こんにちは。Nishikaデータサイエンティストの山口と申します。
本記事では、レイヤードアーキテクチャでのSlack Bot開発を通じて感じたソフトウェアアーキテクチャの重要性について共有します。
なお、本記事で紹介するBotは以下の記事に記載の反省を元に実装いたしました。
サマリ
レイヤードアーキテクチャを採用することで、以前作ったETLバッチ処理のような構成から、

以下のようにソフトウェアアーキテクチャを整理することができました。

上記のように何か特定のソフトウェアアーキテクチャを意識した実装をすることで、以下のメリットがあったと感じております。
- ある程度ディレクトリ構成を決めた上で実装に着手できるため、どのファイルに何を書けばいいか迷うことが減る。
- ex. LLMのプロンプト変更をするときは、LLM.generate_promptメソッドを変更するだけで良い
- 処理が見やすい
- ex. アプリケーション層におけるuse_cases.pyでは、generated_sql_and_viewのようなわかりやすい名前の処理だけ書いておけば良い。
- 修正、変更漏れが減る。
- ex. 環境変数の読み込み(.envで全て読み込んでいたが、一部.env.localだったとか)
アプリについて
主題ではないですが、作成したアプリは以下になります。
- slack上で @bot名 をつけて質問することで実行する自社サービスのKPI分析bot
- input: ユーザー質問(ex. 直近6ヶ月の売上とサーバーコストを教えて)
- output:
- BigQueryに投げるSQL
- BigQueryからSELECTしたデータ(.csvで添付)
- 実現方法:
- ユーザーの質問を、以下3種類の意図に分類する(langgraphのstate)
- 新規集計
- 集計の修正/追加集計(直前の集計結果を考慮した処理)
- その他(集計はせず回答だけ返す)
- ユーザーの質問を、以下3種類の意図に分類する(langgraphのstate)
こちらのアプリを、レイヤードアーキテクチャに従い、以下4層に分けて実装いたしました。
- インターフェース層: Slack経由でユーザーとの入出力を制御
- アプリケーション層: 要件定義などに記載されてるユースケースを定義(ユーザーの意図を理解する、クエリとCSVを生成する、etc)
-
ドメイン層:
- ユースケースを実現するロジックを定義(クエリのビルド、修正)
- インフラ層を利用するためのポートを定義。
-
インフラ層:
- llm.py: プロンプトの定義、OpenAI、Anthropicへのリクエスト送受信
- db.py: bigqueryへクエリへ送信。DataFrameとして結果を受け取る。
- config.py: 環境変数のロード。
また、src/のディレクトリ構成は以下になります。
.
├── main.py
└── slack_text_to_sql
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-311.pyc
│ ├── __init__.cpython-312.pyc
│ ├── config.cpython-311.pyc
│ └── config.cpython-312.pyc
├── application #アプリケーション層
│ ├── __init__.py
│ ├── __pycache__
│ └── use_cases.py # ユースケース定義
├── domain #ドメイン層
│ ├── __init__.py
│ ├── __pycache__
│ ├── conversation_state.py # 会話の状態、ユーザー質問の意図
│ ├── ports.py #インフラ層を利用するためのポート
│ ├── query_builder.py # クエリ生成
│ ├── reply_builder.py # 返信
│ └── view_retriever.py # クエリ実行してSELECT XX FROM table
├── infrastructure #インフラ層
│ ├── __pycache__
│ ├── config.py
│ ├── db.py # BigQuery
│ ├── langgraph_flow.py
│ └── llm.py #プロンプト定義
└── interface #インターフェース層
├── __pycache__
├── http
└── slack_handler.py # ユーザーとの入出力を制御
具体的なメリット
実装を通じて感じたメリットについて、具体的に共有いたします。
1. 実装のシンプルさ
最初の実装は大変だったのですが、4層で責務を分けているため、各層の実装がシンプルになり、可読性が上がりました。本アプリの機能に含まれる、クエリ生成の実装に絞って、流れを見ていきます。
概要理解のため、ユーザーから質問を受け取って、クエリとCSVを返すまでの流れを示します。
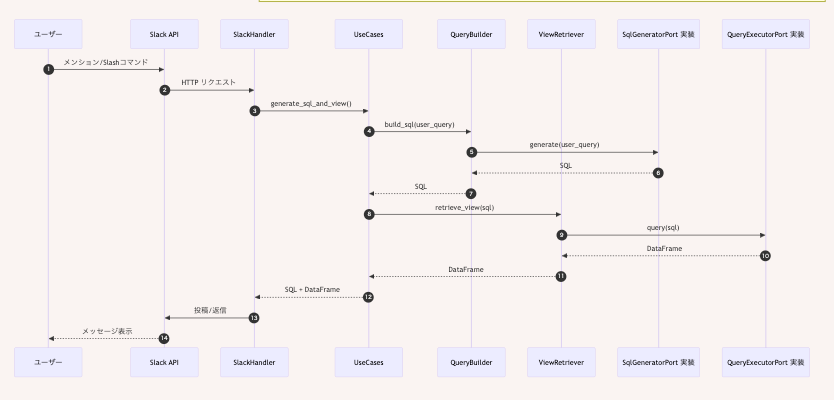
1.1. インターフェース層
最初に、インターフェース層の実装を見ていきます。
インターフェース層では、ユーザーのクエリを受け取る→アプリケーション層へ渡す→受け取ったクエリとCSVをユーザーに返す、という実装が必要です。
以下のコードでは、ユーザーから受け取ったクエリ(user_query)を、handle_message(メッセージを取り扱う)で受け取り、うまいこと扱ってくださいと、アプリケーション層側の処理(handle_user_query)に任せることで、クエリ(result_text)とCSV化するデータフレーム(view_df)を受け取っています。
import io
from logging import getLogger
from typing import Any
import polars as pl
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
