LLMの出力結果を本番デプロイした後に把握できてますか?
LLMを使うと、さまざまなタスクで60点から70点程度の出力をシュッと出力してくれます。
しかし、アプリケーションで実施するタスクのテストデータを十分に用意できず、あまり良くないと分かっていながらも、やむを得ず手元で試行錯誤したプロンプトを勢いでデプロイしてしまうことも少なくないのではないでしょうか。
それでも、ユーザーの想定外の入力などにも一定レベルの出力ができているかは確認しておきたいですよね。
そんなときにLangfuseがとても便利だったので、今回は運用のイメージと共にコアとなるトレース機能を紹介します。
Langfuseの運用イメージ
サービス上で実施された出力をトレースとして確認。
テストケースとして良さそうサンプルがあればそれを収集。
実験を実行してLLM-as-a-Jdugeで評価。
改善サイクルを回すといったフローができます。
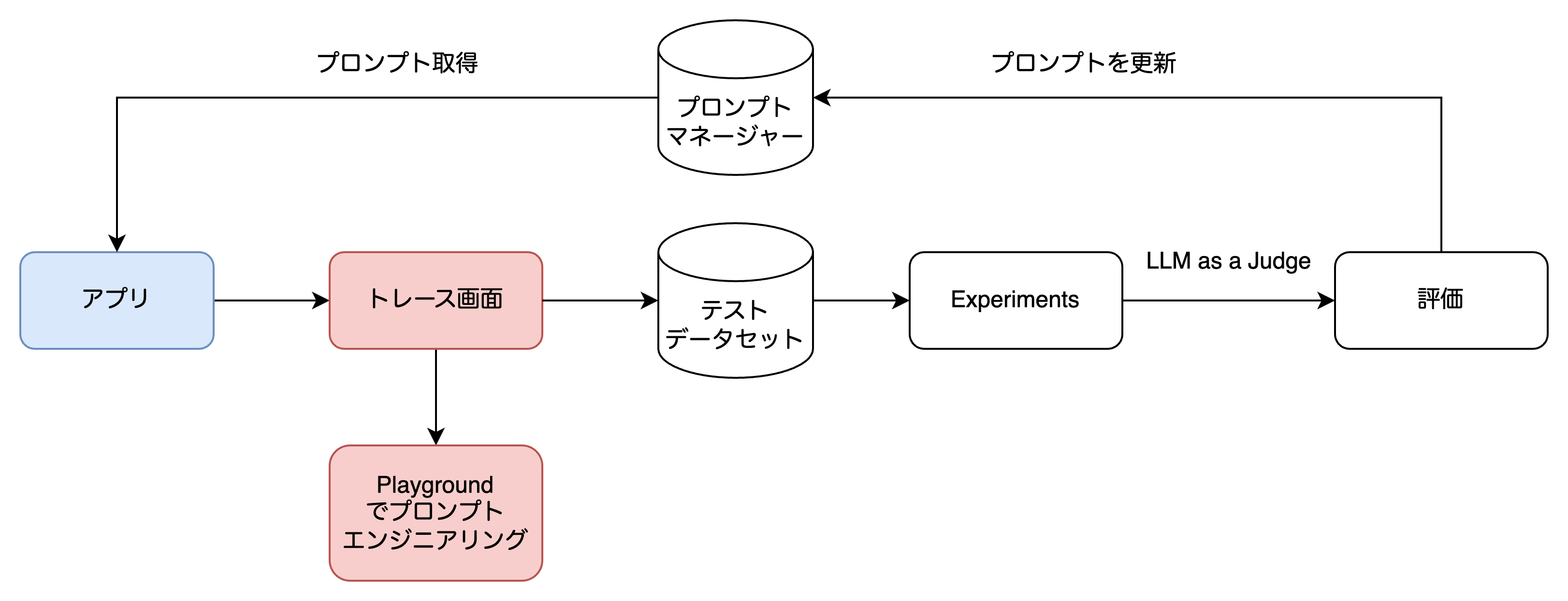
運用イメージ
今回はコアとなるトレースの基本的な運用について紹介できればと思います。
トレース
Langfuseの中心的な機能といっていいでしょう。LLMの入出力結果のログを取ってくれます。
トレース方法はとても簡単で、監視したい関数にデコレーターをつけて、LnagChainであればRunnableにLangfuseのCallbackを追加すればOKです。
@observe #デコレーター追加
