Go1.21で登場したlog/slogパッケージのパフォーマンスを徹底解説!!
導入
Go1.21で標準ライブラリとしては初の構造化ログのためのlog/slogパッケージが導入されました。
どういう設計や実装になっているのかに興味があったので調べてみると、パフォーマンスをかなり意識した実装になっていることが分かりました。
このブログでは、log/slogパッケージがどういう背景や目的を持って導入されたのか、基本的なAPIの使い方はどうなっているのか、また内部の実装でパフォーマンスが意識されているところはどこなのかをできるだけ詳しく解説したいと思います。
この記事はGo Conference mini 2023 Winter IN KYOTOの「Deep dive into log/slog package」というセッションの内容をより詳細にまとめた記事になります。
また上記の発表資料はこちらから閲覧できます。
この記事で知れること
- log/slogパッケージが実装された背景や目的
- 基本的なAPIの使い方
- パフォーマンスを意識した内部の設計や実装
log/slogパッケージの概要
log/slogパッケージとは?
log/slogパッケージはGo1.21のリリースで導入された構造化ログのための標準ライブラリです。
他にも構造化ログのためのライブラリは以下のようにたくさん開発されています。
なぜ開発されたのか?
上記に挙げたように構造化ログのためのライブラリは既にたくさん開発されていました。
なぜ、log/slogパッケージが開発されたのでしょうか?
回答としてはProposalのWhat does success look like?にあります。
But more important than any traction gained by the “frontend” is the promise of a common “backend.” An application with many dependencies may find that it has linked in many logging packages. When all the logging packages support the standard handler interface proposed here, then the application can create a single handler and install it once for each logging library to get consistent logging across all its dependencies. Since this happens in the application‘s main function, the benefits of a unified backend can be obtained with minimal code churn. We expect that this proposal’s handlers will be implemented for all popular logging formats and network protocols, and that every common logging framework will provide a shim from their own backend to a handler. Then the Go logging community can work together to build high-quality backends that all can share.
要約すると以下のようになります。
- 1つのアプリケーションでも依存関係を通して多くのロギングライブラリに依存することがある
- log/slogパッケージに"バックエンド" (後述の
Handlerインターフェイス) を導入し、将来的には既存のライブラリが"バックエンド"をサポートすることを期待する - アプリケーションは一つの
Handlerインターフェイスを作成し、ロギングライブラリに渡すことでログが統一される
つまり、将来的に色々なロギングライブラリが、log/slogパッケージで導入されたHandlerインターフェイスを受け入れる (実装する) ようになると、みんなで共有できるより高品質な"バックエンド"を作成するためにGoのコミュニティが協力し合えるのではないか、ということのようです。ログのフォーマットが統一できるということにも言及されており、そこも1つ大きなポイントだと考えられます。
基本的なアーキテクチャ
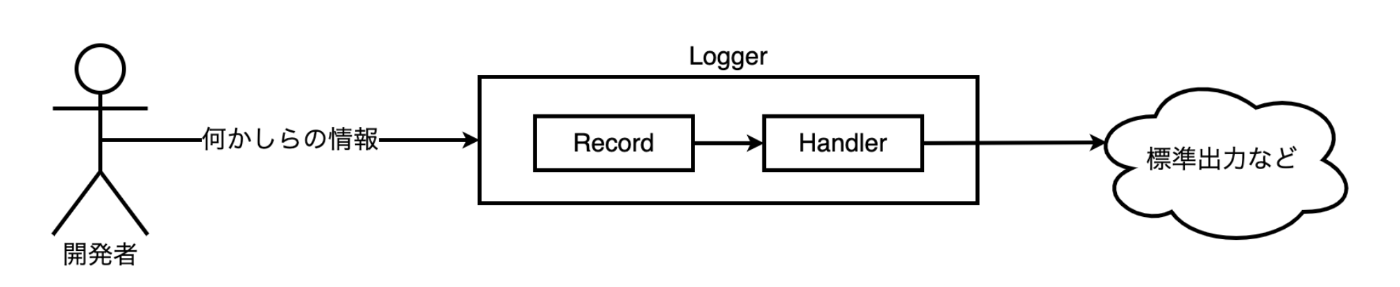
続いて基本的なアーキテクチャについて説明します。大きく分けて3つの構造体とインターフェイスが関係してきます。
-
Logger構造体- ユーザー (開発者) から呼ばれる関数を定義
-
Record構造体を生成しHandlerにわたす
-
Record構造体- ログの内容を構造体として保持する
-
Handlerインターフェイス-
Record構造体を受け取り処理する
-
図に表すと以下のような関係性になります。
基本的なAPI (使い方)
ここで紹介しているAPIは後にパフォーマンスの話で出てくるので、先に使い方を軽く説明しておきます。
Info メソッド
Infoメソッドを使うサンプルコードは以下のような形で実装できます。
func main() {
h := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{})
logger := slog.New(h)
logger.Info("some message", "userId", 123, "name", "pana")
}
-
slog.NewJSONHandlerメソッドでHandlerインターフェイスを生成します- 第二引数はソースコードの出力有無を決めるためのオプションの設定になります
-
slog.New()メソッドでLogger構造体を生成します - 最後に
Infoメソッドを呼んで値を出力します
実行してみると以下のような結果になります。
❯ go run ./main.go
{"time":"2023-12-06T18:29:07.117423+09:00","level":"INFO","msg":"some message","userId":123,"name":"pana"}
timeとlevelがデフォルトで出力され、some messageの部分はmsgというkeyのvalueとして出力されます。その後の値はkey-valueペアとして出力されます。
内部の実装を見てみる
少しだけ内部の実装を見てみましょう。
Infoメソッドは以下のような実装を持っています。
func (l *Logger) Info(msg string, args ...any) {
l.log(context.Background(), LevelInfo, msg, args...)
