Nishika DSの髙山です。最近は弊社でRAG(Retrieval Augmented Generation:検索拡張生成)をはじめとするLLM関連の相談をいただくことが多く、LangChainでOpen AI APIを使用してStreamlitでサンプルアプリケーションをよく作成しております。
LangChainでベクトルストアを作成する際にはデフォルトでChromaを使用し、LangChainの動作するサーバーにSQLiteのDBが作成されますが、検証用途ではなく商用サービスの場合でベクトルストアを構成する際には、アプリケーションサーバーではなく別途DBサーバーを立てRDBMSに持たせるようにすることが想定されます。
そこでPostgreSQLのベクトル類似性検索の拡張モジュールであるpg_vectorについて調査・検証を行い、複数回の記事で紹介していこうと思います。
今回の記事では、PostgresをベクトルストアとしてStreamlitとLangChainでGPTがナレッジ回答をしてくれるサンプルアプリケーションを作成する流れを紹介します。
pg_vectorとは
pg_vectorはPostgres用の拡張モジュールでオープンソースベクトル類似性検索の機能を持ちます。
Linux, MacではPostgreSQL12以降でサポートされます。
モジュールを有効化することで、正確な近傍探索と近似近傍探索ができ、距離計算としてはL2距離・内積・コサイン距離がサポートされます。
環境構築
検証環境概要
Amazon RDS Postgres15.2以降などのクラウドサービスでもサポートされていてますが、今回はUbuntuにPostgreSQL15を構成します。
使用する環境、ライブラリなどの詳細は以下の通り
- OS: Ubuntu22.04 on WSL2
- DB: PostgreSQL15.6(Ubuntu 15.6-1.pgdg22.04+1)
- Python 3.10.12
- langchain 0.1.6
- pg_vector 0.2.5
- streamlit 1.31.0
今回はRAGのベクトル検索と回答生成にOpen AIのサービスを使用します。アカウントを作成の上APIキーを手元に準備するようにします。
環境構築
PostgreSQL+pg_vectorのセットアップ
- Ubuntu上のリポジトリが古いと、pg_vectorに対応しているPostgresのバージョンをインストールできないためリポジトリを更新します。
- pg_vectorについては、Installation Notesを参考にインストール
# Postgresの公式リポジトリを追加し鍵を取得
$ sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
$ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo tee /etc/apt/trusted.gpg.d/pgdg.asc &>/dev/null
# aptで用意されているPostgreSQLとpg_vectorをインストール
# https://github.com/pgvector/pgvector?tab=readme-ov-file#installation-notes
$ sudo apt install postgresql-15 postgresql-15-pgvector
# postgresqlのサービスを再起動して、activeであることを確認
$ systemctl status postgresql
$ systemctl restart postgresql
$ systemctl status postgresql
DBの作成
- 検証用のDBとしてdb01、その所有ユーザーuser01を作成します。
# postgresユーザにOSユーザを切り替え
$ sudo -u postgres -i
# DB所有用ユーザ作成
$ createuser -d -U postgres -P user01
Enter password for new role:
Enter it again:
$ psql
psql (15.6 (Ubuntu 15.6-1.pgdg22.04+1))
Type "help" for help.
postgres=# alter role postgres with password '{password}';
postgres=# createdb db01 --encoding=UTF-8 --owner=user01
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | ICU Locale | Locale Provider | Access privileges
-----------+----------+----------+---------+---------+------------+-----------------+-----------------------
db01 | user01 | UTF8 | C.UTF-8 | C.UTF-8 | | libc |
postgres | postgres | UTF8 | C.UTF-8 | C.UTF-8 | | libc |
template0 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C.UTF-8 | C.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
(4 rows)
pg_vectorの有効化
- スーパーユーザーであるpostgresユーザーでdb01に接続し、vector extensionを有効化します。
- pg_vectorをインストールすることでpg_available_extensions表にvector extensionが表示されるようになります。
- 管理権限
# db01に接続
postgres=# \c db01
You are now connected to database "db01" as user "postgres".
