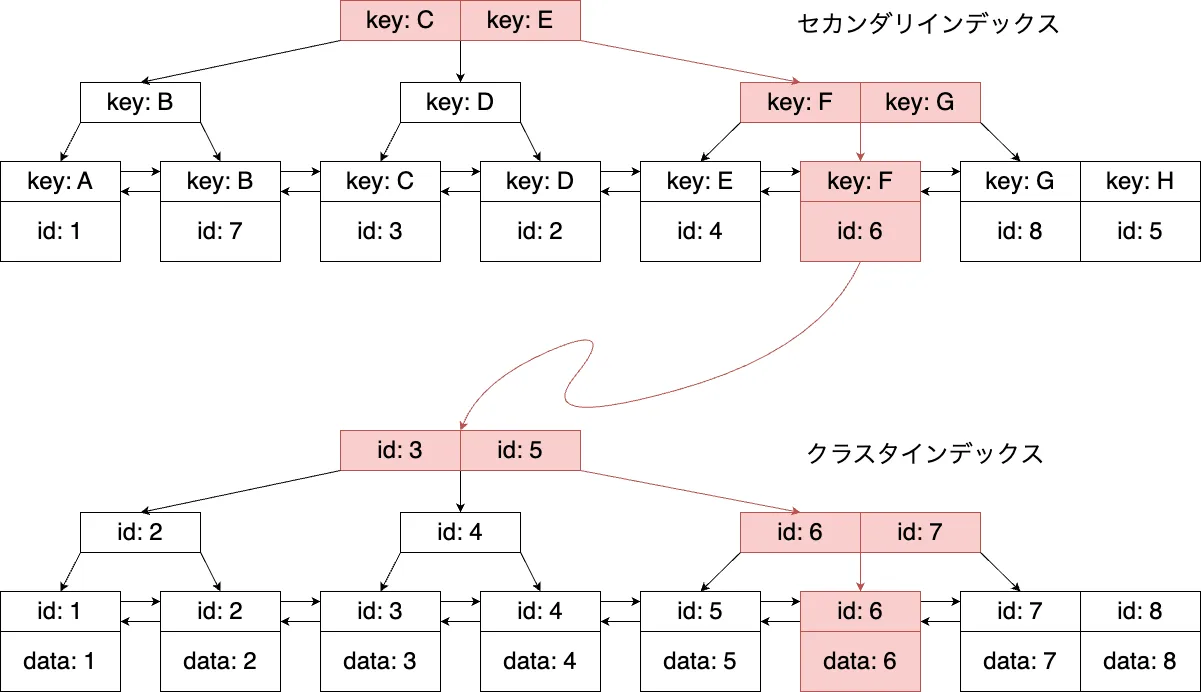
図4. クラスタインデックスとセカンダリインデックス
結合方式(Nested Loop)
MySQLの基本的な結合(JOIN)のアルゴリズムが、Nested Loopです。Nested Loopは結合するテーブルからのデータの取得を入れ子にして処理します。たとえば、3つのテーブルt1, t2, t3があり、これらを結合する場合、3重のループの処理になります。次のコードは、Go言語で書いたNested Loopの疑似コードです。ループの外側のテーブルを外部表といい、内側のテーブルを内部表といいます。外部表は駆動表とも呼ばれます。t1はt2に対して外部表で、t2はt1に対して内部表です。外部表で条件に一致し取得された行は、1行ずつ内部表のループに渡されます。内部表のループでは、その都度条件に一致する行をディスクまたはキャッシュから読み込み、さらなる内部表があればこれを1行ずつ渡していきます。すべてのテーブルの結合が終わるまでこれを繰り返します。外部表で条件に一致した行の数だけループするので、外部表の条件で結合対象の行数を少なくすることができれば内部表でディスクにアクセスする回数を減らすことができ、より良いパフォーマンスを期待できます。
for _, matched_row := range matched_rows_t1 {
for _, matched_row := range matched_rows_t1_t2 {
for _, matched_row := range matched_rows_t1_t2_t3 {
}
}
}
実行計画でみるtype別データアクセス方法
実行計画は、クエリが実行される過程を示してくれます。参照されるテーブルの順番やそのアクセス方法、ソート処理が行われるかどうかといった情報を知ることができます。実行計画をもとに、クエリのパフォーマンスチューニングを行うのが定石です。
実行計画の出力にはいくつかの項目があります。次の表は、MySQL8.0公式ドキュメント(日本語版)からの抜粋です。カラムは実行計画を EXPLAIN文で表形式で出力した場合の項目名です。JSON名は、EXPLAIN FORMAT=JSON文でJSON形式で出力した場合の項目名です。意味は各項目の説明です。以降は カラム の項目名を使います。
| カラム | JSON名 | 意味 |
|---|---|---|
| id | select_id | SELECT 識別子 |
| select_type | なし | SELECT 型 |
| table | table_name | 出力行のテーブル |
| partitions | partitions | 一致するパーティション |
| type | access_type | 結合型 |
| possible_keys | possible_keys | 選択可能なインデックス |
| key | key | 実際に選択されたインデックス |
| ey_len | key_length | 選択されたキーの長さ |
| ref | ref | インデックスと比較されるカラム |
| rows | rows | 調査される行の見積もり |
| filtered | filtered | テーブル条件によってフィルタ処理される行の割合 |
| Extra | なし | 追加情報 |
クエリのパフォーマンスチューニングをする場合に特に注目するのが、type と Extra です。typeは、公式ドキュメントでテーブルの結合方法と説明されていますが、JOIN句などでテーブルを結合していない場合でも有益な情報です。どのようにインデックスやテーブルへアクセスされるかを教えてくれます。
主要なtypeは以下です。上に行くほど、パフォーマンスがよい方法です。
| type | 説明 |
|---|---|
| const | プライマリキーやユニークキーを使って一意なデータを1件だけ取得する。とても速い。 |