}
第一引数はstring型、第二引数として任意の可変長引数を受け取れるようになっています。
LevelInfoというのが登場してきますが、これはログレベルのことです。この記事が執筆された2023年12月現時点では4つのログレベルが定義されています。
type Level int
const (
LevelDebug Level = -4
LevelInfo Level = 0
LevelWarn Level = 4
LevelError Level = 8
)
連続した整数ではなく、飛び飛びの値になっているのはユーザー (開発者) 自身でカスタムなログレベルを設定できるようにということです。
さて、続いてはl.log(context.Background(), LevelInfo, msg, args...)をみていきます。
func (l *Logger) log(ctx context.Context, level Level, msg string, args ...any) {
// Enabledメソッドを呼んでfalseの場合は早期returnしている
if !l.Enabled(ctx, level) {
return
}
var pc uintptr
if !internal.IgnorePC {
var pcs [1]uintptr
runtime.Callers(3, pcs[:])
pc = pcs[0]
}
r := NewRecord(time.Now(), level, msg, pc) // Record構造体を生成
r.Add(args...) // 任意の可変長引数をAddメソッドでRecord構造体に追加
if ctx == nil {
ctx = context.Background()
}
_ = l.Handler().Handle(ctx, r) // HandlerインターフェイスのHandleメソッドを呼ぶ
}
詳しい解説は省きますが、NewRecordメソッドでRecord構造体を生成し、HandlerインターフェイスのHandleメソッドに生成したRecord構造体を渡しています。先程、図で説明したようなアーキテクチャになっていることが分かるかと思います。
With メソッド
次はWithメソッドについてみていきます。Withメソッドは以下のようにして使うことができます。
func main() {
h := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{})
logger := slog.New(h)
logger2 := logger.With("userId", 123, "name", "pana")
logger2.Info("message 1")
logger2.Info("message 2")
}
実際に動かしてみると以下のように出力されます。
❯ go run ./main.go
{"time":"2023-12-07T11:15:33.314018+09:00","level":"INFO","msg":"message 1","userId":123,"name":"pana"}
{"time":"2023-12-07T11:15:33.314355+09:00","level":"INFO","msg":"message 2","userId":123,"name":"pana"}
Withメソッドを使えば同じメッセージを出力できるようになっています。
WithGroup メソッド
最後にWithGroupメソッドについても紹介しておきます。
func main() {
h := slog.NewJSONHandler(os.Stdout, &slog.HandlerOptions{})
logger := slog.New(h)
logger2 := logger.WithGroup("group")
logger2.Info("message 1", "userId", 123, "name", "pana")
}
実際に動かしてみると以下のように出力されます。
❯ go run ./main.go
{"time":"2023-12-07T11:18:55.541999+09:00","level":"INFO","msg":"message 1","group":{"userId":123,"name":"pana"}}
WithGroupメソッドを使えば、key-valueをまとめて出力できるようになっています
パフォーマンスに関して
ここからがいよいよ本題です。
log/slogパッケージで使用されているパフォーマンスの秘密に迫っていきます。
log/slogでいうパフォーマンスとは?
log/slogでいうパフォーマンスとはメモリアロケーションのことです。つまり、アロケーションを可能な限り起こさないような実装になっています。
どこでパフォーマンスが意識されている?
筆者が調べた限りだと以下の構造体やインターフェイス、メソッドに現れていました。
-
Logger構造体 -
Handlerインターフェイス -
Record構造体 -
Attr(Value) 構造体
他にも色々あると思いますが、この記事では上記に絞ってパフォーマンスの最適化についてみていきたいと思います!