db01=# SELECT * FROM pg_available_extensions where name like '%vector%';
name | default_version | installed_version | comment
--------+-----------------+-------------------+------------------------------------------------------
vector | 0.6.0 | 0.6.0 | vector data type and ivfflat and hnsw access methods
(1 row)
db01=# create extension vector;
CREATE EXTENSION
# vectorのextensionが有効化されたことを確認
db01=# \dx
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+------------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
vector | 0.6.0 | public | vector data type and ivfflat and hnsw access methods
(2 rows)
db01=#
PostgreSQLでのvector型について
ここまでの作業で以下のようにvector型のカラムを作成することができるようになります。
以下の例はREADMEに記載のものですが、3次元のvector型を宣言し、3次元のベクトルをINSERTしています。
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
PostgreSQLでは深層学習モデル等でベクトルのレコードをinsertする際には、外部のサービス(OpenAI API, Amazon Bedrockなど)を使用します。
vector型では2000次元までサポートされており、2000次元を超える場合は次元削減する必要があります。
LangChainとStreamlitでRAGのアプリを実装する
RAGで参照するデータ
簡単なサンプルデータとして、弊社サービスのSecureMemoのQAのテキスト情報をcsvとして用意します
text
"質問:MyWhipserとの違いは?答え:MyWhisperとSecureMemoの最も大きな違いは、AI話者特定機能になるかと思います。whisperとは異なる独自のAIモデルを搭載しています。
"
質問:SecureMemoは他ソフトと比べて何が良いの?答え:SecureMemoの音声認識の精度は日本で一番の水準でして、他のどの会社様のソフトよりも良い精度になっています。それもあって警察様などに導入いただいています
質問:Whisperを搭載していてオンプレでセキュアに使えるのは御社だけ?答え:SecureMemoのみ
質問:中国語はどうか?答え:中国当局の規制により教師データが少なく、日本語ほどの精度ではない。英語や日本語、スペイン語の精度が高い
RAGの実装
Streamlitアプリから呼び出されるRAGの処理を実装していきます。
詳細についてはGitHubを参照してください。依存関係やOpen AI APIキー・DB情報などの環境変数の設定方法などは本記事では割愛しますが、READMEに記載しております。
- ベクトル化のモデルにはOpenAIのtext-embedding-3-small、回答生成にはGPT3.5 Turboを使用します
- initialize_vector_storeメソッドでPostgreSQL上にベクトルストアを作成
- answerメソッドで質問を入力して、その内容に近いQAをベクトル検索して上位3件を取得し、その内容をプロンプトに追加し、GPT3.5 Turboがプロンプトに対する回答を生成し、回答を返します。
import os
from typing import Dict
import pandas as pd
from dotenv import load_dotenv
from langchain.chat_models import ChatOpenAI
from langchain.docstore.document import Document
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough
from langchain.vectorstores.pgvector import PGVector
from langchain_community.embeddings import OpenAIEmbeddings
load_dotenv()
class RagChain:
COLLECTION_NAME = "test_collection"
DB_DRIVER_DEFAULT = "psycopg2"
DB_HOST_DEFAULT = "localhost"
DB_PORT_DEFAULT = 5432
DB_NAME_DEFAULT = "postgres"
DB_USER_DEFAULT = "postgres"
def __init__(self):
self.df = pd.read_csv("input/securememo_faq.csv")
self.con_str = self.create_connection_string()
self.vector_store = self.initialize_vector_store()
def create_connection_string(self) -> str:
"""
DB接続文字列の作成
Returns:
str: DB接続文字列
"""
driver = os.environ.get("DB_DRIVER", self.DB_DRIVER_DEFAULT)
host = os.environ.get("DB_HOST", self.DB_HOST_DEFAULT)
port = int(os.environ.get("DB_PORT", self.DB_PORT_DEFAULT))
database = os.environ.get("DB_NAME", self.DB_NAME_DEFAULT)
user = os.environ.get("DB_USER", self.DB_USER_DEFAULT)
password = os.environ.get("PASSWORD", "")
return f"postgresql+{driver}://{user}:{password}@{host}:{port}/{database}"
def initialize_vector_store(self):
"""
ベクトルストアの初期化
Returns:
PGVector: ベクトルストア
"""
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
documents = [Document(page_content=text) for text in self.df["text"].to_list()]
# PostgreSQLにベクトルストアを作成
return PGVector.from_documents(
collection_name=self.COLLECTION_NAME,
connection_string=self.con_str,
embedding=embedding,
documents=documents,
pre_delete_collection=True, # 既存のコレクションを削除し、毎回作り直す
)
def answer(self, query: str) -> Dict:
"""
質問に対する回答を返す
Args:
query (str): 質問
Returns:
Dict: 回答
"""
output_parser = StrOutputParser()
model = ChatOpenAI(model="gpt-3.5-turbo-1106", temperature=0)
prompt = ChatPromptTemplate.from_template(
"""
以下のcontextだけに基づいて回答してください。
{context}
質問:
{question}
"""
)
rag_chain_from_docs = RunnablePassthrough() | prompt | model | output_parser
rag_chain_with_source = RunnableParallel(
{"context": self.vector_store.as_retriever(search_kwargs={"k": 3}), "question": RunnablePassthrough()}
).assign(answer=rag_chain_from_docs)
return rag_chain_with_source.invoke(query)
LangChainでのベクトルストア作成について
先に述べた通り、initialize_vector_storeメソッドでPostgreSQL上にベクトルストアを作成しています。
class RagChain:
...(中略)...