def example_func(theme: str) -> str:
llm = ChatOpenAI(model="gpt-4.1-mini")
prompt = ChatPromptTemplate([
("human", "与えられたテーマで俳句を考えて:theme: {theme}"),
])
chain = prompt | llm | StrOutputParser()
# コールバック追加
langfuse_callback = langfuse_context.get_current_langchain_handler()
return chain.invoke({"theme": theme}, config={"callbacks": [langfuse_callback]})
>>> example_func(theme="さくら")
>>> '春風に \n舞い散る花びら \n夢の道'
左側にデコレートした関数内の一連の処理がトレースのツリーとなり、右側に入出力が見れます。
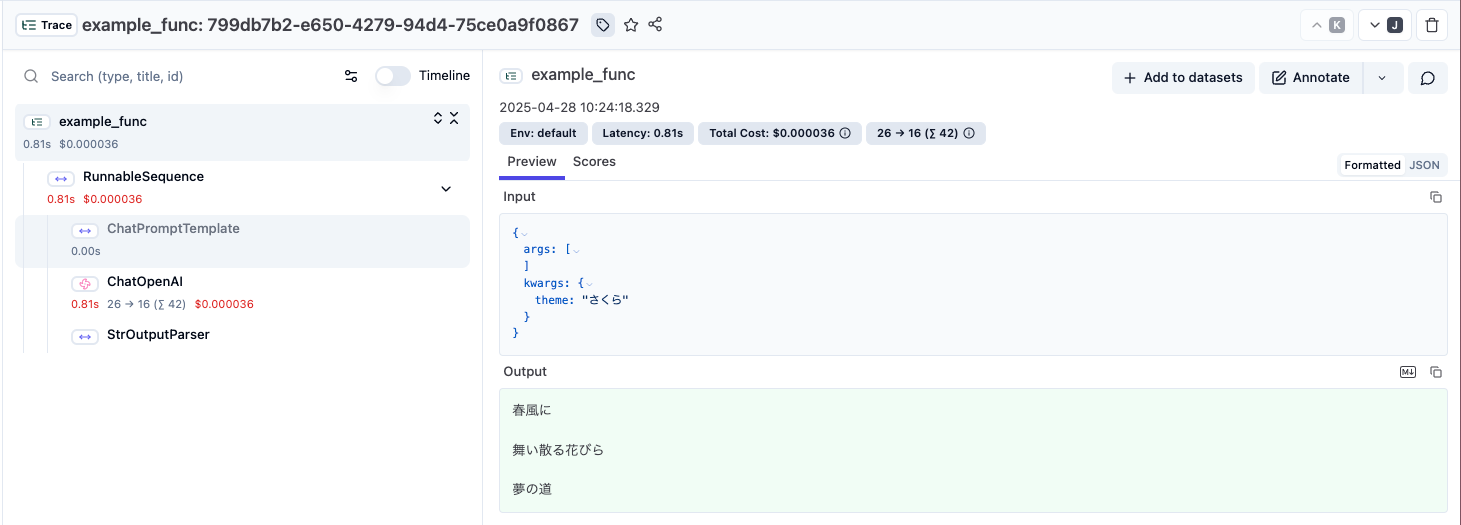
トレース結果
GUIを通してみると視認性が良いですね。
トレースごとにURLがあるのでサッと関係者に出力結果のURLを共有して報告できるのも便利です。
複数のリクエストのトレース
ログが見やすくなるだけ?入出力のログをダンプしておけばいいのでは?私も最初はそう考えていました。トレースが威力を発揮する場面は、複数のリクエストが実行される場面です。