Logger 構造体
まずはLogger構造体からです。
インターフェイスではなく、構造体として定義することでインライン展開が可能になるのでパフォーマンスが良くなるというのが結論になります。
インライン展開とは
まずはインライン展開について説明します。Wikipediaを見てみます。
関数を呼び出す側に呼び出される側の関数のコードを展開し、関数への制御転送をしないようにする方法。これにより関数呼び出しに伴うオーバーヘッドを削減する (Wikipediaより抜粋)
つまりは、関数の呼び出しのオーバーヘッドを減らすためのテクニックといえます。
Goの場合は、コンパイラがいい感じにインライン展開してくれます。ちなみにインライン展開できるかどうかは細かい条件があります。
インライン展開を見てみる
メソッドの呼び出し方
- 直接呼び出し
- 構造体を介した呼び出し
- インターフェイスを介した呼び出し
の3つのパターンについて、インライン展開がどう効いてくるのかを見てみます。
コードは以下のようなものを使ってみます (わかりやすいように行番号を付与してます)。
❯ bat ./main.go
───────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
│ File: ./main.go
───────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
1 │ package main
2 │
3 │ import "fmt"
4 │
5 │ type double interface {
6 │ Double(n int) int
7 │ }
8 │
9 │ type d struct{}
10 │
11 │ func (d) Double(n int) int {
12 │ return n * 2
13 │ }
14 │
15 │ func Double(n int) int {
16 │ return n * 2
17 │ }
18 │
19 │ func main() {
20 │ fmt.Println(Double(4))
21 │
22 │ var structD d = d{}
23 │ fmt.Println(structD.Double(4))
24 │
25 │ var interfaceD double = d{}
26 │ fmt.Println(interfaceD.Double(4))
27 │ }
───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
まずは最適化オプションを有効化してビルドしてみます。
inlining call to...というログはインライン展開されていることになります。
❯ go build -gcflags=-m ./main.go
# command-line-arguments
./main.go:11:6: can inline d.Double
./main.go:15:6: can inline Double
./main.go:20:20: inlining call to Double # 直接呼び出し
./main.go:20:13: inlining call to fmt.Println
./main.go:23:28: inlining call to d.Double # 構造体を介した呼び出し
./main.go:23:13: inlining call to fmt.Println
./main.go:26:13: inlining call to fmt.Println
<autogenerated>:1: inlining call to d.Double
./main.go:26:31: devirtualizing interfaceD.Double to d
./main.go:20:13: ... argument does not escape
./main.go:20:20: ~R0 escapes to heap
./main.go:23:13: ... argument does not escape
./main.go:23:28: ~R0 escapes to heap
./main.go:25:27: d{} does not escape
./main.go:26:13: ... argument does not escape
./main.go:26:31: d.Double(interfaceD.(d), 4) escapes to heap # インターフェイスを介した呼び出し
注目してほしい箇所にはコメントしてますが、直接呼び出しと構造体を介した呼び出しはインライン展開されていますが、インターフェイスを介した呼び出しはインライン展開されていないようです。
ついでに実行ファイルを逆アセンブルしてみます。
ソースコードをビルドして、go tool objdump mainを実行すると逆アセンブルの結果を取得できます (参考: https://pkg.go.dev/cmd/objdump )。
得られた結果の一部は以下になります。
# (直接呼び出しの行の逆アセンブルの結果)
main.go:20 0x1086eb2 440f117c2448 MOVUPS X15, 0x48(SP)
main.go:20 0x1086eb8 b808000000 MOVL $0x8, AX
main.go:20 0x1086ebd 0f1f00 NOPL 0(AX)
main.go:20 0x1086ec0 e89b24f8ff CALL runtime.convT64(SB)
main.go:20 0x1086ec5 488d0d94770000 LEAQ _type:*+30080(SB), CX
main.go:20 0x1086ecc 48894c2448 MOVQ CX, 0x48(SP)
main.go:20 0x1086ed1 4889442450 MOVQ AX, 0x50(SP)
# (構造体を介したメソッド呼び出しの行の逆アセンブルの結果)
main.go:23 0x1086ef6 440f117c2438 MOVUPS X15, 0x38(SP)
main.go:23 0x1086efc b808000000 MOVL $0x8, AX
main.go:23 0x1086f01 e85a24f8ff CALL runtime.convT64(SB)
main.go:23 0x1086f06 488d0d53770000 LEAQ _type:*+30080(SB), CX
main.go:23 0x1086f0d 48894c2438 MOVQ CX, 0x38(SP)
main.go:23 0x1086f12 4889442440 MOVQ AX, 0x40(SP)
# (インターフェイスを介したメソッド呼び出しの行の逆アセンブルの結果)
main.go:26 0x1086f37 b804000000 MOVL $0x4, AX
main.go:26 0x1086f3c 0f1f4000 NOPL 0(AX)
main.go:26 0x1086f40 e83bffffff CALL main.d.Double(SB)
main.go:26 0x1086f45 440f117c2428 MOVUPS X15, 0x28(SP)
main.go:26 0x1086f4b e81024f8ff CALL runtime.convT64(SB)
main.go:26 0x1086f50 488d0d09770000 LEAQ _type:*+30080(SB), CX
main.go:26 0x1086f57 48894c2428 MOVQ CX, 0x28(SP)
main.go:26 0x1086f5c 4889442430 MOVQ AX, 0x30(SP)
少し分かりにくいですが、インターフェイスを介したメソッド呼び出しの行の逆アセンブルの結果の部分にCALL main.d.Double(SB)という記述があり、メソッドが呼び出されていることがわかります。
逆に、直接呼び出しのケースと構造体を介したメソッド呼び出しのケースの逆アセンブルの結果では、Doubleというメソッドを呼び出した形跡がないので、呼び出し元に展開されている (インライン展開されている) ことがわかります。
ここまでの調査結果をまとめると
-
インターフェイス経由でのメソッド呼び出しはインライン展開されない場合がある (されることもある)
- 関数呼び出しにオーバーヘッドが生じるのでパフォーマンスに影響する可能性がある
- log/slogではどこで意識されているのか?
-
Loggerはインターフェイスではなく構造体になっている - 呼び出し側でインターフェイスによる間接的なメソッド呼び出しにならないようにしている
-
Infoメソッドなどはインターフェイス経由ではなく直接呼び出せるようになっている
-
ということになります!
