はじめに
この記事はAWS Lambda と Serverless Advent Calendar 2023 のパート2の初日の記事です。
パート2、もっと盛り上がって欲しいな。
概要
社内で利用している管理会計のツール(以下:社内ツール)をLambdaメインで運用しています。
基本的には低コストでの運用ができているのですが、エラーの検知ができておらず、ユーザーからの問合せベースでの対応になっていました。
社内とはいえ、不具合に先に気が付けないのは良くない仕様なので、エラーが発生した場合に気が付ける仕組みの構築を目指して、Lambdaのエラー周りの挙動を整理しました。
結論
LambdaはAPI Gateway、SQS、Step Functionsから実行されており、どれも同期的な呼び出しでした。
非同期的な呼び出しであれば、失敗したときに送信先として別のLambdaやSQS等の後続の処理を呼び出す方法があるのですが、同期的な呼び出しでは失敗時に別の処理を呼び出す処理はありませんでした。
とはいえ、CloudWatch Logsを利用したサブスクリプションフィルターであれば、ログの内容から通知ができるため、timeoutとErrorに絞って設定を行いました。
どのくらいコストがかかるかの感覚がわからないのでいったん一部の関数のみに設定して様子を見てみようと思います。
社内ツール概略
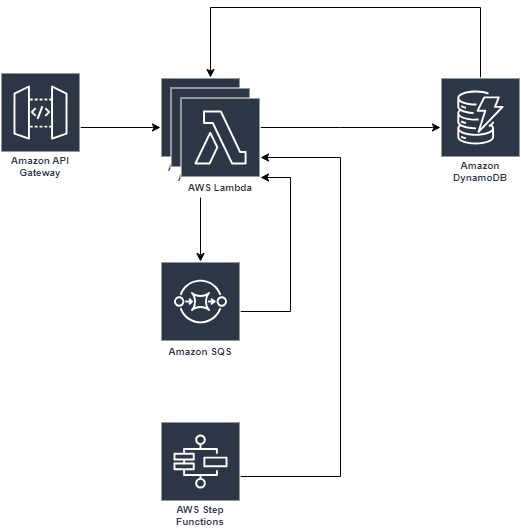
フロントは関係ないので省いていますが、大体は図のようになっています。
WebからのアクセスはAPI Gatewayを経由してLambdaを実行しています。
Lambdaの実行時にSQSやStep Functionsの実行を行います。
永続層はDynamoDBです。
Lambdaで発生しうるエラーについて
基本的には、ドキュメントにまとまっている通りです。
- 一般的な呼び出しエラー
- 一般的な関数エラー
の2つに大きく分かれていますが、呼び出しエラーは権限等で初回の設定時のミスで発生するものが多く、すでに運用しているアプリケーションでは基本的にはあまり発生しないものなので、「一般的な関数エラー」について注目していきます。
呼び出しエラーとは異なり、関数エラーによって Lambda が 400 番台または 500 番台のステータスコードを返すことはありません。関数からエラーが返された場合、Lambda は、X-Amz-Function-Error という名前のヘッダーに加え、エラーメッセージとその他の詳細を含む JSON 形式のレスポンスを含むことでこれを示します。各言語のエラー関数の例については、以下のトピックを参照してください。
となっていますが、API GatewayやLambda 関数 URLを利用すると、いい感じにエラーを伝搬してくれており、httpのレスポンスが502を返します。
Lambda側で設定できる内容の確認
エラーが発生した場合、DLQまたは、送信先を指定することで、後続処理にエラーの通知ができます。
DLQ、送信先は以下のリンクにまとまっていたので参考にしてみてください。
今回の処理では、API Gateway、SQS、Step Functionsはどれも同期的な起動をするため、対象ではありませんでした。
API Gateway、Step Functionsは厳密には、非同期的な呼び出しもできるのですが、その場合は結果を取得するのに一工夫が必要なため、同期的な呼び出しを行っています。
SQSは非同期っぽく思えますが、意外と同期的に呼び出しています。
Lambda はキューをポーリングし、Lambda 関数を、キューメッセージを含むイベントと共に同期的に呼び出します。
DynamoDB Streamも同期的な呼び出しでした。
新しいストリームレコードが利用可能になると、Lambda 関数が同期的に呼び出されます。
以下のようなユースケースに当たる場合は同期的に呼び出しをしているようです。
- 結果を取得したい
- エラーが発生した場合にリトライしたい
エラーを起こしてみる
Lambdaで雑にエラーを発生させてみます。
コードはNode.jsの20.xでの動作を確認しています。
export const handler = async (event) => {
throw new Error("test");
};
レスポンスは以下のようになります。
{
"errorType": "Error",
"errorMessage": "test",
"trace": [
"Error: test",