from slack_sdk.web.slack_response import SlackResponse
from slack_text_to_sql.application.use_cases import UseCases
from slack_text_to_sql.infrastructure.config import Settings
logger = getLogger(__name__)
class SlackHandler:
def __init__(self, settings: Settings) -> None:
"""Slackクライアントを初期化"""
self.client = WebClient(token=settings.slack_bot_token)
self.channel_id = settings.slack_channel_id
settings = settings
def handle_message(self, user_query: str, thread_ts: str) -> None:
"""
ユーザークエリを受け取り、SQLとビューを生成してSlackに送信
"""
try:
usecases = UseCases()
previous_sql = self._get_previous_sql_from_thread(thread_ts)
intent, result_text, view_df = usecases.handle_user_query(
user_query=user_query,
previous_sql=previous_sql,
)
except Exception as exc: # noqa: BLE001 - Slack通知に詳細を含めるため
logger.exception("SQL生成またはBigQuery実行時にエラーが発生しました")
self.reply_error(
error_message=str(exc),
channel=self.channel_id,
thread_ts=thread_ts,
)
return
if intent == "question":
self.reply_text(
message=result_text,
channel=self.channel_id,
thread_ts=thread_ts,
)
return
if view_df is None:
logger.warning("ビューが取得できませんでした。空のデータフレームを送信します。")
view_df = pl.DataFrame()
formatted_sql = f"```\n{result_text}\n```"
self.reply_message(
sql=formatted_sql,
view_df=view_df,
channel=self.channel_id,
thread_ts=thread_ts,
)
def reply_message(
self,
sql: str,
view_df: pl.DataFrame,
channel: str | None = None,
thread_ts: str | None = None,
) -> bool:
"""
Slackにメッセージを送信
送信するメッセージは以下
- 生成されたSQL
- 生成されたビューのCSV
"""
# 略。ここでユーザーへメッセージを返す
1.2. アプリケーション層
次に、アプリケーション層の実装を見ていきます。
今回はクエリとCSVの生成に絞るため、handle_user_queryから呼ばれるgenerate_sql_and_viewに絞って見ていきます。
langgraphで処理分岐しているので少しややこしいのですが、
以下の2行で、クエリの生成を行っています。
state = self.conversation_flow.execute(user_query=user_query)
generated_sql = state.generated_sql
- use_cases.py
"""アプリケーション層のユースケース。"""
from __future__ import annotations
from typing import Tuple
import polars as pl
from slack_text_to_sql.domain.ports import QueryIntent
from slack_text_to_sql.domain.query_builder import QueryBuilder
from slack_text_to_sql.domain.reply_builder import ReplyBuilder
from slack_text_to_sql.domain.view_retriever import ViewRetriever
from slack_text_to_sql.infrastructure.config import get_settings
from slack_text_to_sql.infrastructure.db import BigQueryClient
from slack_text_to_sql.infrastructure.langgraph_flow import LangGraphConversationFlow
from slack_text_to_sql.infrastructure.llm import LLM, ClaudeLLM
class UseCases:
"""
ユースケースを集約するクラス。
slack_text_to_sql/docs/requirements_featureslist.md に記載されているユースケースを集約する。
"""
def __init__(self) -> None:
settings = get_settings()