先ほどの関数を同時リクエストしてみましょう。
@observe
def example_concurrent_func(themes: list[str]) -> str:
llm = ChatOpenAI(model="gpt-4.1-mini")
prompt = ChatPromptTemplate([
("human", "与えられたテーマで俳句を考えて:theme: {theme}"),
])
chain = prompt | llm | StrOutputParser()
langfuse_callback = langfuse_context.get_current_langchain_handler()
# バッチでリクエストを並列化
return chain.batch([{"theme": theme} for theme in themes], config={"max_concurrency": 2, "callbacks": [langfuse_callback]})
>>> example_concurrent_func(themes=["桜", "雨", "雪"])
>>> ['春風に \n舞い散る花びら \n夢のよう',
'かしこまりました。雨をテーマにした俳句を詠みます。\n\n---\n\nしずく落つ \n葉先に踊る \n春の雨\n\n---\n\nご希望があれば、季節や雰囲気を変えて別の俳句もお作りします。',
'白き夢 \n枝にふんわり \n雪の花']
一つのトレースツリー内で3回ChatOpenAIがコールされてるのがわかります。
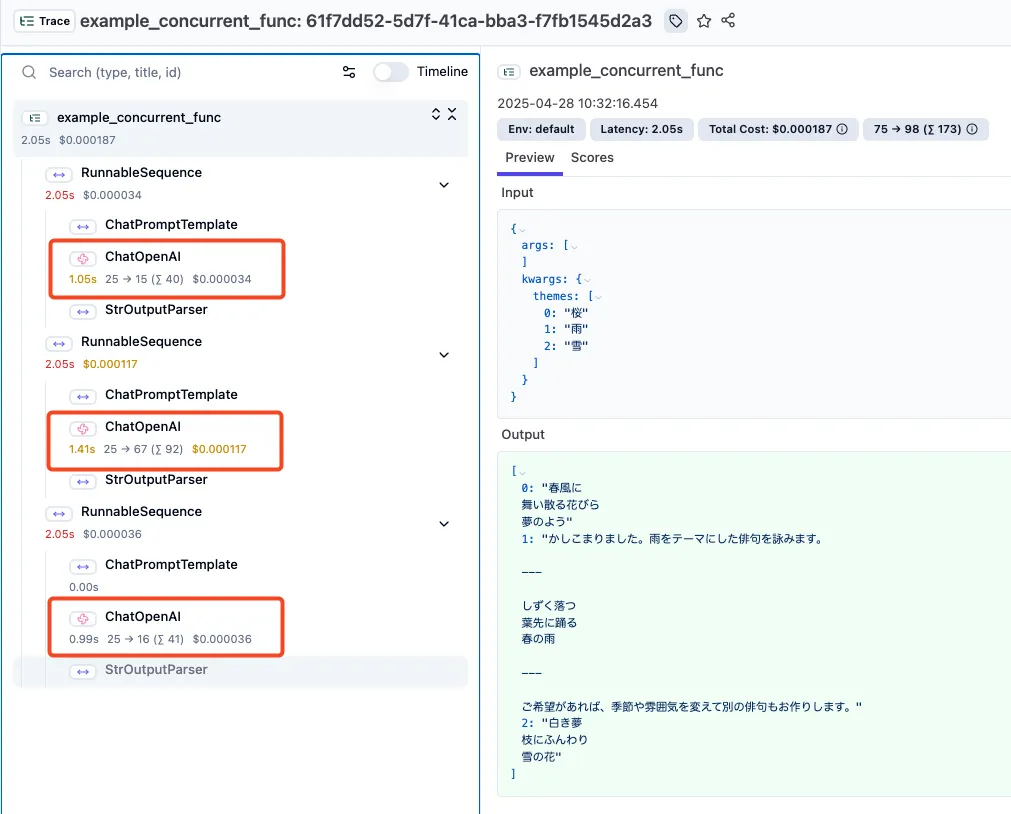
複数回リクエストがあるトレース結果
よくあるユースケースとしては、入力をチャンク化にして並列実行して最後にまとめたり、最近だとAIエージェントなどマルチステップの実行がある場合などで特に便利になります。
ちなみにOpenAI API互換のインターフェースを持っていれば、ローカルのLLMでもトレースしてくれます。なんなら内部の処理がLLMじゃなくてもトレースしてくれます。
トレース結果から行えるアクション
トレース結果から取れる改善へのアクションを2つ紹介します。
トレース結果から入出力をテストデータセットに追加
画面上の操作でトレースの入出力結果をそのままデータセットに追加することができます。
langfuseでトレースを確認=>テストデータとして追加という自然な手順でテストケースを増やせるのでとても便利です[1]。
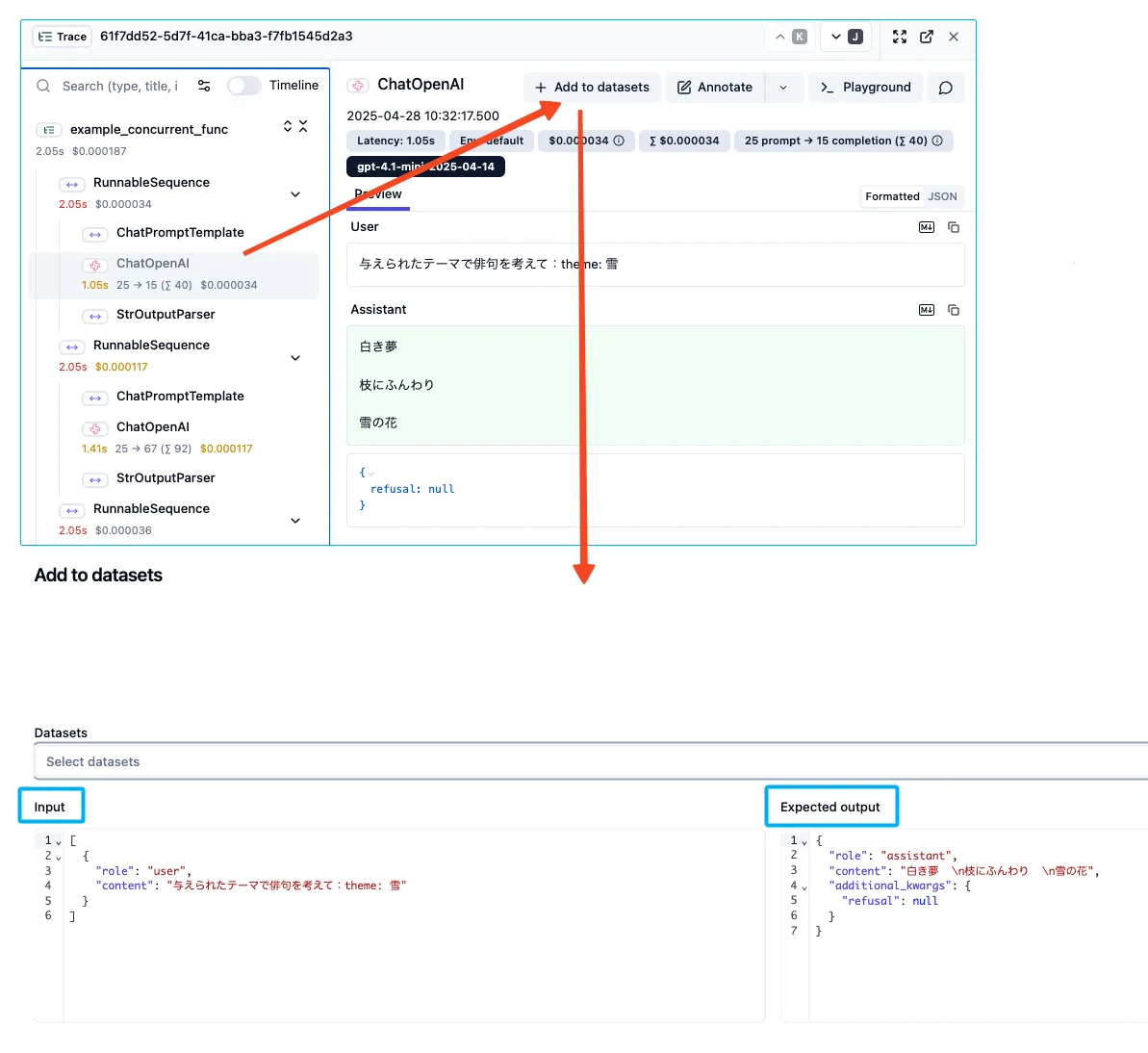
整備したデータセットに対して、LLM-as-a-Judgeなどを用いた評価機能として「Experiments」があります。これにより、Experimentsの評価値を確認しながら改善サイクルを回すことが可能になります。
Experimentsも色々な機能があるので詳しくは別の記事で紹介できればと思います。