| eq_ref | テーブルを結合する際に、プライマリキーやNULLを許容しないユニークキーを使って、一意なデータを結合の回数分だけ取得する。結合回数が少ない場合は高速だが、多いと遅くなる。 |
| ref | テーブルを結合する際に、ユニークじゃないインデックスを使って複数行取得する。取得対象の行が少ない場合は高速だが、多いと遅くなる。 |
| range | インデックスを使って、特定の範囲の複数行を取得する。取得対象の行が少ない場合は高速だが、多いと遅くなる。 |
| index | インデックスの全行を探索する(フルインデックススキャン)。データ量によるが一般的に問題になるレベルで遅い。 |
| ALL | インデックスを使わずに、テーブルの全行を探索する(フルテーブルスキャン)。データ量によるが一般的に問題になるレベルで遅い。 |
index と ALL が表示されている場合は要注意です。テーブルのデータ量にはよりますが、一般的にある程度の規模のシステムのクエリで index や ALL が表示されていれば、おそらくクエリの応答時間が問題になるレベルで遅くなっていると思います。逆に、テーブルのデータが少ない場合は index や ALL でも問題にはなりません。実際にInnoDBのオプティマイザは、データ量の少ないテーブルに対してクエリを発行した際、テーブルに使えるインデックスが存在していたとしても、これを使わずにフルテーブルスキャンすることがあります。しかし、この場合、応答時間は問題にはなりません。また、UNION や UNION ALL 文などの統合結果の一時テーブルでも ALL が表示されることがありますが、統合結果のデータが極端に少ない場合は問題にはなりません。typeだけで判断するのではなく、データ量も考慮する必要があります。
各typeのイメージ
インデックスの探索の理解があれば、先述のtypeの説明は暗記することなく理解ができると思います。
cost
プライマリキーやユニークキーを使って一意なデータを1件だけ取得するのがconstです。「一意に絞り込む」というところが重要です。たとえば、プライマリキーやユニークキーが複合インデックスになっていた場合、これらのインデックスを使ったとしても、複合キーの一部しか使っていない場合は一意な絞り込みにはならないのでconstにはなりません。
B-tree探索のイメージとしては、一意なキーを使ってルートから探索し、リーフノードを1つだけ取得するイメージです(図2を参照)。ディスクもしくはキャッシュから読み取るノードの数が少ないので高速な処理です。
eq_ref
テーブルを結合する際に、プライマリキーやNULLを許容しないユニークキーを使って、一意なデータを結合の回数分だけ取得するのがeq_refです。こちらも「一意に絞り込む」というところが重要です。1回あたりの処理はconst同様に高速ですが、結合回数が多いと遅くなる可能性があります。結合回数は、Nested Loopの項目でみた通り、外部表でマッチした行数です。eq_refで遅い場合はおそらく結合回数が多いのが原因なので、外部表でさらにデータを絞り込めないか検討する必要があります。B-tree探索のイメージとしてはconstと同じです。constとの違いは、複数回繰り返す可能性があるところです(図1とNested Loopを参照)。
ref
テーブルを結合する際に、ユニークではないインデックスを使って、複数行を結合の回数分取得するのがrefです。取得対象の行が少ない場合は高速ですが、多いと遅くなる場合があります。B-tree探索のイメージとしては、ルートから探索して範囲検索の始点(または終点)と一致するリーフノードに辿りきます。そこからリーフノードを探索して、終点(または始点)となるノードまでをごっそり取得するイメージです。これを結合回数分繰り返します。
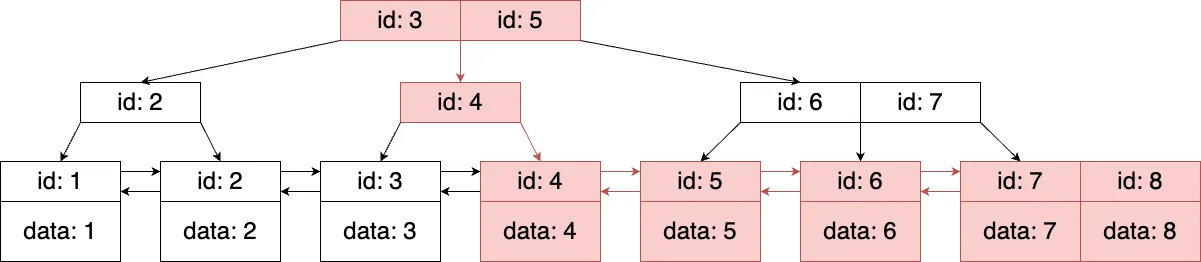
図5. idが4以上の範囲検索の例
range