if settings.llm_provider == "openai":
llm = LLM()
elif settings.llm_provider == "anthropic":
llm = ClaudeLLM()
else:
raise ValueError(f"Invalid LLM provider: {settings.llm_provider}")
big_query_client = BigQueryClient()
self.query_builder = QueryBuilder(sql_generator=llm)
self.view_retriever = ViewRetriever(big_query_client=big_query_client)
self.reply_builder = ReplyBuilder(reply_generator=llm)
self.conversation_flow = LangGraphConversationFlow(
query_builder=self.query_builder,
view_retriever=self.view_retriever,
intent_classifier=llm,
reply_builder=self.reply_builder,
)
def generate_sql_and_view(self, user_query: str) -> Tuple[str, pl.DataFrame]:
"""
Slackメンションされたユーザークエリから、SQLとクエリ結果のDataFrameを返す。
Args:
user_query (str): ユーザークエリ
Returns:
Tuple[str, DataFrame]: SQLとクエリ結果のDataFrame
"""
state = self.conversation_flow.execute(user_query=user_query)
generated_sql = state.generated_sql
if not generated_sql:
raise ValueError("SQLの生成に失敗しました。")
result_df = state.result_df
if result_df is None:
view_df = self.view_retriever.retrieve_view(generated_sql)
else:
view_df = result_df
# 次回のために直前のクエリを state に保持
state.previous_user_query = user_query
return generated_sql, view_df
例えば、ユーザーの質問が新規集計を意図しているとlanggraphの処理が判断した場合は、
ドメイン層のquery_builderが、SQLを生成(build_sql)します。
- langgraph_flow.py
def _handle_new_aggregate(self, state: ConversationState) -> dict:
"""新規集計ノード"""
state.log.append("→ 新規集計を実行")
sql = self.query_builder.build_sql(state.user_query)
view_df = self.view_retriever.retrieve_view(sql)
state.log.append(f"SQL生成完了: {len(sql)} 文字")
return {"generated_sql": sql, "result_df": view_df, "log": state.log}
アプリケーション側におけるクエリの生成処理としては、数行になります。
1.3. ドメイン層
次に、ドメイン層をポートと共に見ていきます。
クエリの生成を担当するモジュール、QueryBuilderは以下になります。
"""ドメインロジック: ユーザー入力を固定クエリに変換する。"""
from typing import Final
from slack_text_to_sql.domain.ports import SqlGeneratorPort
_DUMMY_SQL: Final[str] = """
SELECT
workspace_id,
deal_name,
plan,
sum(is_summary) AS 要約利用回数,
sum(duration_hours) AS 文字起こし時間_hours
FROM dummy_view
GROUP BY workspace_id, deal_name, plan
ORDER BY 要約利用回数 DESC
""".strip()
def build_dummy_sql(user_query: str) -> str:
"""
Slackメンションされたユーザークエリから、固定のSQLを返す。
Args:
user_query (str): ユーザークエリ
Returns:
str: 固定のSQL
"""
return _DUMMY_SQL
class QueryBuilder:
def __init__(self, sql_generator: SqlGeneratorPort) -> None:
self.sql_generator = sql_generator
def build_sql(self, user_query: str) -> str:
"""
Slackメンションされたユーザークエリから、SQLを生成する。
Args:
user_query (str): ユーザークエリ
Returns:
str: SQL
"""
response_sql = self.sql_generator.generate(user_query)
response_sql = self.check_and_fix_sql(response_sql)
return response_sql