Handler インターフェイス
続いてHandlerインターフェイスです。
以下の4つのメソッドが定義されていますが、ここではEnabledメソッドとWithAttrsメソッドに注目します。
type Handler interface {
Enabled(context.Context, Level) bool
Handle(context.Context, Record) error
WithAttrs(attrs []Attr) Handler
WithGroup(name string) Handler
}
Enabledメソッドについて
このメソッドはLogger構造体から呼ばれる各メソッドで最初に呼ばれる関数となり、不必要にログを出力させない (関数を実行させない) というパフォーマンスが意識されています。
具体例として先程のInfoメソッドを見てみます。
func (l *Logger) Info(msg string, args ...any) {
l.log(context.Background(), LevelInfo, msg, args...)
}
さらにl.logメソッドは以下のようになっています。
func (l *Logger) log(ctx context.Context, level Level, msg string, args ...any) {
if !l.Enabled(ctx, level) {
return
}
var pc uintptr
// 省略
l.Enabledは以下のような定義になっており、最終的にHandlerインターフェイスのHandleメソッドが呼ばれます。
func (l *Logger) Enabled(ctx context.Context, level Level) bool {
if ctx == nil {
ctx = context.Background()
}
return l.Handler().Enabled(ctx, level)
}
そして最終的なHandleメソッドは以下のように定義されています。
// JSONハンドラーが実装しているEnabledメソッド
func (h *JSONHandler) Enabled(_ context.Context, level Level) bool {
return h.commonHandler.enabled(level)
}
func (h *commonHandler) enabled(l Level) bool {
minLevel := LevelInfo
if h.opts.Level != nil {
minLevel = h.opts.Level.Level()
}
return l >= minLevel
}
つまり、不必要なログを出さないためにログレベルに応じて後続の処理を行うかどうかの判断をしているメソッドといえます。早期return (early return) と似たような感じですね。
WithAttrsメソッド
続いてWithAttrsメソッドについてもみていきます。
シグネチャは以下の通りで、Attr構造体(後述)のスライスを受け取り、Handlerインターフェイスを返しています。
type Handler interface {
WithAttrs(attrs []Attr) Handler
// 他のメソッド
}
結論を先に述べると、新しく返されるHandlerインターフェイスは内部的に引数のattrsを[]byteとして保持しており、新しいHandlerインターフェイスはあらかじめ保持しておいたattrsを引き出すことができるのでパフォーマンスが良くなるということになります。
もう少し詳細を見ていきます。
途中のコードリーディングは省きますが、先程述べたように引数のattrsは最終的にHandlerインターフェイスが内部的にもつhandleStateのbufフィールドに保存されます。
type handleState struct {
h *commonHandler
buf *buffer.Buffer // ここに引数のattrsが保存される
freeBuf bool
sep string
prefix *buffer.Buffer
groups *[]string
}
そして型の*buffer.Bufferは、sync.Poolを使って以下のように定義されています。
sync.Poolはfmtパッケージやencoding/jsonパッケージでも使用されている高速化のための関数です。パフォーマンスに関するベンチマークは既に様々な記事で解説されているので、この記事では省きます。
package buffer
type Buffer []byte
var bufPool = sync.Pool{
New: func() any {
b := make([]byte, 0, 1024)
return (*Buffer)(&b)
},
}
func New() *Buffer {
return bufPool.Get().(*Buffer)
}
Handlerインターフェイスを実装した構造体が生成される過程で、New関数が呼ばれてsync.Poolであらかじめ確保されている[]byteが内部的に使用されるようになっています。
さらにsync.Poolを使っているので、New関数が呼ばれるたびにメモリが確保されるのではなく、最初に初期化された[]byteがHandlerメソッド内で使いまわされるという形になっています。
まとめると
-
sync.Poolを使うことによってHandlerのメソッドを呼ぶたびに都度メモリを確保しないようになっている -
引数の
attrsは新しいHandlerで内部的に保持された状態になっており、新しいHandlerではそのあらかじめ保存されたattrsを使うことで、同じ処理を行わないようになっている
ということになります!
Record 構造体 (Addメソッド)
まだまだあるのでどんどん紹介していきます。
冒頭のInfoメソッドの紹介と内部のコードリーディングで説明した箇所に戻りますが、任意の可変長引数をRecord構造体に追加してるAddメソッドを見てみます。
func (r *Record) Add(args ...any) {
var a Attr
for len(args) > 0 {
a, args = argsToAttr(args) // 可変長引数のanyをAttr構造体に変換
if a.Value.isEmptyGroup() {
continue
}
// Attr構造体をfrontとbackに詰めている
if r.nFront < len(r.front) {
r.front[r.nFront] = a
r.nFront++
} else {
if r.back == nil {
r.back = make([]Attr, 0, countAttrs(args))
}
r.back = append(r.back, a)
}
}
}
ここに隠されているパフォーマンスの最適化は、任意の可変長引数anyをRecord構造体に追加する際にメモリの確保が多くても1回しか起こらないようになっている、です。
詳細を見ていきます。
まずはRecord構造体の定義から見ていきます。
type Record struct {
Time time.Time
Message string
Level Level
PC uintptr
front [nAttrsInline]Attr
nFront int
back []Attr
}
Time, Message, Level, PCは時間やメッセージ、ログレベルとプログラムカウンターを保持するための公開フィールドです。
パフォーマンスに影響している部分はfront, nfront, backの部分です。Attr構造体の具体的な定義は特に大事ではないですが、可変長引数のanyをkey-valueのペアとして扱うための構造体と思ってください。またnAttrsInlineは以下のように定数として定義されています。
const nAttrsInline = 5
つまり、Record構造体が作成された時点で、frontには長さ5の配列が初期化されており、backはnilスライスになっているということです。
そして、これを踏まえて先程のAdd関数で重要なのは以下の部分です。
func (r *Record) Add(args ...any) {
// ...