def initialize_vector_store(self):
"""
ベクトルストアの初期化
Returns:
PGVector: ベクトルストア
"""
embedding = OpenAIEmbeddings(model="text-embedding-3-small")
documents = [Document(page_content=text) for text in self.df["text"].to_list()]
# PostgreSQLにベクトルストアを作成
return PGVector.from_documents(
collection_name=self.COLLECTION_NAME,
connection_string=self.con_str,
embedding=embedding,
documents=documents,
pre_delete_collection=True, # 既存のコレクションを削除し、毎回作り直す
)
どのような挙動になっているかlangchainの実装を確認すると、langchain_pg_collection表にtest_collectionが作成され、langchain_pg_embedding表にドキュメントのベクトルが追加されています。
db01=# \d langchain_pg_embedding;
Table "public.langchain_pg_embedding"
Column | Type | Collation | Nullable | Default
---------------+-------------------+-----------+----------+---------
collection_id | uuid | | |
embedding | vector | | |
document | character varying | | |
cmetadata | json | | |
custom_id | character varying | | |
uuid | uuid | | not null |
Indexes:
"langchain_pg_embedding_pkey" PRIMARY KEY, btree (uuid)
Foreign-key constraints:
"langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
db01=# \d langchain_pg_collection
Table "public.langchain_pg_collection"
Column | Type | Collation | Nullable | Default
-----------+-------------------+-----------+----------+---------
name | character varying | | |
cmetadata | json | | |
uuid | uuid | | not null |
Indexes:
"langchain_pg_collection_pkey" PRIMARY KEY, btree (uuid)
Referenced by:
TABLE "langchain_pg_embedding" CONSTRAINT "langchain_pg_embedding_collection_id_fkey" FOREIGN KEY (collection_id) REFERENCES langchain_pg_collection(uuid) ON DELETE CASCADE
db01=# select collection_id, document, cmetadata, custom_id, uuid from langchain_pg_embedding;
collection_id | document | cmetadata | custom_id | uuid
--------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------+--------------------------------------+--------------------------------------
af80bdb3-1688-4f3f-b18e-0addee8a9814 | 質問:MyWhipserとの違いは?答え:MyWhisperとSecureMemoの最も大きな違いは、AI話者特定機能になるかと思います。whisperとは異
なる独自のAIモデルを搭載しています。 +| {} | 39b94e7c-d932-11ee-ab48-cf67b834f168 | 95371e93-046d-4866-8b48-74e327ae2880
| | | |
af80bdb3-1688-4f3f-b18e-0addee8a9814 | 質問:SecureMemoは他ソフトと比べて何が良いの?答え:SecureMemoの音声認識の精度は日本で一番の水準でして、他のどの会社様のソフトよりも良い精度になっています。それもあって警察様などに導入いただいています | {} | 39b94e7d-d932-11ee-ab48-cf67b834f168 | 6c785047-260a-4565-add1-3bc3a4c651f2
...