def check_and_fix_sql(self, sql: str) -> str:
"""
LLMが生成したSQLのチェックを行う。
確認事項
- SELECT文のみ生成(DELETE, DROP, UPDATE, INSERT, CREATE等は禁止)
- LIMIT 1000を入れる。入っていなければ追加。
- ```sql ``` を除去。
"""
non_permitted_sql = ["DELETE", "DROP", "UPDATE", "INSERT", "CREATE"]
if any(non_permitted_sql in sql for non_permitted_sql in non_permitted_sql):
raise ValueError("DELETE, DROP, UPDATE, INSERT, CREATE等は禁止です。")
if "LIMIT 1000" not in sql:
if ";" in sql:
sql = sql.replace(";", " LIMIT 1000;")
else:
sql += " LIMIT 1000"
sql = sql.replace("```sql", "").replace("```", "") # ```sql ``` を除去。
return sql
def refine_sql(self, user_query: str, previous_sql: str) -> str:
"""
LLMが生成したSQLを、ユーザーのクエリと前回のSQLを参照して修正する。
"""
response_sql = self.sql_generator.generate(user_query=user_query, previous_sql=previous_sql, is_refine=True)
response_sql = self.check_and_fix_sql(response_sql)
return response_sql
SQLの生成にともなうロジックは、
- LLMを使ったクエリの整形
- コードブロックの削除など、後処理
の二つです。
前者については、同じドメイン層に設けたポート(ports.py)を介してインフラ層のLLM処理を呼び出しております。後者については、外部API、DBを使った処理ではないため、同じクラスに処理内容を書いています。
- ports.py
class SqlGeneratorPort(ABC):
@abstractmethod
def generate(
self,
user_query: str,
*,
is_refine: bool = False,
previous_sql: str | None = None,
) -> str:
"""
LLMが生成したSQLを、ユーザーのクエリと前回のSQLを参照して生成する。
Args:
user_query (str): ユーザーのクエリ
is_refine (bool): 修正するかどうか
previous_sql (str | None): 前回のSQL
"""
pass
後述いたしますが、上記のportを使って処理をすることで、以下のような変更があった際に、変更対応(既存コードの理解、変更箇所の多さ)が楽になると思いました。
- ロジック変更
- LLMをgeminiに変えたい。。
1.4. インフラ層
最後に、インフラ層について見ていきます。
例えば、アプリケーション層(use_cases.py)などで呼び出した環境変数は、config.pyで一括設定しています。これにより、ファイルAでは.env, ファイルBでは.env.localのように意図せず違う環境変数を使うといったスクリプトを防止できます。
- config.py
from __future__ import annotations
import os
from functools import lru_cache
from typing import Any, cast
import yaml
from dotenv import load_dotenv
from google.api_core.exceptions import NotFound
from google.cloud import storage
load_dotenv(".env")
class Settings:
def __init__(self) -> None:
"""
環境変数を読み込む
"""
self.slack_bot_token = self._require("SLACK_BOT_TOKEN")
self.slack_channel_id = self._require("SLACK_CHANNEL_ID")
self.slack_signing_secret = self._require("SLACK_SIGNING_SECRET")
self.openai_api_key = self._require("OPENAI_API_KEY")
self.anthropic_api_key = self._require("ANTHROPIC_API_KEY")
self.llm_provider = self._require("LLM_PROVIDER")
self.gcp_project_id = self._require("GCP_PROJECT_ID")
self.bq_mart_dataset_id = self._require("BQ_MART_DATASET_ID")
self.dbt_schema_gcs_uri = self._require("DBT_SCHEMA_GCS_URI")
def load_dbt_schema(self) -> dict[str, Any]:
"""dbtのスキーマを読み込む(.ymlファイル) GCSから読み込む"""
bucket_name, blob_path = self._parse_gcs_uri(self.dbt_schema_gcs_uri)