// Attr構造体をfrontとbackに詰めている
if r.nFront < len(r.front) {
r.front[r.nFront] = a
r.nFront++
} else {
if r.back == nil {
r.back = make([]Attr, 0, countAttrs(args))
}
r.back = append(r.back, a)
}
}
}
最初はnFrontは0なので、if分の中の処理が実行され、長さ5の配列のfrontの部分が順次埋まっていきます。そして、front部分が全て埋まれば、anyの可変長引数をAttr構造に変換した単位でnilスライスだったbackが初期化されます。
append(r.back, a)という形で追加されているものの、backが初期化される際には長さは0で容量が値を持っている形になっているので、appendによるメモリの再確保は起きません。
さて、ここで疑問なのがなぜ、nAttrsInline=5となっているのでしょうか?
その疑問に対する回答としては「zapの使い方から使用されるkey-valueの個数を調査したところ、9割ぐらいのログが5つのkey-valueを出力していた」ということから5という数字が採用されています。
下記のグラフは横軸がログに出力されているkey-valueの個数と縦軸がそのログが全体に占める割合(%)です。(こちらのグラフはlog/slogパッケージの開発者の1人であるJonathan Amsterdam(jba)さんにいただきました。ありがとうございました。)
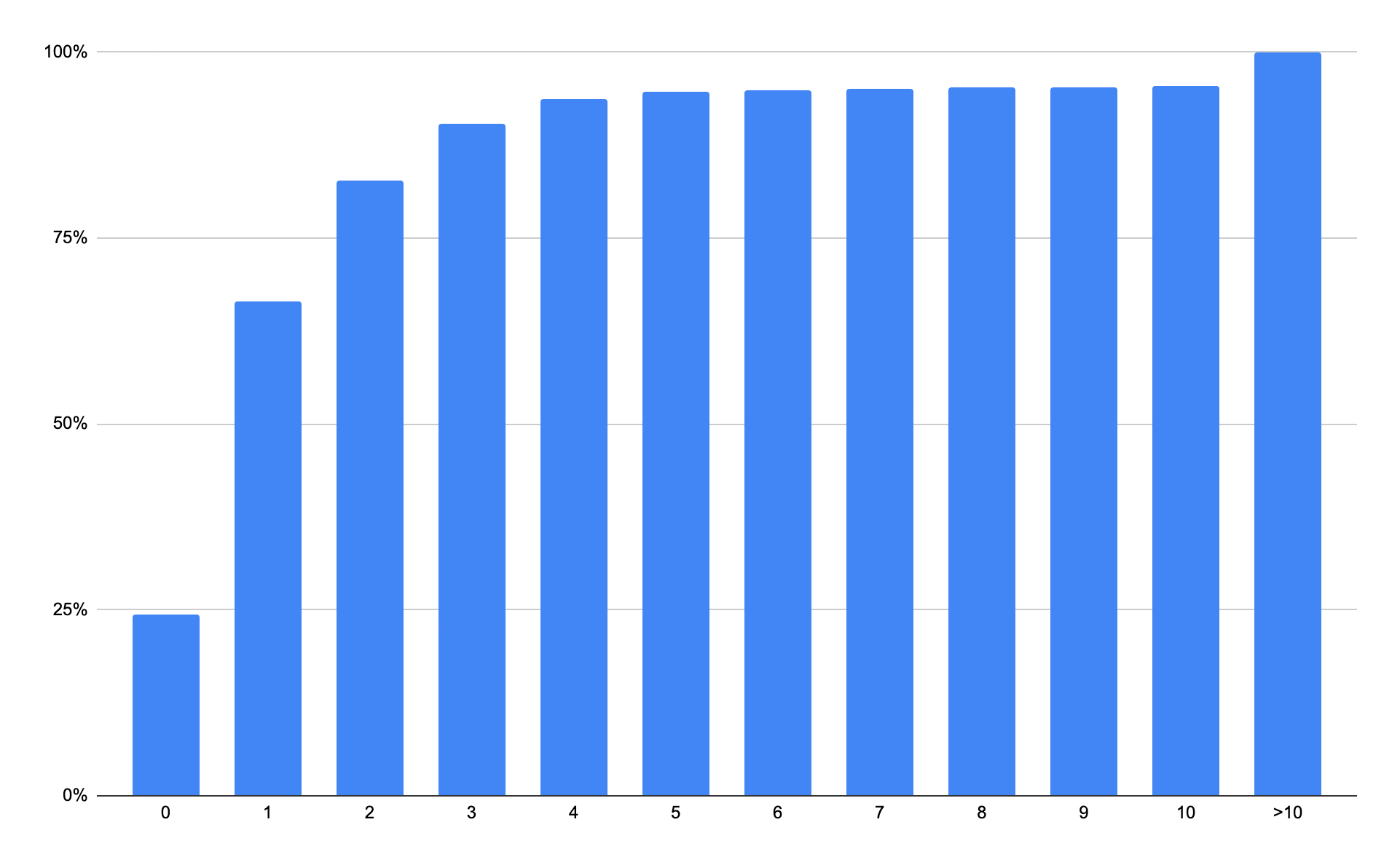
例えば、一番左側のグラフは横軸が0で、縦軸は約25%になっています。つまり、1つもkey-valueを出力していないログがzapのログ全体の約25%ほどあった、と解釈できます。
このグラフから
- key-valueを5つまで出力するログが全体の約90%
- 言い換えると6つ以上のkey-valueを出力するログは全体の約10%
ということが分かると思います。このような調査を行った上でnAttrsInline = 5として定義されています。
まとめると
- zapの使い方から使用されるkey-valueの個数を調査していた
- 最初にその個数分のメモリだけ初期化し、追加でメモリの再確保が可能な限り起きないようになっていた (起きたとしても1回)
となります!