トレース結果からPlaygroundでちょっとしたプロンプトの変更を試す
実行時のプロンプトと入力データがセットされた状態でPlayground画面が開きます。
なのでトレース結果を眺めながら、「こういうプロンプトにすると結果はどうなる?」というアイディアを試すのが圧倒的に楽になります。
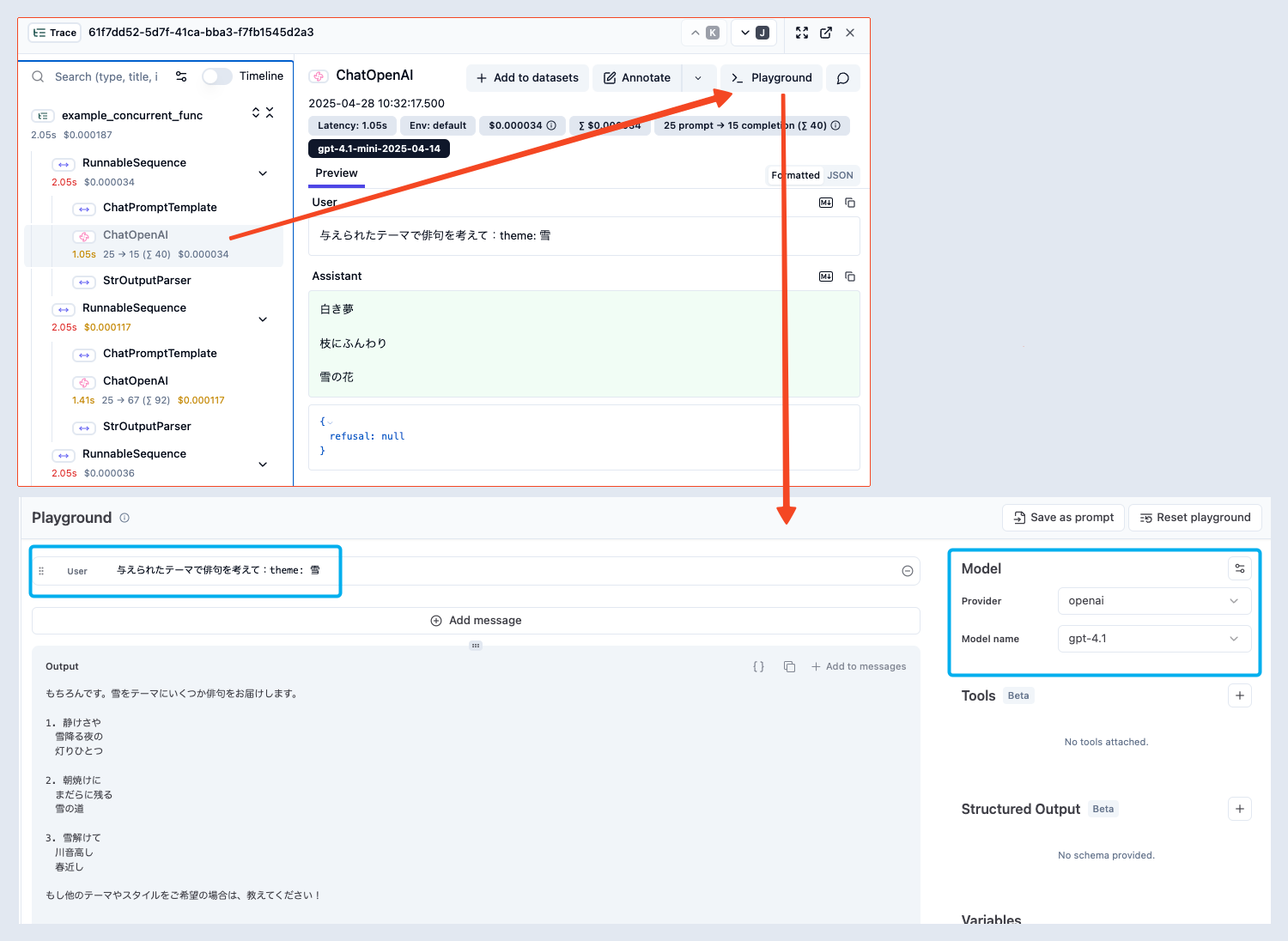
モデルを変更すると性能差なども簡単に把握できる
Playgroundで、トレース結果に対して「どうしてそのような結果を出力しましたか?」というメッセージを追加して実行すると、LLMの思考結果を聞けて改善のアイディアに繋がることもあるので、個人的にお気に入りの使い方です。
Tips
最後に運用時の便利なTipsを紹介します
環境タグ
設定すればステージ(prd、dev、local etc)によってフィルターをかけることが可能になります。環境によってわざわざprojectを分ける必要性がなくなります。
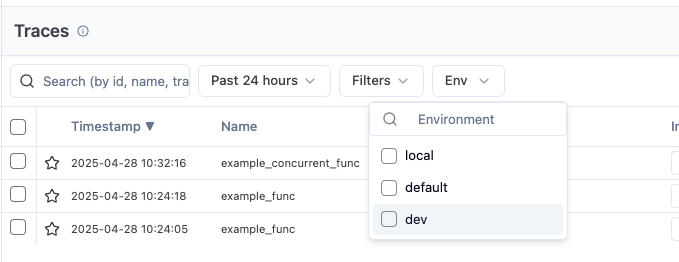
トレースの条件づけ
「dev環境のみトレースして、本番環境ではトレースしない」などの運用もできます。
Langfuse公式の実装にはないので以下のような独自のWrapperを作ってデコレーターを改造しています。
def conditional_observe(func: Callable[P, R]) -> Callable[P, R]:
"""trace_envがprdならトレースのデコレーターを適用しないようにするデコレーター"""
def wrapper(*args: P.args, **kwargs: P.kwargs) -> R:
observe_enabled = kwargs.get("trace_env")
if observe_enabled != "prd":
return observe(func)(*args, **kwargs)
else:
return func(*args, **kwargs)
return wrapper
@conditional_observe
def example_func(theme: str, trace_env="prd") -> str: ...
おわりに
以前、プロンプト管理の記事を書きました
モデルは数ヶ月単位で賢くなっているので、テストデータが十分に用意できない状況では、初期のプロンプトを過度に最適化しても手戻りになる可能性が大きく、トレース重視で実際流れているデータの入出力を元に試行錯誤したほうが効率よく改善サイクルを回せると思いました。
LLMの監視ツールは色々ありますが、Langfuseは課金体型がトレース量なのでチームメンバーにも試用を勧めやすいと思います!ぜひ使ってみてください!
-
入出力のデータ形式がデータセットに合ってないなかったり、画面表示がjson形式で視認性はよくないので、別途streamlitで簡単な整形画面を作ったりしています ↩︎

Discussion