client = storage.Client(project=self.gcp_project_id)
blob = client.bucket(bucket_name).blob(blob_path)
try:
contents = blob.download_as_text(encoding="utf-8")
except NotFound as exc:
raise FileNotFoundError(f"GCS object not found: {self.dbt_schema_gcs_uri}") from exc
return cast(dict[str, Any], yaml.safe_load(contents))
@staticmethod
def _parse_gcs_uri(uri: str) -> tuple[str, str]:
if not uri.startswith("gs://"):
raise ValueError("DBT_SCHEMA_GCS_URI must start with gs://")
without_scheme = uri[len("gs://") :]
parts = without_scheme.split("/", 1)
if len(parts) != 2 or not parts[0] or not parts[1]:
raise ValueError("DBT_SCHEMA_GCS_URI must be in the format gs://bucket/path")
return parts[0], parts[1]
@staticmethod
def _require(key: str) -> str:
value = os.getenv(key)
if not value:
raise ValueError(f"{key} is not set; please define it in .env or the environment")
return value
@lru_cache(maxsize=1)
def get_settings() -> Settings:
return Settings()
- db.py
BigQuery関連の操作はdb.pyで実現しています。
本アプリでは、生成したクエリを叩いて結果をデータフレームを受け取るだけなので、シンプルな作りになっています。もし取得対象をBigQueryから乗り換える際は、このクラスを継承して処理を作り変えるなどして、対応します。
import os
import polars as pl
from google.cloud import bigquery
from slack_text_to_sql.domain.ports import BigQueryClientPort
from slack_text_to_sql.infrastructure.config import get_settings
class BigQueryClient(BigQueryClientPort):
def __init__(self) -> None:
self.settings = get_settings()
self.project_id = self.settings.gcp_project_id
self.bq_mart_dataset_id = self.settings.bq_mart_dataset_id
def query(self, sql: str) -> pl.DataFrame:
if os.getenv("SMC_USE_FAKE_BQ", "0") == "1":
from slack_text_to_sql.domain.view_retriever import get_dummy_view
return get_dummy_view()
client = bigquery.Client(project=self.project_id)
pandas_df = client.query(sql).to_dataframe()
polars_df: pl.DataFrame = pl.from_pandas(pandas_df)
return polars_df
このように、各層で責務が異なり、責務に応じて処理が独立しているため、以前作った処理と比較すると、可読性が向上し、扱いやすくなったと感じます。
1.5. portを使った依存性逆転の原則の実現
上述したports.pyは、インフラ層の具体的な実装に依存せず、インターフェース(ポート)だけを定義するファイルです。
依存性逆転のメリット
通常、上位層(ドメイン層)が下位層(インフラ層)に依存する形になりがちですが、ポートを使うことで依存関係を逆転させています。
従来の依存関係
ドメイン層(QueryBuilderなど) → インフラ層の具体実装(BigQueryClient, LLMなど)
ポートを使った依存関係
この設計により、以下のようなメリットがあります:
- テストの容易性: インフラ層の実装をモック化しやすい
# テスト用のモッククラスを簡単に作成できる
class MockBigQueryClient(BigQueryClientPort):
def query(self, sql: str) -> pl.DataFrame:
return pl.DataFrame({"col1": [1, 2, 3]})
- 責務の明確化: 各層が何を提供すべきかが型定義で明確になる
2. claude APIに乗り換える
本アプリはOpenAIのLLMでクエリ生成をしているのですが、他の処理はそのままにAnthripicのClaudeを使いたい場面を考えます。
この際、以下3点の変更を行えば、更新が完了します。
- インフラ層(llm.py): ClaudeLLMクラスとして継承し、generate関数だけanthropic APIの処理に変更
- インフラ層(config.py):llm_provider変数を用意して、.envを介してどのプロバイダーかを特定できるようにする