Attr 構造体/Value 構造体
最後のAttr構造体(Value構造体)です。
Attr構造体とValue構造体はそれぞれ以下のような定義になっています。
-
Attr構造体
type Attr struct {
Key string
Value Value
}
-
Value構造体
type Value struct {
_ [0]func() // ==の演算を禁止するためのイディオマティックな書き方
num uint64
any any
}
先程のRecord構造体のAdd関数で見たように、ログに渡せるanyの可変長引数はkey-valueとしてAttr構造体に変換されます。そして、そのvalueはValue構造体に変換されます。
つまり、Value構造体のuint64とanyだけで、任意のGoの値を表現できることになります。
なぜ、anyをそのままanyとして使用せず、Value構造体を定義したのでしょうか?
答えとしてはValue構造体を用いた方がanyを使うより少しだけメモリ効率が良くなるからです。例として文字列(string型)をValue構造体とany構造体で表現した時にどういう差が出るのか見てみます。
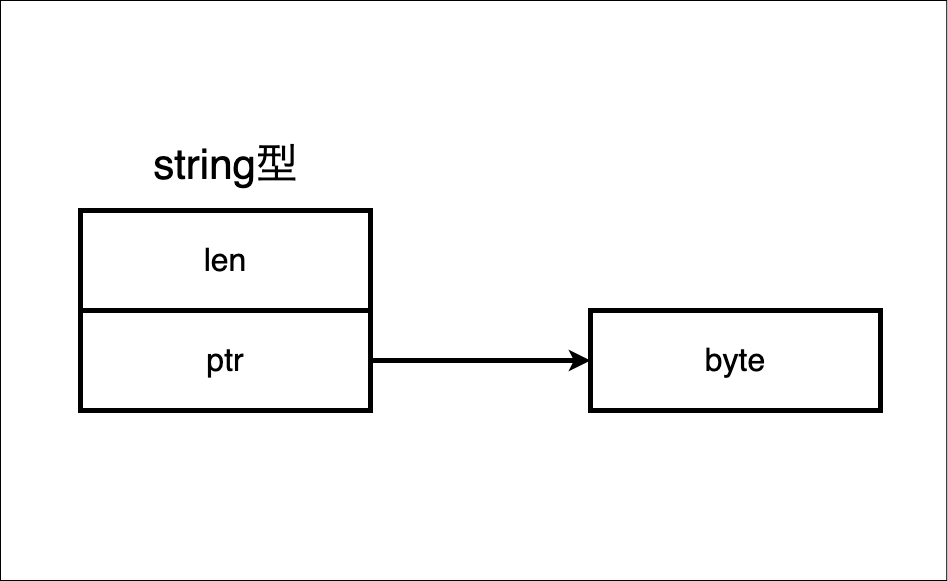
(おさらい) Goでのstring型とany型のデータ構造
string型は
- 文字列の長さ (
len) - 文字を表現するbyteへのポインタ (
ptr)
の2ワード分のメモリが必要になります。図にすると以下のような感じになります。
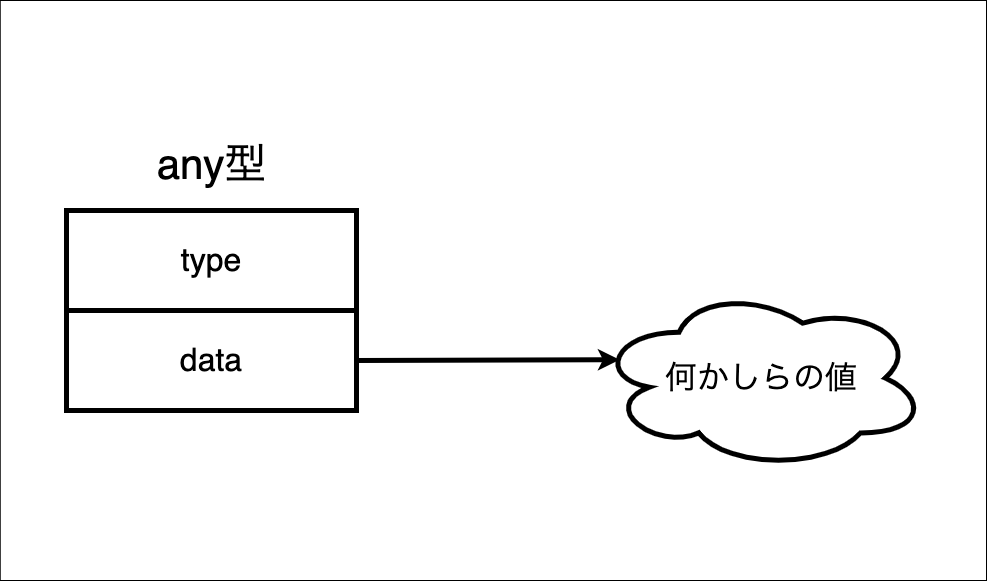
またany型は
- 型の情報 (
type) - 実際の値へのポインタ (
data)
の2ワード分のメモリが必要になります。図にすると以下のような感じになります。
詳細はRuss Coxさんの以下のブログをみてもらえるとわかります。
文字列をanyとして表現する
まずは文字列をanyとして表現するケースを見てみます。
図にすると以下のような形になると思います。
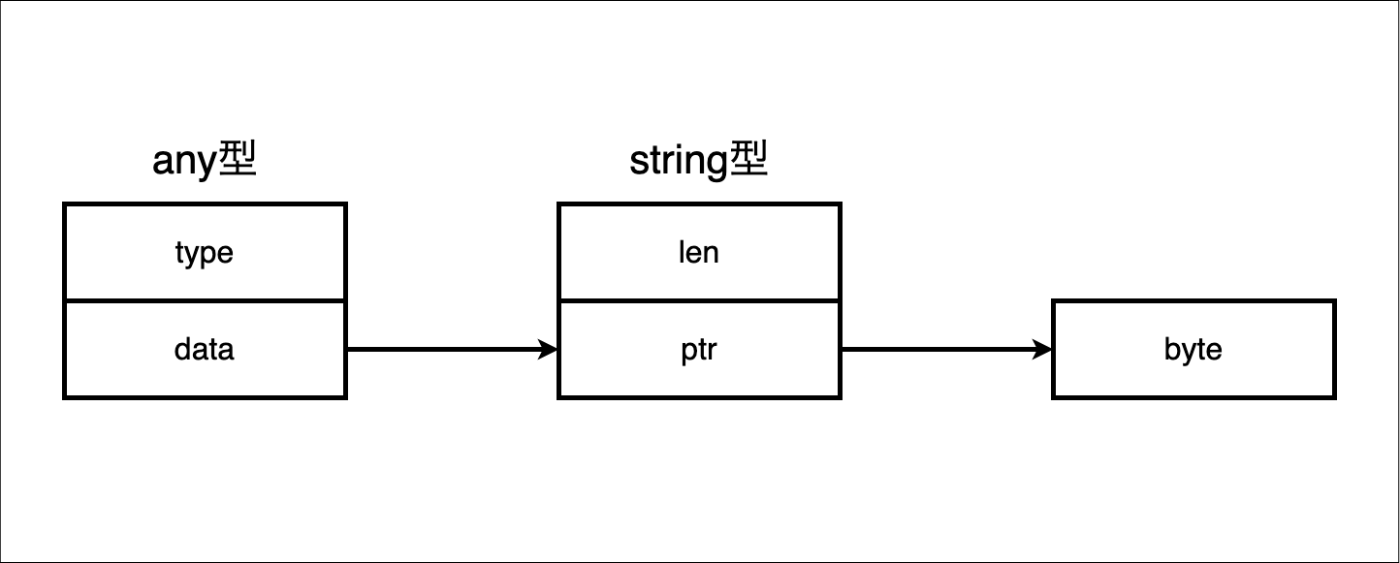
つまり、1つの文字列(byte)を表現するのに4ワード分のメモリが必要ということになります。
文字列をValueとして表現する
続いて文字列をValue構造体として表現するケースを見てみます。
以下のStringValueメソッドは、string型の引数を受け取ってValue構造体を生成するメソッドになります。
type stringptr *byte
func StringValue(value string) Value {