インデックスを使って特定の範囲の複数行を取得するのがrangeです。取得対象の行が少ない場合は高速ですが、多いと遅くなる場合があります。B-tree探索のイメージはrefと同じです(図5を参照)。これらの演算子や句(=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, IN)を使った場合にrangeになります。
rangeでは取得するデータが多くなると遅くなるので、他の条件と組み合わせて絞り込みができる場合は、複合インデックスを使って範囲の絞り込みをするとリーフノードの探索範囲が狭くなって高速化が期待できます。たとえば、特定の範囲の10万人のユーザの中から、東京都に住所があるユーザを取得するクエリがあるとします。一見、10万件を探索する必要があるように思えますが、第1キーがaddress、第2キーがユーザIDになっている複合インデックス(address, id)があれば、探索範囲を10万件より少なくすることができます。この場合のB-treeインデックスの探索イメージとしては、ルートノードからaddressとidの始点(または終点)で探索をしてリーフノードまで辿り着き、そこからリーフノードの参照を辿ってidの終点まで探索するイメージです。指定した範囲のユーザが全員東京都の住民ではない限り、対象のデータは10万件より少なくなります。
SELECT * FROM users WHERE users.address = '東京都' AND users.id BETWEEN 1 AND 100000
よくある間違いとしては、複合インデックスのキーの順番を(id, address)の順番にしてしまうことです。これは、まずデータはidの順番に並べられて、そのあとidごとにaddressの順番で並べられることを意味します。したがって、まずidで範囲検索をして10万件を探索したあとにaddressが東京都に一致するかを確認します。このとき、addressだけをみると東京都のデータは10万件の中に散在していることになります。これは結局10万件のデータをすべて見る必要があることになるので、複合インデックスがうまく活用できていません。(id, address)の順番で複合インデックスを作成してしまう原因としては、インデックス設計における「カーディナリティの高いカラムからインデックスをはる」という原則が関係していると思います。ここではaddressは都道府県を想定しているので、カーディナリティは47で、ユーザIDのカーディナリティは10万以上です。そのため、ユーザIDを使う方が速くデータの絞り込みができそうに見えるのが、間違いやすい原因だと思います。
index
インデックスの全行を探索するのがindexです。インデックスの全行を探索することをフルインデックススキャンといいます。データ量によりますが、ある程度の規模のシステムでは問題になるレベルで遅いです。インデックスを使ったデータの絞り込みが行わていないので、絞り込みに使えるインデックスが存在していないか、インデックスの設計を誤っている可能性があります。インデックスを新規作成もしくは修正する必要があります。B-tree探索のイメージとしては、リーフノードのキー全体を端から端まで探索するイメージです。ディスクやキャッシュから大量にノードを取得する必要があるのでI/Oに時間がかかるのと、調査するノード数が多いのでCPUを消費します。
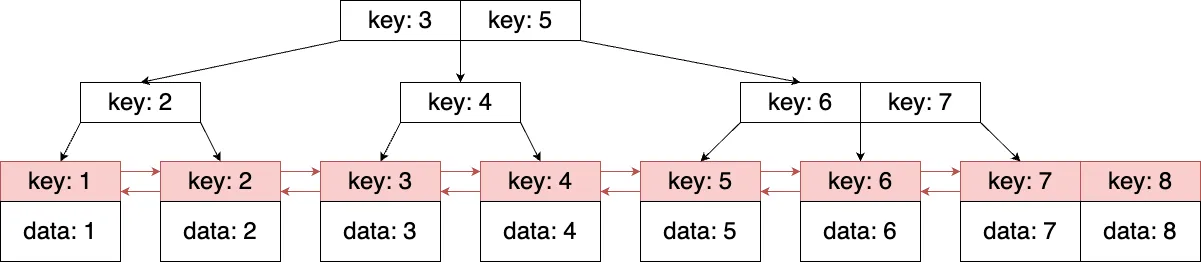
図6. フルインデックススキャン
ALL
インデックスを使わずに、テーブルの全行を探索するのがALLです。テーブルの全行を探索することをフルテーブルスキャンといいます。データ量によりますが、これもindex同様、ある程度の規模のシステムでは問題になるレベルで遅いです。キーとしてインデックスに存在していないカラムを絞り込みの条件に使った場合にALLになります。B-tree探索のイメージとしては、リーフノードのデータを全体を端から端まで探索するイメージです(図3を参照)。ディスクやキャッシュから大量にノードを取得する必要があるのでI/Oに時間がかかるのと、調査するノード数が多いのでCPUを消費します。ALLを回避するには、絞り込みの条件に使用しているカラムをキーとして持つインデックスを新規作成します。