" at Runtime.handler (file:///var/task/index.mjs:3:9)",
" at Runtime.handleOnceNonStreaming (file:///var/runtime/index.mjs:1173:29)"
]
}
CloudWatch Logsの結果です。
errorTypeやerrorMessageに設定した値が入っているので、エラーの判定に利用できそうです。
START RequestId: b68eaba7-6d84-43c0-8b01-06f00e7db2b0 Version: $LATEST
2023-11-29T14:08:22.978Z b68eaba7-6d84-43c0-8b01-06f00e7db2b0 ERROR Invoke Error {"errorType":"Error","errorMessage":"test","stack":["Error: test"," at Runtime.handler (file:///var/task/index.mjs:3:9)"," at Runtime.handleOnceNonStreaming (file:///var/runtime/index.mjs:1173:29)"]}
END RequestId: b68eaba7-6d84-43c0-8b01-06f00e7db2b0
REPORT RequestId: b68eaba7-6d84-43c0-8b01-06f00e7db2b0 Duration: 87.13 ms Billed Duration: 88 ms Memory Size: 128 MB Max Memory Used: 65 MB Init Duration: 135.49 ms
タイムアウト
エラーではないのですが、厄介なのがタイムアウトです。
該当の社内ツールとしては、Lambdaのタイムアウト以外にも、API GatewayとSQSのタイムアウトを気にする必要があります。
Lambda
指定した秒数を経過しても処理が終了しない場合は、Lambdaを強制終了します。
サンプル
export const handler = async (event) => {
await new Promise((resolve) => setTimeout(resolve, 3000));
};
タイムアウトを1秒にして実行すると、レスポンスは以下のようになります。
{
"errorMessage": "2023-11-29T12:35:40.950Z 5eb7e95d-1083-456b-aea4-4827377d590b Task timed out after 1.00 seconds"
}
CloudWatch Logsの結果です。
Task timed out after あたりが固定の文言なので、検知をしたい場合はこの文字列を取得します。
START RequestId: 5eb7e95d-1083-456b-aea4-4827377d590b Version: $LATEST
2023-11-29T12:35:40.950Z 5eb7e95d-1083-456b-aea4-4827377d590b Task timed out after 1.00 seconds
END RequestId: 5eb7e95d-1083-456b-aea4-4827377d590b
REPORT RequestId: 5eb7e95d-1083-456b-aea4-4827377d590b Duration: 1003.64 ms Billed Duration: 1000 ms Memory Size: 128 MB Max Memory Used: 63 MB Init Duration: 134.28 ms
対応方法
CloudWatch Logsのサブスクリプションフィルターを使って Task timed out の文字列が一致する場合にLambdaを起動するように設定します。
以下の記事等が参考になりました。
API Gateway
API Gatewayは仕様上、29秒でタイムアウトします。この場合、Lambdaはタイムアウトせずに、API Gateway側がレスポンスを待たずに値を返します。
すべての API Gateway 統合で、統合タイムアウトは 29 秒 (ハード制限) です。
この場合はLambdaから検知することはできません。
なので、Lambdaのタイムアウトは29秒にしておくことがいいかと思います。
※ 厳密には、起動時のバッファとかあるので、28秒なのかもしれません