- アプリケーション層(use_cases.py): llm_providerの値に応じてインスタンス化するクラスを決定する
アーキテクチャ導入前は、複数の箇所でLLMを直接呼び出していたため、プロバイダー変更時にすべての箇所を修正する必要がありました。レイヤードアーキテクチャでは、インフラ層のみの変更で済むため、変更漏れを防げます。
(本アプリでは、クエリ生成とユーザーの意図理解の両方でLLMを使用しているため、どちらかを変更し忘れるシーンも出てきそうです。)
llm.pyでの変更は以下になります。
- llm.py
from datetime import datetime
from anthropic import Anthropic
from openai import OpenAI
from slack_text_to_sql.domain.ports import (
IntentClassifierPort,
QueryIntent,
ReplyGeneratorPort,
SqlGeneratorPort,
)
from slack_text_to_sql.infrastructure.config import get_settings
class LLM(SqlGeneratorPort, IntentClassifierPort, ReplyGeneratorPort):
def __init__(self) -> None:
self.settings = get_settings()
self.openai_api_key = self.settings.openai_api_key
self.gcp_project_id = self.settings.gcp_project_id
self.bq_mart_dataset_id = self.settings.bq_mart_dataset_id
self.dbt_schema = self.settings.load_dbt_schema()
self.model_name = "gpt-5-mini"
def generate_prompt(self, user_query: str) -> str:
project_dataset_id = f"{self.gcp_project_id}.{self.bq_mart_dataset_id}"
user_prompt = f"""
ユーザーから文字起こしアプリSecureMemoCloudに関する質問が与えられます。
テーブルスキーマの情報を元に、ユーザーの質問に対して、BigQueryで実行可能なSQLを生成してください。
# テーブルスキーマ: {self.dbt_schema}
# ユーザーの質問: {user_query}
# BigQuery SQL生成ルール
## 必須制約
- SELECT文のみ生成(DELETE, DROP, UPDATE, INSERT, CREATE等は禁止)
- テーブル・カラム名は提供されたスキーマ定義に厳密に従う
- `{project_dataset_id}`内のテーブルのみ使用
- LIMIT 1000を必ず入れる。SQLインジェクション防止のため。
## 生成方針
- ユーザーの質問意図を理解し、適切なSQLを生成
- 例えば、「XX要約の利用が増えているか知りたい」という質問であれば、
特定の要約だけでなく、全ての要約種類を対象にしたSQLを生成してください。
- 必要最小限の簡潔なクエリを作成
- 必要なカラムのみSELECT(SELECT *は避ける)
# 補足: 現在時刻は、{datetime.now()}です。時刻指定の質問が来た場合は参考にしてください。
# 出力形式(sql)
出力例: (SQL以外の文字列は含めないこと)
SELECT
sample_column,
count(*) as sample_count
FROM {project_dataset_id}.sample_table
WHERE
sample_column = 'sample_value'
GROUP BY
sample_column
ORDER BY
sample_column
LIMIT 1000
"""
return user_prompt
def generate_refine_prompt(self, user_query: str, previous_sql: str | None = None) -> str:
project_dataset_id = f"{self.gcp_project_id}.{self.bq_mart_dataset_id}"
user_prompt = f"""
ユーザーから文字起こしアプリSecureMemoCloudの集計結果に対して、再集計の依頼が来ます。
前の集計結果、および、テーブルスキーマの情報を元に、再集計用のSQL(BigQueryで実行可能なSQL)を生成してください。
# テーブルスキーマ: {self.dbt_schema}
# 前回の集計結果: {previous_sql}
# ユーザーの質問: {user_query}
## 必須制約
- SELECT文のみ生成(DELETE, DROP, UPDATE, INSERT, CREATE等は禁止)
- テーブル・カラム名は提供されたスキーマ定義に厳密に従う
- `{project_dataset_id}`内のテーブルのみ使用
- LIMIT 1000を必ず入れる。SQLインジェクション防止のため。
## 生成方針
- ユーザーの質問意図を理解し、適切なSQLを生成
- 例えば、「XX要約の利用が増えているか知りたい」という質問であれば、
特定の要約だけでなく、全ての要約種類を対象にしたSQLを生成してください。
- 必要最小限の簡潔なクエリを作成
- 必要なカラムのみSELECT(SELECT *は避ける)