(4 rows)
db01=# select name, cmetadata, uuid from langchain_pg_collection;
name | cmetadata | uuid
------------------+-----------+--------------------------------------
test_collectiion | null | af80bdb3-1688-4f3f-b18e-0addee8a9814
(1 row)
一点注意点としてv0.1.8の実装ではpgvector.pyの218行目でベクトルストア作成時にcreate extenstion vectorを実行してpgvetorを有効化する実装が入っていて、LangChainを使用する際にスーパーユーザーpostgresやDB所有ユーザーなどで実行しないとエラーになります。
よしなに色々な処理をやってくれて、手軽に試しやすいのはLangChainの良いところですが、内部の処理を確認したうえで注意して使用する必要があります。
実運用でベクトルのストアを任意の表に設定して、適切に権限管理を行う上ではLangChainを使わずに別途目的に合わせて実装する必要があると考えられます。
Streamlitアプリの実装
src/chain.pyに実装したベクトルストアを使用し、回答を表示するUIを定義します。
from dataclasses import dataclass
import streamlit as st
from chain import RagChain
@dataclass
class Component:
query: str = st.session_state.get("query", "")
chain = RagChain()
@classmethod
def title(cls):
st.title("ナレッジ検索デモ")
@classmethod
def subtitle(cls):
st.text(
"""
質問について、CSVの内容を踏まえて回答します。
"""
)
@classmethod
def input_inquiry_contents(cls):
with st.form(key="inquiry_form"):
query = st.text_area("問い合わせ内容", "問い合わせ内容を入力してください。" if cls.query == "" else cls.query, height=150)
submit_button = st.form_submit_button("問い合わせ開始")
if submit_button:
with st.spinner("回答作成中"):
response = cls.chain.answer(query)
st.header("問い合わせ結果")
st.markdown("- 問い合わせ内容")
st.write(response["question"])
st.markdown("- 回答内容")
st.write(response["answer"])
for i, document in enumerate(response["context"]):
with st.expander("検索結果" + str(i + 1)):
st.markdown("- 内容")
st.write(document.page_content)
# ===UI===
# タイトル
Component.title()
# サブタイトル
Component.subtitle()
# 問い合わせ入力
Component.input_inquiry_contents()
# ======
Streamlitアプリを起動
Streamlitアプリを実行は以下のコマンドで行います。
$ poetry run streamlit run src/app.py
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.19.239.248:8501
...
WSL上でサンプルアプリを起動しているので、WindowsのブラウザからNetwork URLの方を入力して閲覧します。
質問を入力して「問い合わせ開始」をクリックすると、回答が確認できます。
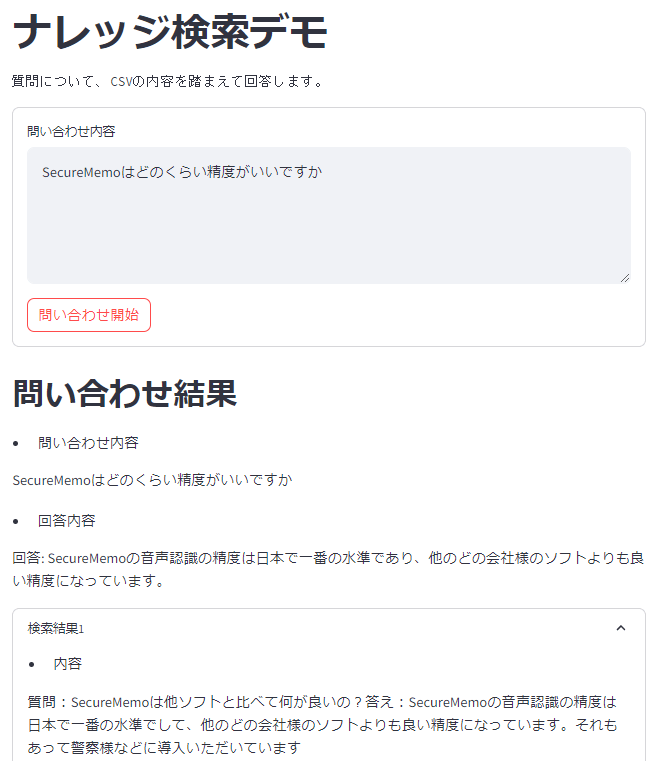
終わりに
今回はPostgreSQL+pg_vectorを構成し、StreamlitとLangChainでRAGを試していきました。pg_vector自体のセットアップは手軽でサンプルアプリの実装もシンプルに行うことができます。
今回はLangChain任せでベクトルストアの作り方や検索方法について深堀をしていないので、今後検証を進めていきたいと思います。
We're hiring!
Nishikaテックチームでは、「テクノロジーを、普段テクノロジーからは縁の遠い人にとっても当たり前の存在としていく」を目指し、音声AIプロダクトの開発・生成AIを活用した課題解決ソリューションの構築を行なっています。
興味をお持ちいただけた方は、以下リンクからご応募お待ちしています。インターンも募集しております!

Discussion