Lambdaのタイムアウトを30秒に設定して試しに実行してみました。
ブラウザからのアクセスは504のステータスを返していて、{"message": "Endpoint request timed out"} と表示されました。
LambdaのCloudWatch Logsは以下のようになっており、タイムアウトはLambda側からはわからないことが確認できました。
INIT_START Runtime Version: nodejs:20.v13 Runtime Version ARN: arn:aws:lambda:ap-northeast-1::runtime:0593533e3a90a967b5685780855b7a89f7ba80b7d910603abf59369c6c4c7331
START RequestId: 78aee2da-437d-4e98-b9c2-585e65cce3d3 Version: $LATEST
END RequestId: 78aee2da-437d-4e98-b9c2-585e65cce3d3
REPORT RequestId: 78aee2da-437d-4e98-b9c2-585e65cce3d3 Duration: 30024.99 ms Billed Duration: 30025 ms Memory Size: 128 MB Max Memory Used: 63 MB Init Duration: 140.35 ms
API GatewayのCloudWatch Logsでは以下のようになっていました。
なお、API GatewayのログレベルのErrors onlyではtimeoutのエラーはログに出力されず、Errors and Info logsの設定をしないと出力されませんでした・
(c1c9cab7-a9b8-495a-b031-412f321827e1) Extended Request Id: PLiGBEjUNjMEU7A=
(c1c9cab7-a9b8-495a-b031-412f321827e1) Verifying Usage Plan for request: c1c9cab7-a9b8-495a-b031-412f321827e1. API Key: API Stage: 01qlq86jxe/staging
(c1c9cab7-a9b8-495a-b031-412f321827e1) API Key authorized because method 'GET //test' does not require API Key. Request will not contribute to throttle or quota limits
(c1c9cab7-a9b8-495a-b031-412f321827e1) Usage Plan check succeeded for API Key and API Stage xxx/staging
(c1c9cab7-a9b8-495a-b031-412f321827e1) Starting execution for request: c1c9cab7-a9b8-495a-b031-412f321827e1
"(c1c9cab7-a9b8-495a-b031-412f321827e1) HTTP Method: GET, Resource Path: /test"
(c1c9cab7-a9b8-495a-b031-412f321827e1) Execution failed due to a timeout error
(c1c9cab7-a9b8-495a-b031-412f321827e1) Method completed with status: 504
API Gatewayのログは現在出力していません。
タイムアウトを検出するためにはInfoに設定する必要がありますが、関係ないログも多数出力されるようになりコストがかかる、Lambda側のタイムアウトを調整すればLambda側で検知できるため、今回は対象外としました。。
なお、Lambdaで直接URLを公開する設定にした場合は30秒を経過してもタイムアウトしませんでした。
SQS
可視性タイムアウトの値を経過してもLambdaが終了していない場合、失敗したとみなして再度実行を行います。
以前のZennの記事で紹介した事例なので、そちらも参照してみてください。
今の運用としては、単純に可視性タイムアウトをすべてのLambdaの起動時間より長めに設定しておけば問題なさそうです。
エラーを検知できるように修正
Lambda内部でのエラーやタイムアウトに対応できれば、監視できそうなことがわかってきたので、設定を行います。