return Value{num: uint64(len(value)), any: stringptr(unsafe.StringData(value))}
numはunint64(len(value))なので、文字列の長さの情報を持っています。そして、anyはstringptr(unsafe.StringData(value))となっており、byteへのポインタを持っていることが分かります。
つまり、本来なら string型が持つbyteへのポインタをanyが持つことによって、その分のメモリ(1ワード分のメモリ)が不必要になっているのです。
実際に確かめてみる
先程のメモリの話を実際にdelveを使って確かめてみたいと思います。
以下のコードを解析対象にします (行番号が分かりやすようにしてます)。
❯ bat ./main.go
───────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
│ File: ./main.go
───────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
1 │ package main
2 │
3 │ import (
4 │ "fmt"
5 │ "unsafe"
6 │ )
7 │
8 │ type stringptr *byte
9 │
10 │ type Value struct {
11 │ _ [0]func()
12 │ num uint64
13 │ any any
14 │ }
15 │
16 │ func StringValue(value string) Value {
17 │ return Value{num: uint64(len(value)), any: stringptr(unsafe.StringData(value))}
18 │ }
19 │
20 │ func main() {
21 │ str := "abcde"
22 │
23 │ var s any = str
24 │ fmt.Println(s)
25 │
26 │ var ss Value = StringValue(str)
27 │ fmt.Println(ss)
38 │ }
───────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
まずは、s (文字列をanyとして表現した場合) のメモリを調査します。"abc"という文字列はバイトでは61 62 63です。
❯ dlv debug ./main.go
Type 'help' for list of commands.