# 補足: 現在時刻は、{datetime.now()}です。時刻指定の質問が来た場合は参考にしてください。
# 出力形式(sql)
出力例: (SQL以外の文字列は含めないこと)
SELECT
sample_column,
count(*) as sample_count
FROM {project_dataset_id}.sample_table
WHERE
sample_column = 'sample_value'
GROUP BY
sample_column
ORDER BY
sample_column
LIMIT 1000
"""
return user_prompt
def generate(
self,
user_query: str,
*,
is_refine: bool = False,
previous_sql: str | None = None,
) -> str:
if is_refine:
user_prompt = self.generate_refine_prompt(user_query=user_query, previous_sql=previous_sql)
else:
user_prompt = self.generate_prompt(user_query)
client = OpenAI(api_key=self.openai_api_key)
response = client.chat.completions.create(
model=self.model_name,
messages=[{"role": "user", "content": user_prompt}],
)
response_sql = str(response.choices[0].message.content)
# マークダウンのコードブロックを除去
response_sql = self.clean_response_sql(response_sql)
return response_sql
def clean_response_sql(self, response_sql: str) -> str:
response_sql = response_sql.strip()
if response_sql.startswith("```sql"):
response_sql = response_sql[6:] # "```sql" の6文字を削除
elif response_sql.startswith("```"):
response_sql = response_sql[3:] # "```" の3文字を削除
return response_sql
class ClaudeLLM(LLM):
def __init__(self) -> None:
super().__init__()
self.api_key = self.settings.anthropic_api_key
self.model_name = "claude-sonnet-4-5"
def generate(
self,
user_query: str,
*,
is_refine: bool = False,
previous_sql: str | None = None,
) -> str:
if is_refine:
user_prompt = self.generate_refine_prompt(
user_query=user_query,
previous_sql=previous_sql,
)
else:
user_prompt = self.generate_prompt(user_query)
client = Anthropic(
api_key=self.api_key,
timeout=300,
)
message = client.messages.create(
model=self.model_name,
max_tokens=5000,
messages=[
{
"role": "user",
"content": user_prompt,
}
],
)
text_blocks = [block for block in message.content if hasattr(block, "text")]
response_sql = str(text_blocks[0].text) if text_blocks else ""
response_sql = self.clean_response_sql(response_sql)
return response_sql
プロンプトなどは変更しないため、実質generate関数の処理を定義するだけで大丈夫です。
まとめ
今回は、社内用slack botの開発を通じて、ソフトウェアアーキテクチャを意識した実装の大事さについて共有させていただきました。
案件を通じたアプリケーションの実装をする機会も時々ありますので、保守・運用、変更対応を意識していきたいと思います。
Nishikaについて
Nishikaは2019年に創業、「テクノロジーですべての人が誇りを持てる社会の実現」をビジョンに掲げ、「テクノロジーを、普段テクノロジーからは縁の遠い人にとっても当たり前の存在としていき、皆の仕事の付加価値・業務効率を向上させることに貢献したい」と考え、活動しています。
AIプロダクト事業/AIコンサルティング・開発事業/AI人材事業を手掛け、AIコンサルティング・開発事業では「生成AIを使うと何が嬉しいのか、通り一遍ではない使い方を知りたい」という段階のお客様から、伴走してご支援するアプローチを強みとしています。
We're hiring!
Nishikaテックチームでは、「テクノロジーを、普段テクノロジーからは縁の遠い人にとっても当たり前の存在としていく」を目指し、音声AIプロダクトの開発・生成AIを活用した課題解決ソリューションの構築を行なっています。
興味をお持ちいただけた方は、以下リンクからご応募お待ちしています。インターンも募集しております!
https://info.nishika.com/recruit

Discussion