社内ツールはServerless Frameworkで構築しているのですが、まだわからない点が多いので、いったんはコンソールから設定をおこないます。
なお、設定をするにあたってログのストリーミングが発生するため、大量のログを出力している処理の場合は費用が高くなる可能性があります。
ログの設定について
少し前に、Lambdaのログ設定を変更するオプションが追加になりました。
システムログの設定をWARN にすると、起動時等のログは出ないのですが、タイムアウトのログは出力されるので、絞込したい場合は利用してもいいのかもしれません。
{
"time": "2023-11-30T00:35:13.544Z",
"type": "platform.runtimeDone",
"record": {
"requestId": "8ec2aafc-0c83-48dc-b2a3-f3a76e88492b",
"status": "timeout",
"metrics": {
"durationMs": 3003.445,
"producedBytes": 0
}
}
}
なお、ログレベルをWARNに変更した状態で、Lambdaのコンソールからテスト実行すると、CloudWatch Logsには書かれないが、コンソールからはログが見れるという状況になるみたいです。
ログレベルをWARNにして、Lambdaのコンソールから実行した結果として画面にでた内容です。
{"time":"2023-11-30T00:39:47.472Z","type":"platform.start","record":{"requestId":"f25fec20-3b6f-4b82-8977-353211c32be7","version":"$LATEST"}}
{"time":"2023-11-30T00:39:47.572Z","type":"platform.runtimeDone","record":{"requestId":"f25fec20-3b6f-4b82-8977-353211c32be7","status":"success","spans":[{"name":"responseLatency","start":"2023-11-30T00:39:47.472Z","durationMs":40.511},{"name":"responseDuration","start":"2023-11-30T00:39:47.512Z","durationMs":0.068},{"name":"runtimeOverhead","start":"2023-11-30T00:39:47.512Z","durationMs":59.234}],"metrics":{"durationMs":99.981,"producedBytes":50}}}
{"time":"2023-11-30T00:39:47.573Z","type":"platform.report","record":{"requestId":"f25fec20-3b6f-4b82-8977-353211c32be7","status":"success","metrics":{"durationMs":100.371,"billedDurationMs":101,"memorySizeMB":128,"maxMemoryUsedMB":64}}}

サブスクリプションフィルターの設定
Lambdaを作成して、ログの内容を出力するようにします。
実際にはSlackに送信する処理としています。
処理は大体以下のものを流用しています。
import zlib from 'zlib';
export const handler = function(input, context) {
var payload = Buffer.from(input.awslogs.data, 'base64');
zlib.gunzip(payload, function(e, result) {
if (e) {
context.fail(e);
} else {
result = JSON.parse(result.toString());
console.log("Event Data:", JSON.stringify(result, null, 2));
context.succeed();
}
});
};
エラーの検知をしたいロググループを対象にして設定します。
Filter patternは "Task timed out after" とします。