(dlv) b main.go:24
Breakpoint 1 set at 0x10ae80f for main.main() ./main.go:24
(dlv) c
> main.main() ./main.go:24 (hits goroutine(1):1 total:1) (PC: 0x10ae80f)
19:
20: func main() {
21: str := "abc"
22:
23: var s any = str
=> 24: fmt.Println(s)
25:
26: var ss Value = StringValue(str)
27: fmt.Println(ss)
28: }
(dlv) p s
interface {}(string) "abc"
(dlv) p *((*runtime.iface)(uintptr(&s)))
runtime.iface {
tab: *runtime.itab {
inter: *(*"internal/abi.InterfaceType")(0x10),
_type: *(*"internal/abi.Type")(0x8),
hash: 125357496,
_: [4]uint8 [7,8,8,24],
fun: [1]uintptr [17639976],},
data: unsafe.Pointer(0xc000014290),}
(dlv) x -fmt hex -count 16 -size 1 0xc000014290
0xc000014290: 0x5d 0xa8 0x0c 0x01 0x00 0x00 0x00 0x00
0xc000014298: 0x03 0x00 0x00 0x00 0x00 0x00 0x00 0x00
(dlv) x -fmt hex -count 1 -size 8 0xc000014290
0xc000014290: 0x00000000010ca85d
(dlv) x -fmt hex -count 5 -size 1 0x00000000010ca85d
0x10ca85d: 0x61 0x62 0x63 0x6e 0x69 # a b cが格納されている!!
(dlv) exit
上記の結果をまとめると
-
anyのdataはunsafe.Pointer(0xc000014290)となっている (string型へのポインタ) -
0xc000014290を調べると0x00000000010ca85dが表示された (byteへのポインタ) -
0x00000000010ca85dを調べると0x61, 0x62, 0x63が表示されて、ちゃんと"abc"と対応している
たしかにanyのdataの部分が、string型へのポインタになっており、string型がbyteへのポインタを持っていることがわかりました。
続いて、ss (文字列をValue構造体として表現した場合) のメモリを調査します。
❯ dlv debug ./main.go
Type 'help' for list of commands.
(dlv) b main.go:27
Breakpoint 1 set at 0x10ae884 for main.main() ./main.go:27
(dlv) c
abc
> main.main() ./main.go:27 (hits goroutine(1):1 total:1) (PC: 0x10ae884)
22:
23: var s any = str
24: fmt.Println(s)
25:
26: var ss Value = StringValue(str)
=> 27: fmt.Println(ss)
28: }
(dlv) p ss
main.Value {
_: [0]func() [],
num: 3,
any: interface {}(main.stringptr) *97,}
(dlv) p ss.any
interface {}(main.stringptr) *97
(dlv) p *((*runtime.iface)(uintptr(&ss.any)))
runtime.iface {
tab: *runtime.itab {
inter: *(*"internal/abi.InterfaceType")(0x8),
_type: *(*"internal/abi.Type")(0x8),
hash: 174749434,
_: [4]uint8 [15,8,8,54],
fun: [1]uintptr [17639928],},
data: unsafe.Pointer(0x10ca85d),}
(dlv) x -fmt hex -count 16 -size 1 0x10ca85d
0x10ca85d: 0x61 0x62 0x63 0x6e 0x69 0x6c 0x31 0x32
0x10ca865: 0x35 0x36 0x32 0x35 0x4e 0x61 0x4e 0x45
(dlv) exit
上記の結果をまとめると
-
anyのdataはunsafe.Pointer(0x10ca85d)となっている -
0x10ca85dを調べると0x61, 0x62, 0x63となっていて、"abc"と対応している
anyが直接バイトへのポインタを持っていることが確かめられました!
まとめると、anyをそのままanyとして扱うのではなく、Value構造体に変換した方が少しだけメモリ効率が良いということになります!
まとめ/感想
- Go1.21でリリースされたlog/slogパッケージは構造化ログを生成する初の標準パッケージ
- パフォーマンスについて色々な工夫が見られた
- 特にメモリのアロケーションを何回も行わない工夫が見られた
- 突き詰めて実装コードを読んでみると、意外と難しいことはやっていないように思えた
- Goの言語仕様をきちんと理解した上の設計/実装になっていた
実務ではここまでパフォーマンスを意識することはあんまりないかもしれないと思いました。しかし、log/slogパッケージで実装されている内容は結構学びのある内容だったのと、意外とそこまで難しくない実装だったので頑張ってOSSにコントリビュートしてみたいと思います!
Discussion