Extraについて
Extraには追加の情報が表示されますが、typeと同様にパフォーマンスチューニングをする際に重要な情報が表示されるので、注目する必要があります。主なものだけを紹介します。
| Extra | 説明 |
|---|---|
| Using index | インデックスの探索だけでクエリが完結したことを表します。セカンダリインデックスを使った場合は、クラスタインデックスの探索が不要なことを意味します。これが表示されていることは、よいことです。 |
| Using index condition | 複数の絞り込みの条件のうち、一部の条件がインデックスを使って解決されたことを表します。たとえば、(first_name, last_name, age) の順番の複合インデックスがあり、WHERE first_name = 'Taro' AND age = 20という絞り込みの条件があった場合、通常はインデックスを使った絞り込みはfirst_nameのみで行われます。理由は、last_nameが絞り込みの条件として指定されていないからです。first_name が Taro になっているすべてのデータをテーブルから取得して調査する必要があります。しかし実際には、MySQLは最適化を行い、テーブルにアクセスする前にインデックスを使ってageでの絞り込みを行います。こうしてテーブルから取得するデータの数をなるべく絞ったあとに、テーブルから取得したデータを使ってlast_nameを調査します。この最適化のことをインデックスコンディションプッシュダウン(ICP)といいます。 |
| Using where | インデックスを使わずにテーブルから取得したデータをみて絞り込みの条件を解決したことを表します。インデックスを作成して改善する余地があります。 |
| Using temporary | 処理の中間データを保持するために、メモリ上に一時テーブルが作成されたことを表します。データ量が多い場合はメモリを消費するので注意が必要です。GROUP BYやORDER BYなどを使うと表示されることがあります。ORDER BYの場合は、該当カラムにインデックスをはることで改善することができます。 |
| Using filesort | インデックスを使わない並び替えの処理が発生することを表します。データ量によってはCPUのリソースを多く消費するので注意が必要です。並び替えの原因となっているカラムにインデックスをはることで改善することができます。 |
おわりに
SQLのパフォーマンスチューニングでは、実行計画を見ながら改善を行うことが重要です。絞り込みの条件を変えてみて、実行計画がどう変化するかを確認すると理解が深まると思います。また、知らないケースが出てきた場合は、MySQLの公式ドキュメントを参照するとさらに理解が深まるのでおすすめです。
インデックス設計は、原則と例外を理解し、データ量も考慮して行う必要があります。また、最良の実行計画でなくても、データ量によっては現実的には問題にならない場合があります。やみくもにインデックスを追加したりせず、現実的な落とし所を見つけることが大切だと思います。
参考
- MySQL. EXPLAIN出力フォーマット. https://dev.mysql.com/doc/refman/8.0/ja/explain-output.html
- MySQL. Nested Loop結合アルゴリズム. https://dev.mysql.com/doc/refman/8.0/ja/nested-loop-joins.html
- MySQL. インデックスコンディションプッシュダウンの最適化. https://dev.mysql.com/doc/refman/8.0/ja/index-condition-pushdown-optimization.html

株式会社SODAの開発組織がお届けするZenn Publicationです。 是非Entrance Bookもご覧ください! → recruit.soda-inc.jp/engineer
Discussion