Errorを検知する場合は単純に "Error" で大丈夫です。
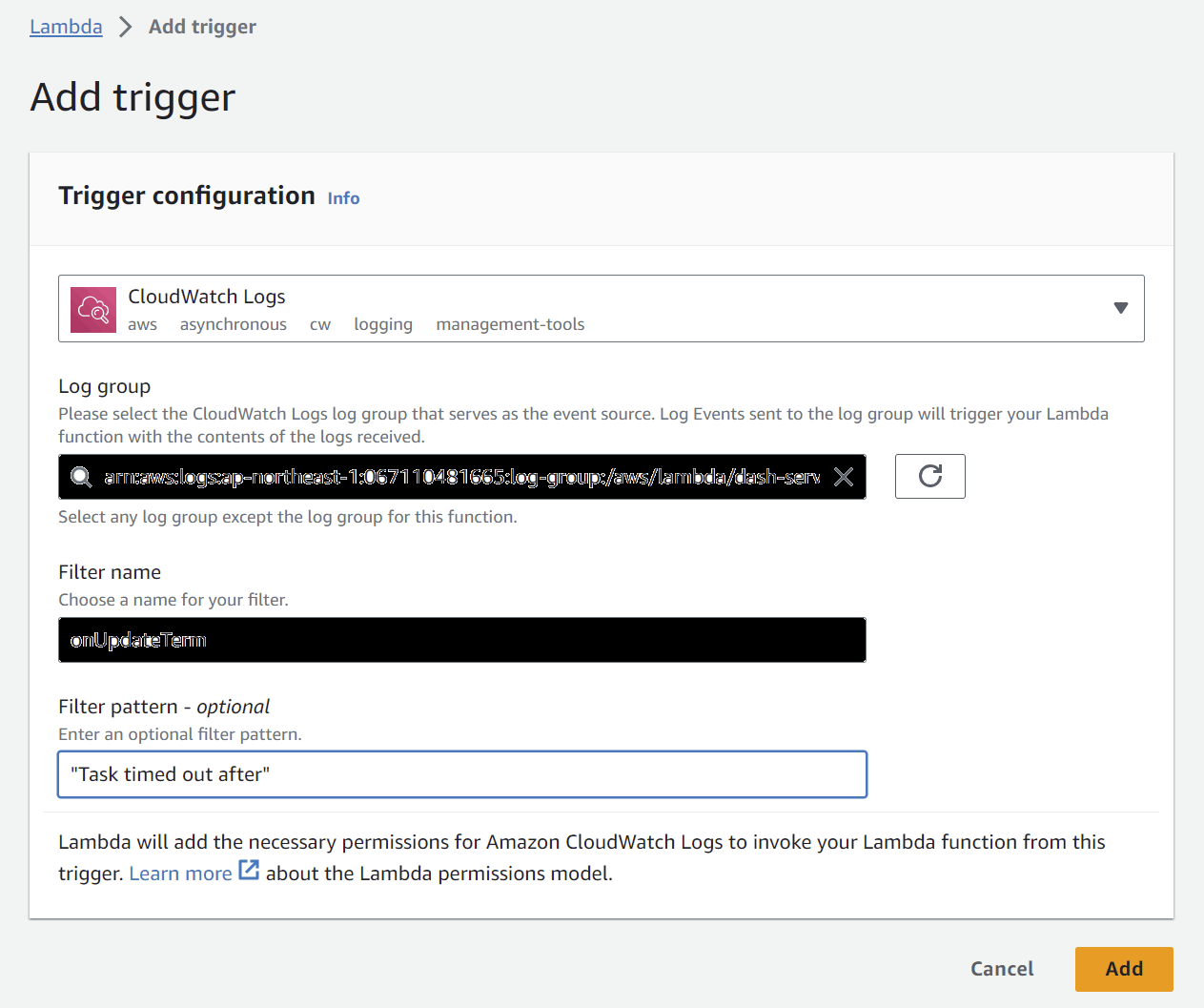
なお、前述のログ設定で出力をJSONに変えた場合は "Task timed out after" ではなく、{ $.record.status = "timeout" }と設定すればうまくいきました。
テストした結果、以下のような結果になりました。
2023-11-30T03:05:39.558Z 6bc64359-a576-4c17-834b-87eca2ce3aa9 INFO Event Data: {
"messageType": "DATA_MESSAGE",
"owner": "067110481665",
"logGroup": "/aws/lambda/xxxx",
"logStream": "2023/11/30/xxxx[$LATEST]6f979b4919d44042aa2d88a07a4eb7e0",
"subscriptionFilters": [
"timeout"
],
"logEvents": [
{
"id": "37940559737900353910336234334802354746440403455946129408",
"timestamp": 1701313539083,
"message": "{\"time\":\"2023-11-30T03:05:39.083Z\",\"type\":\"platform.runtimeDone\",\"record\":{\"requestId\":\"4e229805-a412-48cf-954d-add2baccb0bd\",\"status\":\"timeout\",\"metrics\":{\"durationMs\":3003.353,\"producedBytes\":0}}}"
},
{
"id": "37940559737967256145931826204226961901258348540464070657",
"timestamp": 1701313539086,
"message": "{\"time\":\"2023-11-30T03:05:39.086Z\",\"type\":\"platform.report\",\"record\":{\"requestId\":\"4e229805-a412-48cf-954d-add2baccb0bd\",\"metrics\":{\"durationMs\":3005.532,\"billedDurationMs\":3000,\"memorySizeMB\":128,\"maxMemoryUsedMB\":11},\"status\":\"timeout\"}}"
}
]
}
デフォルトだと、ロググループにLambdaの関数名が入っているので、そこからどの処理がエラーになったのかを判断すればよさそうです。
logEventsのmessageが実際のログの中身なのでparse等をすることで、見やすくなります。
※ timeoutの場合は時間くらいしか判断するものがないですが。。
懸念事項
1つのロググループに対して、設定できるサブスクリプションフィルターは2つまでです。
今回はtimeoutとErrorの2つの設定をしましたが、それ以外に何か検知をしたい場合はそのままではできません。
現状ユースケースはないのですが、追加で見たい要素があった場合は別の実現方法を検討する必要がありそうです。
参考:
まとめ
社内ツールのエラーをチェックする仕組みとして、Lambdaのサブスクリプションフィルターを利用して非同期っぽく検知する仕組みを構築しました。
今回の調査をするまでは、なぜかLambdaのタイムアウトやエラー監視はCloudWatch Alermを利用して行うと思っており、手を出せずにいました。
改めて調査を行うことで、自分の思い込みだったことがわかり、また、想定よりよい手段がみつかったので良かったです。
宣伝
私が所属している株式会社DELTAでは特定の技術にこだわらず、ユーザのニーズに合った提案を行っています。
一緒に働いてくださる仲間を大募集中です!
ご興味をお持ちいただけましたら、私に直接連絡か、お気軽にフォームからご連絡ください。

DELTAは、ベンチャースタートアップなどの成長企業向けに、ソフトウェア・プロダクト開発や技術選定支援などの技術支援事業を提供しています。 また、成長企業向けに様々な事業支援を提供するSEVENRICH GROUPに属して、グループ内の事業会社や、出資先の支援もおこなっています。
Discussion